

102302104刘璇-数据采集与融合技术实践作业2
作业1:
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
输出信息:Gitee文件夹链接
核心代码设计逻辑:
模拟浏览器访问天气网站,获取北京7天天气预报页面;用BeautifulSoup解析HTML,找到包含天气数据的列表项;从每个天气条目中提取日期、天气状况和温度信息;把提取的数据清洗整理后存入SQLite数据库


核心代码:
点击查看代码
for li in lis:
try:
date=li.select_one('h1').text #日期,h1标签
weather=li.select_one('p.wea').text #天气状况,p.wea
tem_p=li.select_one('p.tem') #温度,span标签
tem_span=tem_p.select_one('span') #白天温度
tem_i=tem_p.select_one('i').text #夜间温度
temp=f"{tem_span.text}/{tem_i}" if tem_span else tem_i #拼接温度
print(f"{date} {weather} {temp}")
运行结果:
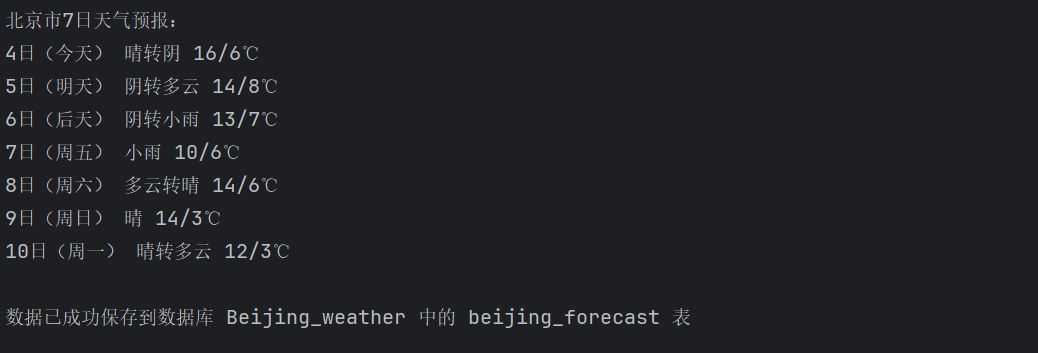

Gitee文件夹链接:https://gitee.com/liuxuannn/data-acquistion-and-fusion-practice_-project1/blob/master/作业2/2.1.py
心得体会:
温度数据拼接时要注意格式统一,避免因数据缺失导致报错。存储的数据库文件不能直接打开,数据库文件为二进制,故利用DB Browser连接文件再查看才不会乱码。
作业2:
要求–用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。东方财富网:https://www.eastmoney.com/
输出信息:Gitee文件夹链接
核心代码设计逻辑:
通过参数控制分页和返回字段,使用requests发送HTTP请求,从JSONP格式中提取纯JSON数据,将API返回的字段映射到数据库表字段,批量插入SQLite数据库,查询数据结果。


核心代码:
点击查看代码
#数据爬取函数
response=requests.get(url)
response.raise_for_status()
json_data=response.text[response.text.find("{"):response.text.rfind("}") + 1]
data=json.loads(json_data)
if "data" in data and "diff" in data["data"]:
return data["data"]["diff"]
#数据存储函数
def save_to_database(stock_list):
conn=sqlite3.connect("stock_database.db")
cursor=conn.cursor()
#创建表
cursor.execute('''
CREATE TABLE IF NOT EXISTS stock_info (...)
''')
#插入数据
for stock in stock_list:
cursor.execute('''
INSERT INTO stock_info VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (stock.get("f12", ""), stock.get("f14", ""), ...))
