『心善渊』Selenium3.0基础 — 6、Selenium中使用XPath定位元素
前情提示:在前一篇文章中,我们详细的介绍了XPath路径表达式的使用方式。那么本篇文章我们就来说说在Selenium测试框架中如何使用XPath定位元素。
XPath定位和Selenium基础元素定位方式一样,都可以获取单个元素或者多个元素的结果集。
如下所示:
- 单数定位,获得一个指定元素对象:
driver.find_element_by_xpath("XPath路径表达式") - 复数定位,获得指定元素结果集列表:
driver.find_elements_by_xpath("XPath路径表达式")
1、Selenium中使用XPath查找元素
(1)XPath通过id,name,class属性定位
"""
1.学习目标:
必须掌握selenium中XPath定位方法
2.语法
2.1 selenium中语法
driver.find_element_by_xpath("XPath表达式")
2.2 XPath表达式
相对路径:标签名+属性
//标签名[@属性名='属性值']
3.需求
在百度页面中,使用XPath定位搜索栏
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器(获得浏览器对象)
driver = webdriver.Chrome()
# 3.打开页面
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.用XPath通过id属性定位
"""
注意:@id='kw',等号两边不要有空格
有时候会报错,SyntaxError:(语法错误)
"""
element1 = driver.find_element_by_xpath("//input[@id='kw']")
# 打印定位元素所在行的源码
print(element1.get_attribute("outerHTML"))
# 5.用XPath通过name属性定位
element2 = driver.find_element_by_xpath("//input[@name='wd']")
print(element2.get_attribute("outerHTML"))
# 6.用XPath通过class属性定位
element3 = driver.find_element_by_xpath("//*[@class='s_ipt']")
print(element3.get_attribute("outerHTML"))
# 7.关闭浏览器
driver.quit()
"""
输出结果:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
"""
总结
- 如果不想制定标签名称,可以用
*号表示任意标签。- 有时候同一个属性,同名的比较多,这时候可以通过标签筛选下,定位更准一点。
- 如果想制定具体某个标签,就可以直接写标签名称。
(2)XPath通过标签中的其他属性定位
如果一个元素id,name,class属性都没有,这时候也可以通过其它属性定位到。
# 需求:使用XPath通过其他属性对百度首页搜索框进行定位
# 1.导入selenium
from selenium import webdriver
from time import sleep
# 2.打开浏览器(获得浏览器对象)
driver = webdriver.Chrome()
# 3.打开页面
url = "http://www.baidu.com"
driver.get(url)
sleep(2)
# 4.用XPath通过maxlength属性定位
"""
注意:@id='kw',等号两边不要有空格
有时候会报错,SyntaxError:(语法错误)
"""
element1 = driver.find_element_by_xpath("//input[@maxlength='255']")
# 打印定位元素所在行的源码
print(element1.get_attribute("outerHTML"))
# 5.用XPath通过autocomplete属性定位
element2 = driver.find_element_by_xpath("//input[@autocomplete='off']")
print(element2.get_attribute("outerHTML"))
# 6.关闭浏览器
driver.quit()
"""
输出结果:
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
<input id="kw" name="wd" class="s_ipt" value="" maxlength="255" autocomplete="off">
"""
(3)XPath层级定位
- 如果一个元素,它的属性不是很明显,无法直接定位到,这时候我们可以先找它老爸(父元素)。
- 找到它老爸后,再找下个层级就能定位到了。
- 如下图图所示,要定位的是
input这个标签,它的老爸的class=’s_ipt_wr‘。 - 要是它老爸的属性也不是很明显,就找它爷爷
id=form。 - 于是就可以通过层级关系定位到。
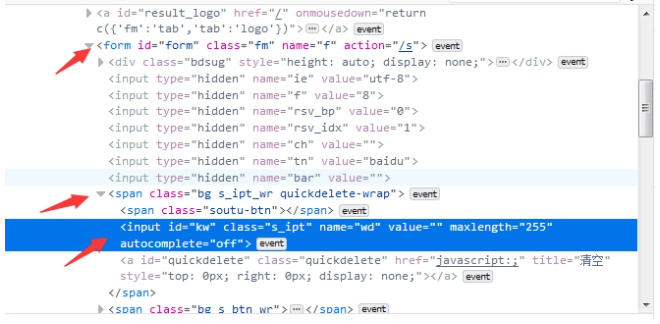
示例:
