基于ConcurrentMap锁机制的NFS文件合并方案
我们在前面已经介绍 《基于ConcurrentMap锁机制的NFS分片上传方案》,今天把上传后的分片文件进行合并。先给大家发一个设计流程图
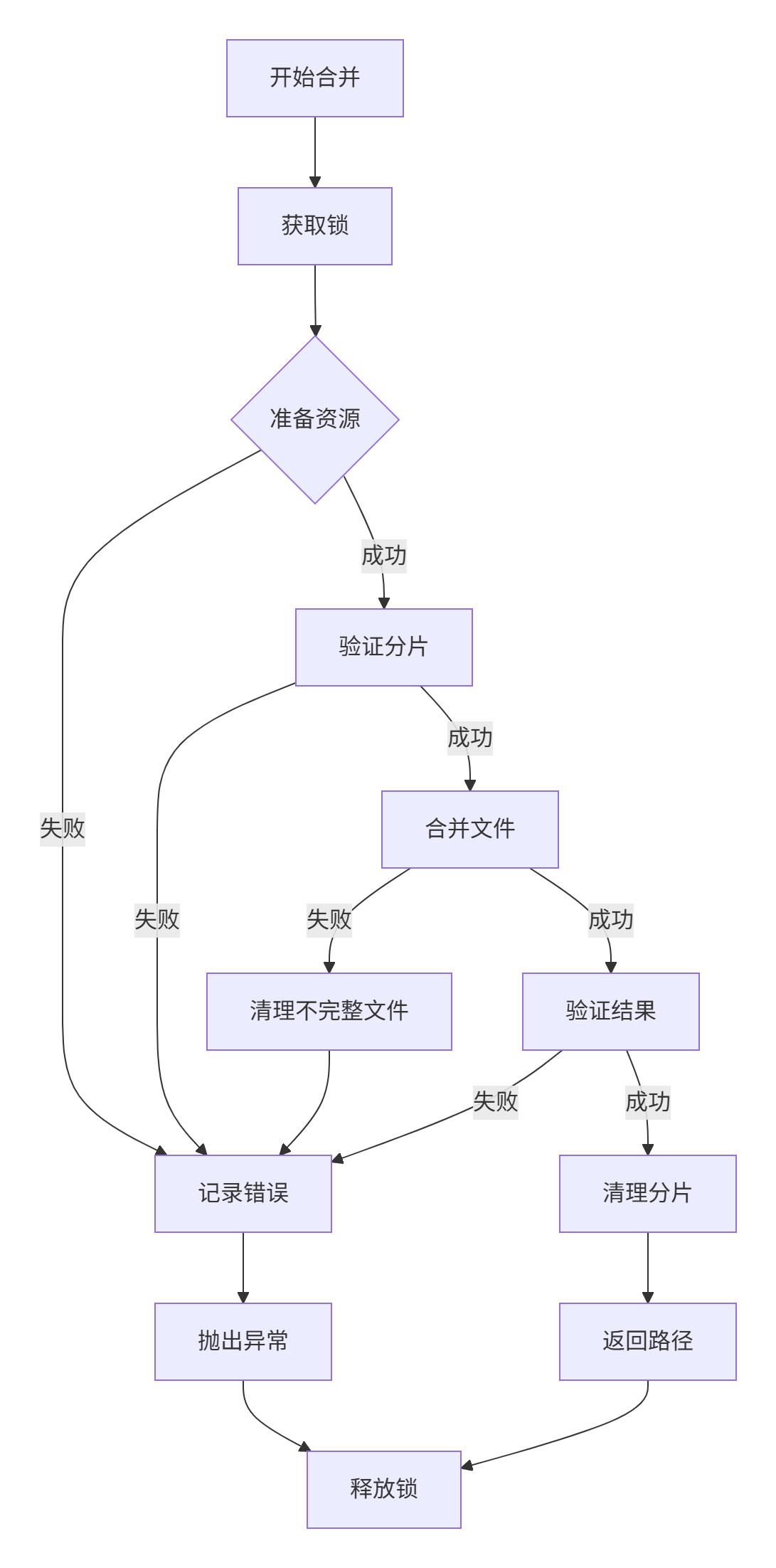
需要关键的vo类:Chunk(分片文件) 和 FileInfo(合并文件)
import org.springframework.web.multipart.MultipartFile;
import java.io.Serializable;
public class Chunk implements Serializable {
private MultipartFile file;
private Long id;
/**
* 当前文件块,从1开始
*/
private Integer chunkNumber;
/**
* 分块大小
*/
private Long chunkSize;
/**
* 当前分块大小
*/
private Long currentChunkSize;
/**
* 总大小
*/
private Long totalSize;
/**
* 文件标识
*/
private String identifier;
/**
* 文件名
*/
private String filename;
/**
* 相对路径
*/
private String relativePath;
/**
* 总块数
*/
private Integer totalChunks;
/**
* 文件类型
*/
private String type;
}import java.io.Serializable;
public class FileInfo implements Serializable {
private Long id;
private String filename;
private String identifier;
private Long totalSize;
private String type;
private String location;
}代码设计关键步骤
- 初始化NFS客户端
- 给文件路径上锁
- 简单用UUID方式生成合并后的文件名
- 获取上传后的分片文件,并进行分片排序【重要】
- try-with-resouces进行文件合并操作
- 清理分片目录
public Map<String,String> mergeFiles(FileInfo fileInfo) throws IOException {
Nfs3 nfs = null;
String identifier = fileInfo.getIdentifier();
Map<String,String> result = new HashMap<>();
try {
// 初始化NFS客户端并构建路径
nfs = getNfsClient();
Object mergeLock = MERGE_LOCK_MAP.computeIfAbsent(identifier, k -> new Object());
synchronized (mergeLock) {
// 准备目录路径
String[] chunkDirPath = {CHUNK_DIR, identifier};
Nfs3File chunkDir = new Nfs3File(nfs, "/"); // 无论NFS_DIR末尾带不带/,这里开头必须/,否者堆栈溢出
// NFS路径规范
// NFS客户端要求每次只操作单级路径