conn.commit()
运行结果:



Gitee文件夹链接:https://gitee.com/liuxuannn/data-acquistion-and-fusion-practice_-project1/blob/master/作业2/2.2.py
心得体会:
直接json.loads()会报错,必须精确截取{到}之间的内容。有次漏了+1就少了个括号,解析一直失败。
作业3:
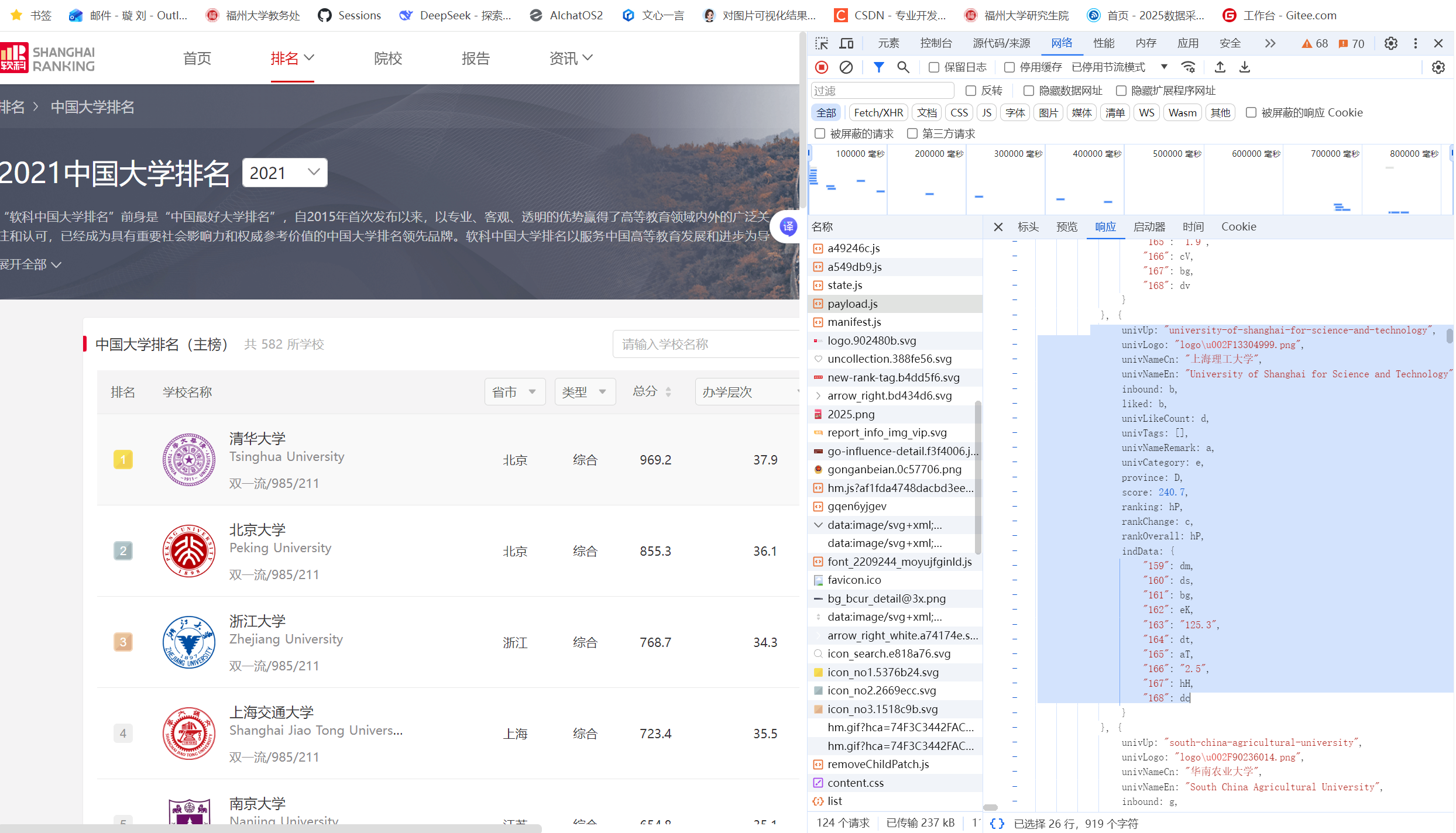
要求:–爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
输出信息: Gitee文件夹链接
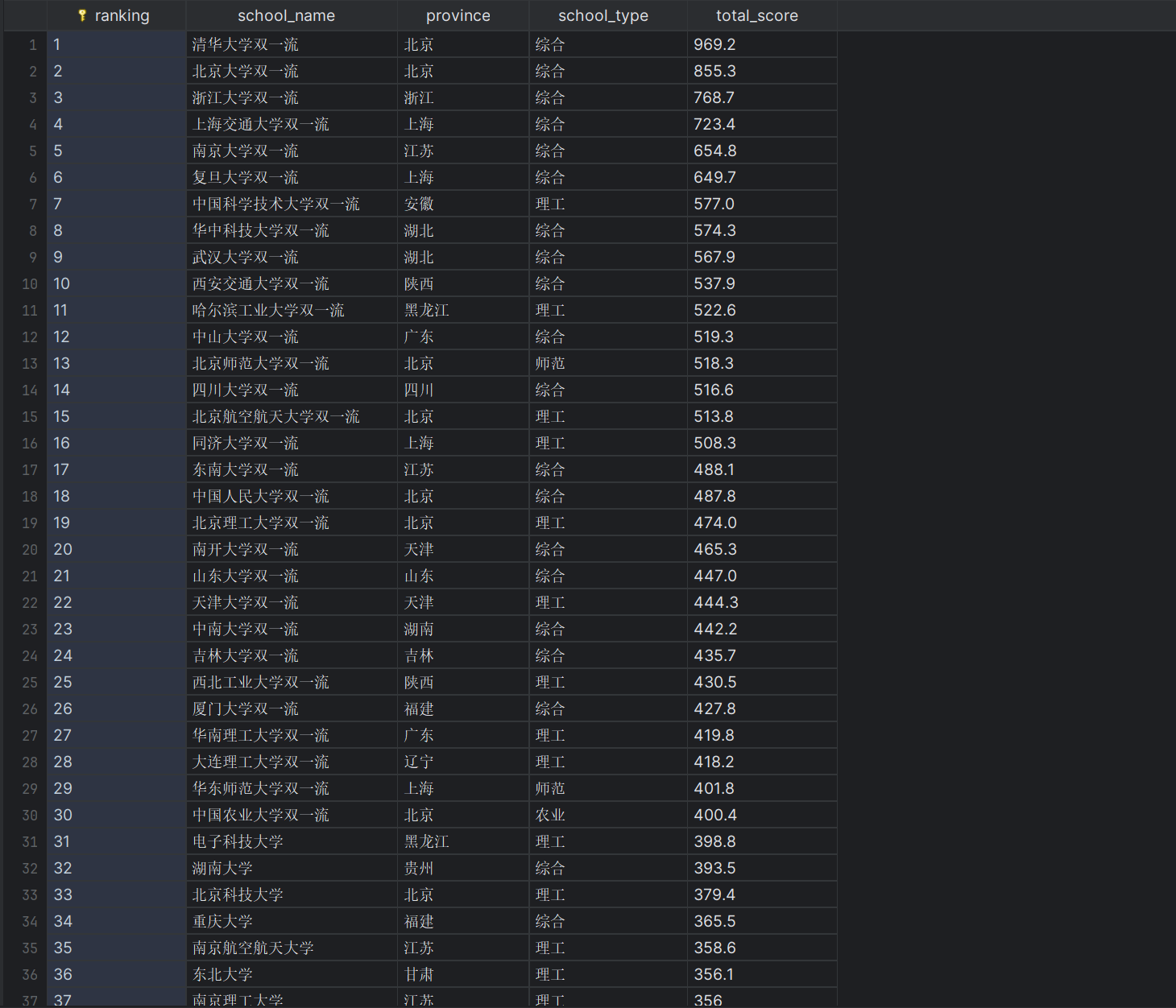
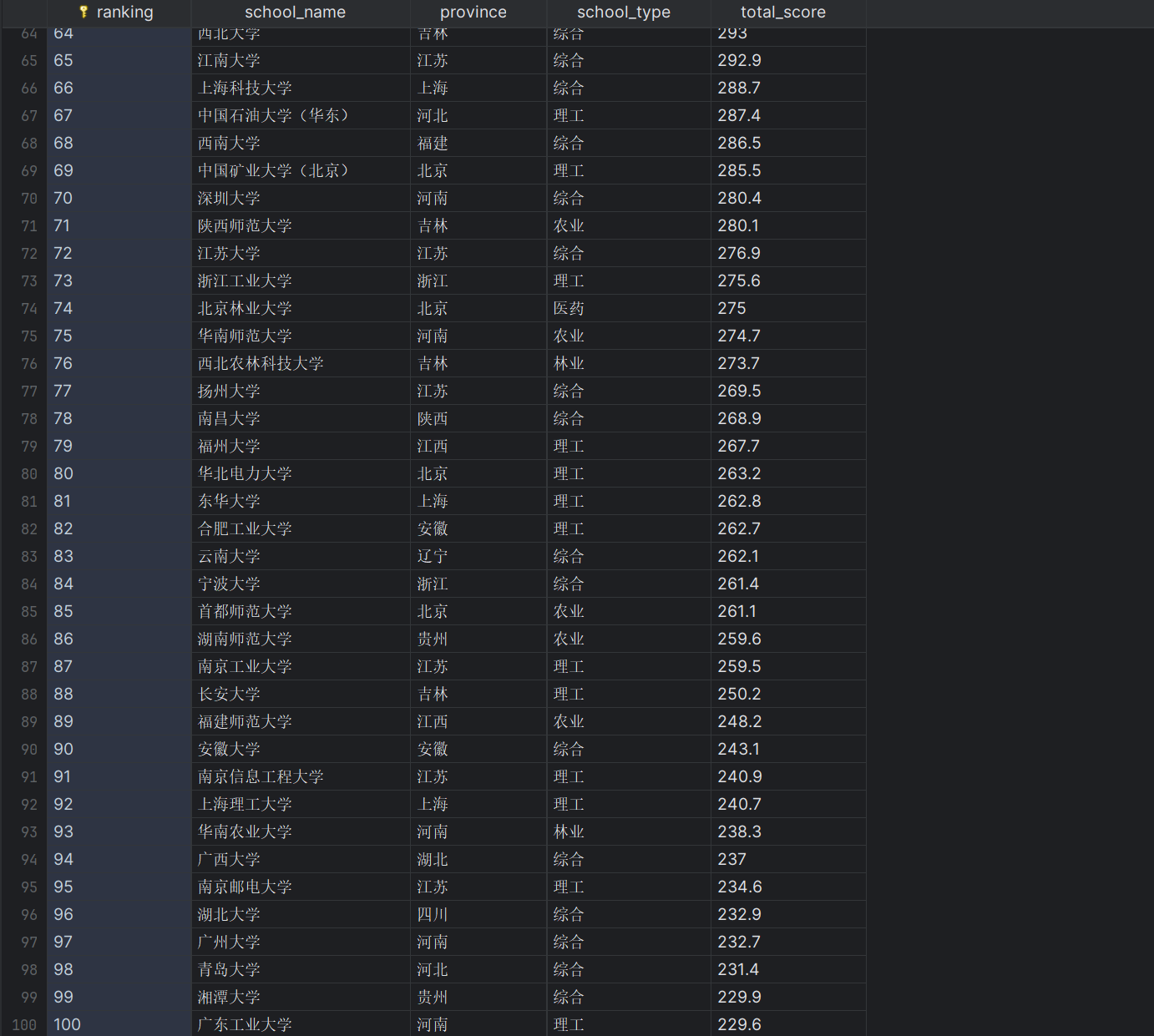
| 排名 | 学校 | 省市 | 类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 969.2 |
核心代码设计逻辑:
通过直接下载包含原始数据的js文件,利用正则表达式提取其中的大学信息,并通过js文件最后部分的变量映射将压缩的变量名转换为可读的中文名称,再将结构化信息存储到SQLite数据库中。