需求:在页面中,定位下面代码片段中的<input>标签
<p id="p1">
<label for="userA">账号A</label>
<input required="" value="">
</p>
代码脚本:
"""
1.学习目标:
必须掌握selenium中XPath定位方法
2.语法
2.1 selenium中语法
driver.find_element_by_xpath("XPath表达式")
2.2 XPath表达式
层级定位 :
//父标签名[@父标签属性名='属性值']/子标签
注意:最终定位的是子标签
3.需求
在页面中,使用XPath定位上面代码片段的<input>标签
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开注册A页面
url = "file:///" + os.path.abspath("./练习页面/注册A.html")
driver.get(url)
sleep(2)
# 4.XPath层级定位,通过p标签定位字标签input标签
textA = driver.find_element_by_xpath("//p[@id='p1']/input")
print(textA.get_attribute("outerHTML"))
# 6.关闭浏览器
driver.quit()
"""
输出结果:
<input required="" value="">
"""
(4)XPath索引定位
- 如果一个元素它的兄弟元素跟它的标签一样,这时候无法通过层级定位到。因为都是一个父亲生的,多胞胎兄弟。
- 虽然双胞胎兄弟很难识别,但是出生是有先后的,于是可以通过它在家里的排行老几定位到。
- 如下图四胞胎兄弟,可以用XPath定位老大、老二和老三(这里索引是从1开始算起的,跟Python的索引不一样)
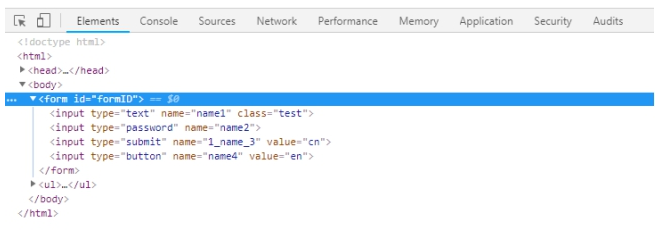
示例:
定位上图代码中的指定input标签。
"""
1.学习目标:
必须掌握selenium中XPath定位方法
2.语法
2.1 selenium中语法
driver.find_element_by_xpath("XPath表达式")
2.2 XPath表达式
相对路径:索引定位元素
//父标签名[@父标签属性名='属性值']/子标签[索引值] 索引从1开始
3.需求
页面中使用XPath索引定位input标签
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "file:///" + os.path.abspath("./练习页面/Test_Xpath.html")
driver.get(url)
# 4.使用xpath索引定位元素
# 定位第一个input标签
# 如果是第一个元素,索引值可以不加。因为不加索引值会选取form下的全部input标签
# 而我们用的是单数定位形式,默认选择第一个。
input_1 = driver.find_element_by_xpath("//form[@id='formID']/input")
print("第一个input标签", input_1.get_attribute("outerHTML"))
# 定位第三个input标签
input_3 = driver.find_element_by_xpath("//form[@id='formID']/input[3]")
print("第三个input标签", input_3.get_attribute("outerHTML"))
# 5.关闭浏览器
sleep(2)
driver.quit()
"""
输出结果:
第一个input标签 <input type="text" name="name1" class="test">
第三个input标签 <input type="submit" name="1_name_3" value="cn">
"""
(5)XPath逻辑定位
在页面元素定位过程中,会出现有一些元素拥有相同的属性和属性值,这个时候就没有办法用一个属性来通过XPath进行定位了。这个时候就需要用多个属性去定位,这就是XPath逻辑定位。
XPath逻辑定位说明:
- XPath还有一个比较强的功能,可以支持与(
and)、或(or)、非(not)。 - 一般用的比较多的是
and运算,同时满足两个属性。
需求:在下面代码片段中,使用XPath逻辑定位test2标签。
<body>
<p id="login_user">
<label for="">test1:</label>
<input type="text" name="user" class="login"/>
</p>
<p id="login_user">
<label for="">test2:</label>
<input type="text" name="user" class="login-test"/>
</p>
</body>
示例:
"""
1.学习目标:
必须掌握selenium中XPath定位方法
2.语法
2.1 selenium中语法
driver.find_element_by_xpath("XPath表达式")
2.2 XPath表达式
相对路径:逻辑定位
//标签名[@属性名1='属性值1'and@属性名2=属性值2]
使用多属性定位元素
3.需求
在页面中使用XPath逻辑定位test2标签