// 当使用new Nfs3File(parent, child)时,child应该是单级目录名(如"chunks"),而不是多级路径(如"chunks/identifier")
for (String dir : chunkDirPath) {
chunkDir = new Nfs3File(chunkDir, dir);
}
Nfs3File outputDir = new Nfs3File(nfs, "/"); // 无论NFS_DIR末尾带不带/,这里开头必须/,否者堆栈溢出
//outputDir = new Nfs3File(outputDir, MERGED_DIR); // 创建合并子目录
// ensureDirExists(outputDir);
// 创建合并目标文件
// 生成文件UUID名称用于存储
String uuid = UUID.randomUUID().toString().replace("-", "");
String fileName = fileInfo.getFilename();
String ext = fileName.substring(fileName.lastIndexOf("."));
String nfileName = uuid + ext;
Nfs3File mergedFile = new Nfs3File(outputDir, nfileName);
// 获取排序后的分片列表
List<Nfs3File> sortedChunks = getSortedChunks(chunkDir);
// 合并分片内容
try (OutputStream output = new NfsFileOutputStream(mergedFile)) {
for (Nfs3File chunk : sortedChunks) {
// 4.1 验证分片有效性
if (!chunk.exists()) {
throw new IOException("分片文件不存在: " + chunk.getPath());
}
// 4.2 流式复制分片内容
try (InputStream input = new NfsFileInputStream(chunk)) {
byte[] buffer = new byte[1024 * 1024]; // 1MB缓冲区提升性能
int bytesRead;
while ((bytesRead = input.read(buffer)) != -1) {
output.write(buffer, 0, bytesRead);
}
}
}
}
// 清理分片目录
deleteRecursively(chunkDir); // 调用自定义递归删除
// 6. 验证合并结果
if (!mergedFile.exists()) {
throw new IOException("合并文件创建失败: " + mergedFile.getPath());
}
// return MERGED_DIR + "/" + nfileName;
result.put("videoPath", BASE_PATH + "/" + nfileName);
result.put("videoUploadName", nfileName);
result.put("fileName", fileInfo.getFilename());
return result;
}
} finally {
if (nfs != null) nfs = null; // 清理资源
// 移除锁(允许后续重试)
MERGE_LOCK_MAP.remove(identifier);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号