核心代码:
点击查看代码
def crawl_university_ranking_from_js():
js_url="https://www.shanghairanking.cn/_nuxt/static/1762223212/rankings/bcur/2021/payload.js"
#发送HTTP请求获取JS文件
req=urllib.request.Request(js_url)
with urllib.request.urlopen(req) as response:
js_content=response.read().decode('utf-8')
#变量映射表
variable_mapping={
'e': '理工', 'f': '综合', 'g': '师范', 'h': '农业',
'm': '林业', 'S': '医药',
'q': '北京', 'D': '上海', 'x': '浙江', 'k': '江苏',
# ... 更多映射
}
all_schools=[]
#核心正则表达式匹配
pattern = r'univNameCn:"([^"]+)".*?univCategory:([a-zA-Z0-9_$]+).*?province:([a-zA-Z0-9_$]+).*?score:([\d.]+)'
matches = re.findall(pattern, js_content, re.DOTALL)
#数据处理和转换
for i, match in enumerate(matches, 1):
school_name, category_var, province_var, score = match
#变量名转换为实际意义
province = variable_mapping.get(province_var, province_var)
category = variable_mapping.get(category_var, category_var)
#构建数据结构
all_schools.append({
'排名': str(i),
'学校名称': school_name,
'省市': province,
'类型': category,
'总分': score
})
return all_schools
运行结果:



 浙公网安备 33010602011771号
浙公网安备 33010602011771号