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "file:///" + os.path.abspath("./练习页面/xpath.html")
driver.get(url)
# 4.定位test2输入框使用XPath逻辑定位
test2 = driver.find_element_by_xpath("//input[@type='text'and@name='user'and@class='login-test']")
print(test2.get_attribute("outerHTML"))
# 5.关闭浏览器
sleep(2)
driver.quit()
"""
输出结果:
<input type="text" name="user" class="login-test">
"""
(6)XPath模糊匹配定位
有些标签元素的属性值太长,我们就可以模糊匹配的定位方式来定位目标元素。
掌握了模糊匹配功能,基本上没有定位不到的元素。
需求:定位下面代码片段中的指定元素。
<bookstore id='zc'>
<book id='b1'>
<title lang="eng">Harry Potter</title>
<price>29.99</price>
</book>
<book id='b2'>
<title lang="eng" id="t2">Learning XML</title>
<price>39.95</price>
</book>
<p>
<book id='b3'>
<title lang="eng" id="t3">Learning HTML</title>
<price>99.95</price>
</book>
</p>
</bookstore>
示例:
"""
1..学习目标:
必须掌握selenium中XPath定位方法
2.语法
2.1 selenium中语法
driver.find_element_by_xpath("XPath表达式")
2.2 XPath表达式
相对路径:模糊查询
(1)* : 匹配任何元素节点。
(2)@* : 匹配任何属性节点。
(3)node() : 匹配任何类型的节点。
3.需求
在页面中使用xpath的模糊匹配定位目标元素
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开注册A页面
url = "file:///" + os.path.abspath("./2.html")
driver.get(url)
sleep(2)
# 4.XPath模糊定位
# 4.1 选取 bookstore 元素的所有子元素。
element_1 = driver.find_elements_by_xpath("//bookstore/*")
for element in element_1:
print(element.get_attribute("outerHTML"))
# 4.2 匹配绝对路径最外层元素
element_2 = driver.find_element_by_xpath("/*")
print(element_2.get_attribute("outerHTML"))
# 4.3 选取页面中的所有元素。
element_3 = driver.find_element_by_xpath("//*")
print(element_3.get_attribute("outerHTML"))
# 4.4 选取所有带有属性的 title 元素。
element_4 = driver.find_element_by_xpath("//title[@*]")
print(element_4.get_attribute("outerHTML"))
# 4.5 匹配所有有属性的节点(属性模糊查询使用很少)。
element_5 = driver.find_element_by_xpath("//*[@*]")
print(element_5.get_attribute("outerHTML"))
# 4.6 匹配bookstore节点所有孙子辈的id属性值为t2的title节点
textA = driver.find_element_by_xpath("//bookstore/node()/title[@id='t2']")
print(textA.get_attribute("outerHTML"))
# 5.关闭浏览器
driver.quit()
(7)XPath其他定位方式
代码片段如下:
<html>
<body>
<ul>
<li>咖啡</li>
<li>茶</li>
<li>牛奶</li>
<a rel="milk" href="http://10.106,17.69:8081/food/index.php?m=usc=loginsa=order">
订餐
</a>
</ul>
</body>
</html>
1)contains
contains关键字,是用于模糊查询定位,意思是属性中含有xxx的元素。
内容匹配可以是部分内容,也可以是全部内容。
需求:定位上面代码片段中的<a>标签。
说明:
- 这段代码中的“订餐”这个超链接,没有标准
id元素,只有一个rel和href,不是很好定位。可以使用XPath的模糊匹配模式来定位它。- 寻找页面中
