

102302104刘璇-数据采集与融合技术实践作业1
作业1:
要求:用requests和BeautifulSoup库方法定向爬取给定网站(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2 | .... | .... | .... | .... |
核心代码设计逻辑:
基于对网页结构的观察,首先我注意到目标数据以表格形式规整地呈现在网页上,这让我决定采用分层提取的策略即从定位整个表格开始,逐步深入到行和单元格的层面。在数据清洗的时候,我发现学校名称字段中混杂了数字和特殊字符,所以我使用正则表达式来精准提取中文字符。
核心代码:
点击查看代码
def crawl_university_ranking():
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
response = requests.get(url, timeout=10)
soup = BeautifulSoup(response.text, "html.parser")
table = soup.find("table", class_="rk-table")
data_rows = table.find("tbody").find_all("tr")[:30]
for row in data_rows:
cols = row.find_all("td")[:5]
rank = cols[0].get_text(strip=True)
school_name = re.sub(r'[^\u4e00-\u9fa5]', '', cols[1].get_text(strip=True))
province = cols[2].get_text(strip=True)
school_type = cols[3].get_text(strip=True)
total_score = cols[4].get_text(strip=True)
print(f"{rank}\t{school_name}\t{province}\t{school_type}\t{total_score}")
if __name__ == "__main__":
crawl_university_ranking()
运行结果:

心得体会:
首先在数据提取阶段,我发现学校名称字段中混杂了各类非中文字符,所以我采用正则表达式精准过滤出纯中文内容,由于中英文字符宽度差异,简单的制表符无法实现完美的列对齐,经过反复试验格式化字符串的宽度参数,才找到各列最合适的显示比例。在最开始写完运行的时候,当网页结构发生微小变动时,程序就会直接崩溃。所以后续我为每个DOM查询操作都添加了健壮性检查,确保在页面结构发生变化时能够优雅降级而非彻底失效。
作业2:
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2 | .... | .... |
核心代码设计逻辑:
写这个爬虫的时候,首先我观察了当当网的页面结构,发现商品名称都包含在title属性里,而且搜索"书包"的结果页面中,所有相关商品的title都带有"书包"这个关键词,所以可以直接用正则匹配包含"书包"的title就能精准抓取到商品名称。对于价格提取,我注意到页面里价格都有统一的CSS类名price_n,而且价格格式很规范,都是¥后面跟着数字,这样就可以直接爬取出来价格了。且根据网页可以看出名称和价格在页面中的出现顺序是对应的,所以直接用zip配对就能保持数据的一致性,不需要复杂的映射关系。
核心代码:
点击查看代码
def crawl_dangdang():
url = "https://search.dangdang.com/?key=书包&act=input"
response = urllib3.PoolManager().request('GET', url)
html = response.data.decode('gbk')
#提取商品名称和价格
names = re.findall(r'title="([^"]*书包[^"]*)"', html)
names = [name.strip() for name in names][:60]
prices = re.findall(r'<span class="price_n">¥([\d.]+)</span>', html)
prices = [f"¥{p}" for p in prices][:60]
for i, (name, price) in enumerate(zip(names, prices), 1):
print(f"{i}\t{price}\t{name}")
if __name__ == "__main__":
crawl_dangdang()
运行结果:
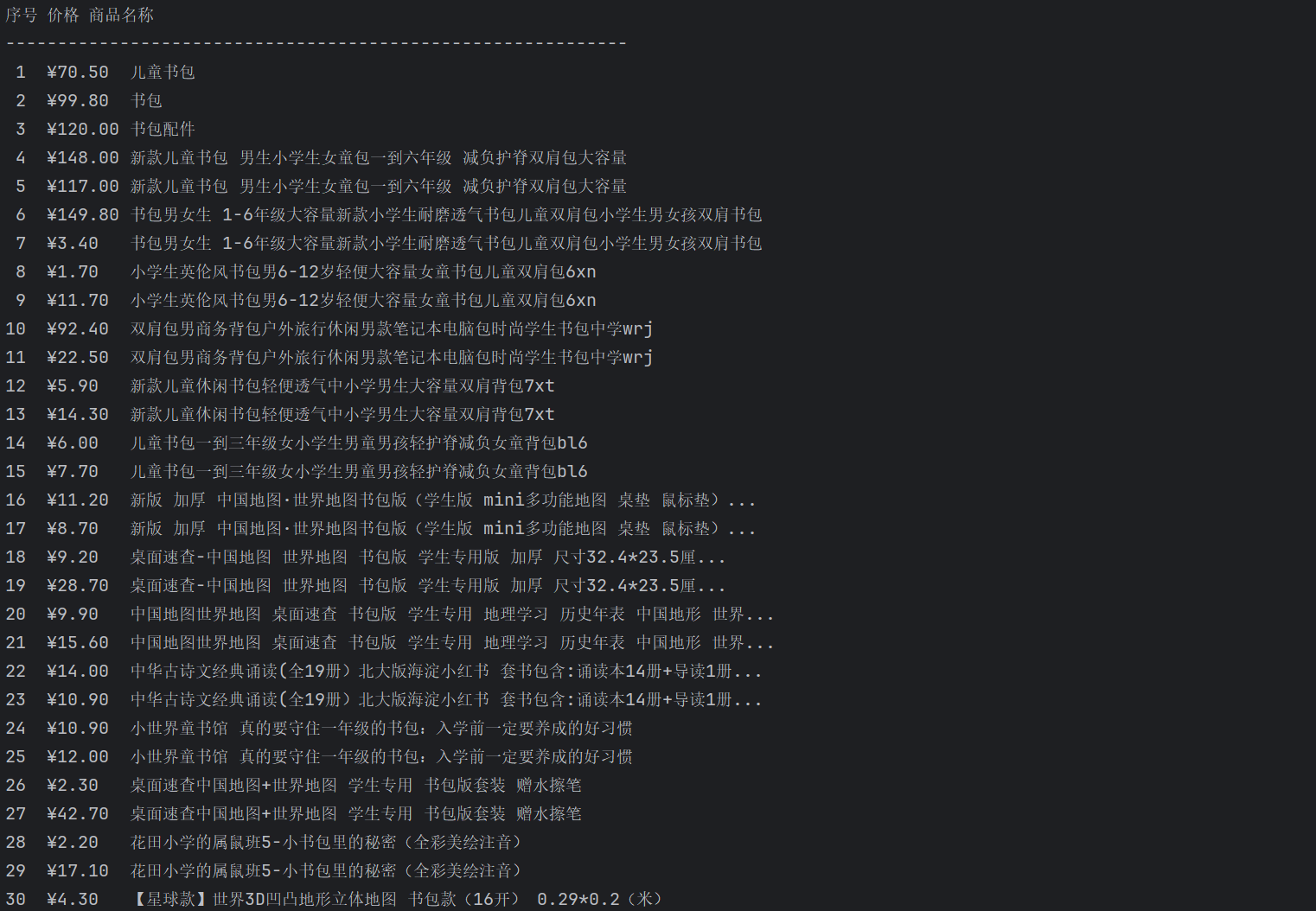