href属性值包含有order这个单词的所有a元素,由于这个“订餐”按钮的href属性里肯定会包含order,所以这种方式是可行的,也会经常用到。其中@后面可以跟该元素任意的属性名。
示例:
"""
1..学习目标:
必须掌握selenium中XPath定位方法
2.语法
2.1 selenium中语法
driver.find_element_by_xpath("XPath表达式")
2.2 XPath表达式
相对路径:模糊查询定位
需要使用contains关键字(包含)
格式://标签名[contains(@属性名,部分属性值)]
应用:一般适用于id,name,class是动态的情况下
3.需求
在页面中使用XPath的模糊匹配定位<a>标签
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "file:///" + os.path.abspath("./123.html")
driver.get(url)
# 4.使用xpath模糊匹配,使用contains
button = driver.find_element_by_xpath("//a[contains(@href, 'order')]")
print(button.get_attribute("outerHTML"))
# 5.关闭浏览器
sleep(2)
driver.quit()
2)starts-with
搜索元素属性值以什么开头进行模糊定位。
示例:
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开页面
url = "file:///" + os.path.abspath("./123.html")
driver.get(url)
# 4.使用xpath模糊匹配,使用starts-with
"""
寻找rel属性以mi开头的a元素。
其中@后面的rel可以替换成元素的任意其他属性。
"""
button = driver.find_element_by_xpath("//a[starts-with(@rel, 'mi')]")
print(button.get_attribute("outerHTML"))
# 5.关闭浏览器
sleep(2)
driver.quit()
3)Text
直接查找页面中所有的“茶”字,根本就不用知道它是个<li>元素。这种方法也经常用于纯文字的查找。
示例:
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开注册A页面
url = "file:///" + os.path.abspath("./123.html")
driver.get(url)
# 4.xpath定位,使用text方法
button = driver.find_element_by_xpath("//*[text()='茶']")
print(button.get_attribute("outerHTML"))
# 5.关闭浏览器
sleep(2)
driver.quit()
"""
输出结果:
<li>茶</li>
"""
4)|连结符
通过在路径表达式中使用|运算符,可以选取若干路径中所匹配标签的结果集。
例如:
//p|//*[@id="fun"]:表示将选择所有p和id="fun"的标签元素。//a|//p|//div:表示将选择所有a,p与div标签元素。
示例:
"""
1..学习目标:
必须掌握selenium中XPath定位方法
2.语法
2.1 selenium中语法
driver.find_element_by_xpath("XPath表达式")
2.2 XPath表达式
相对路径:| 连结符用法
通过在路径表达式中使用 | 运算符,可以选取若干路径中所匹配标签的结果集。
3.需求
在页面中使用xpath的 | 连结符,匹配定位目标元素
"""
# 1.导入selenium
from selenium import webdriver
from time import sleep
import os
# 2.打开浏览器
driver = webdriver.Chrome()
# 3.打开注册A页面
url = "file:///" + os.path.abspath("./123.html")
driver.get(url)
sleep(2)
# 4.XPath中 | 连结符 定位
# 4.1 选取茶所在的<li>标签和<a>标签
element_1 = driver.find_elements_by_xpath("//li[last()-1] | //a")
for element in element_1:
print(element.get_attribute("outerHTML"))
# 5.关闭浏览器
driver.quit()
"""
输出结果:
<li>茶</li>
<a rel="milk" href="http://10.106,17.69:8081/food/index.php?m=usc=loginsa=order">
订餐
</a>
"""
2、总结:
这里指做了一些最常用的XPath定位方式的练习。如果在工作中有需要用到一些特别的用法,可以查看XPath的文档。
提示:XPath的文档地址:http://www.w3school.com.cn/xpath/index.asp。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号