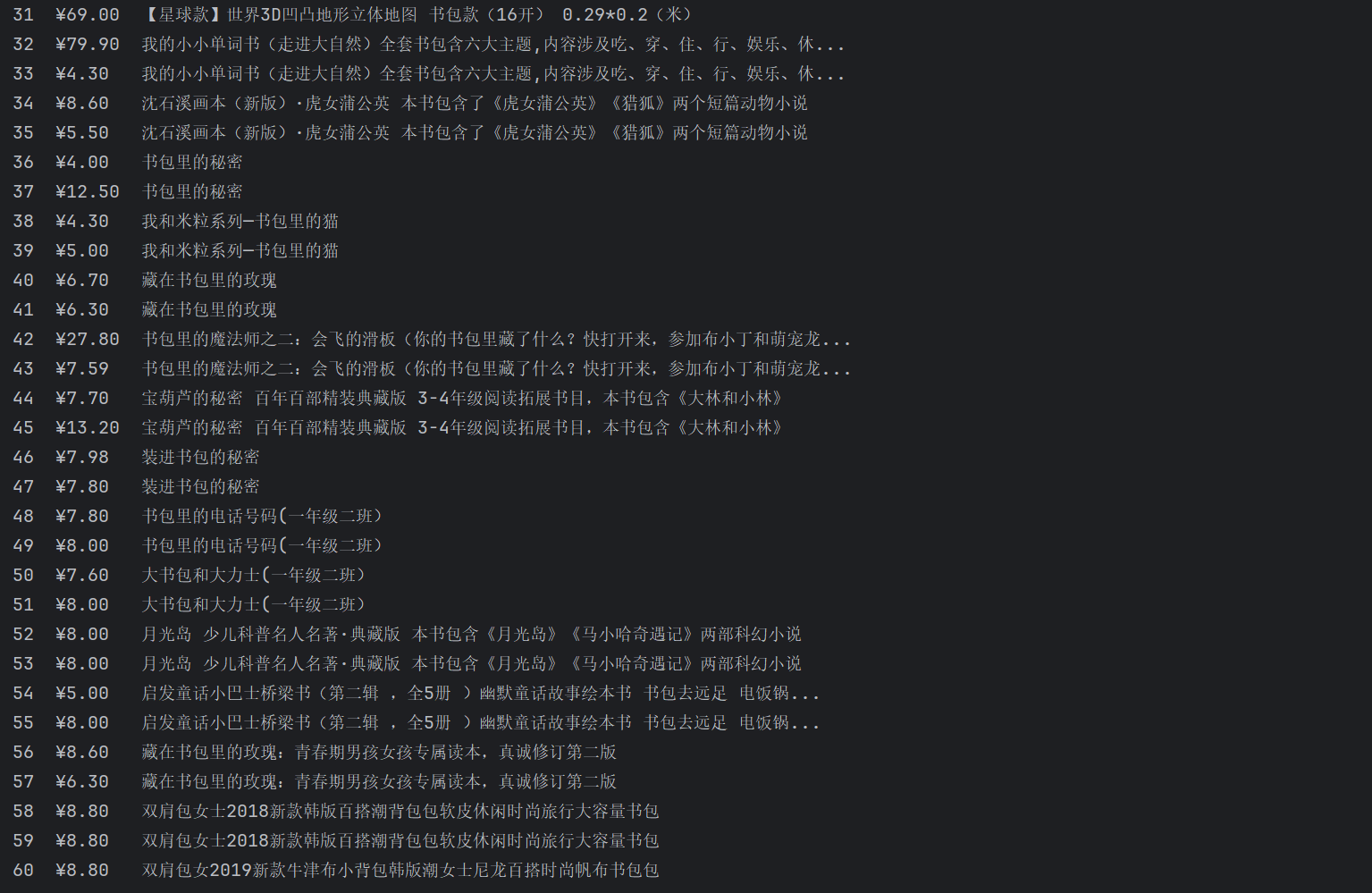
心得体会:
在项目技术选型过程中,我曾将淘宝、京东等主流电商平台作为首要目标,但这些平台均配备了完善的反爬虫机制,需要处理复杂的Cookie动态维护、请求头全链路伪装以及JavaScript动态渲染等高级技术难题,这已超出我的技术范畴。经过在技术社区的多方调研,我在小红书等平台了解到当当网采用相对宽松的反爬策略,其服务端渲染模式使得基础HTTP请求即可获取完整的页面数据,数据结构清晰且稳定。基于对自身技术能力的客观评估和项目周期的现实考量,我最终选择以反爬门槛较低的当当网作为数据源,在保证项目可行性的同时,确保在有限开发资源下实现数据采集的稳定性和可维护性。
作业3:
要求:爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm) 或者自选网页的所有JPEG、JPG或PNG格式图片文件
输出信息:将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
核心代码设计逻辑:
写这个代码时,我首先想到的是先找到网页里所有的图片链接,然后筛选出真正需要的新闻图片。我发现用正则表达式匹配img标签的src属性是最快的方法,过滤环节我主要想排除那些小图标和logo,观察到它们的文件名通常包含"icon"或"logo"关键词,所以就用他这个规则筛了一遍。
核心代码:
点击查看代码
img_urls = re.findall(r'<img.*?src="(.*?)"', html, re.IGNORECASE)
valid_imgs = []
for src in img_urls:
if 'icon' in src.lower() or 'logo' in src.lower():
continue
full_url = urljoin(url, src)
if re.search(r'\.(jpg|jpeg|png)$', full_url, re.IGNORECASE):
valid_imgs.append(full_url)
for i, img_url in enumerate(valid_imgs):
response = requests.get(img_url, timeout=10)
with open(f'images/img_{i}{ext}', 'wb') as f:
f.write(response.content)
运行结果:

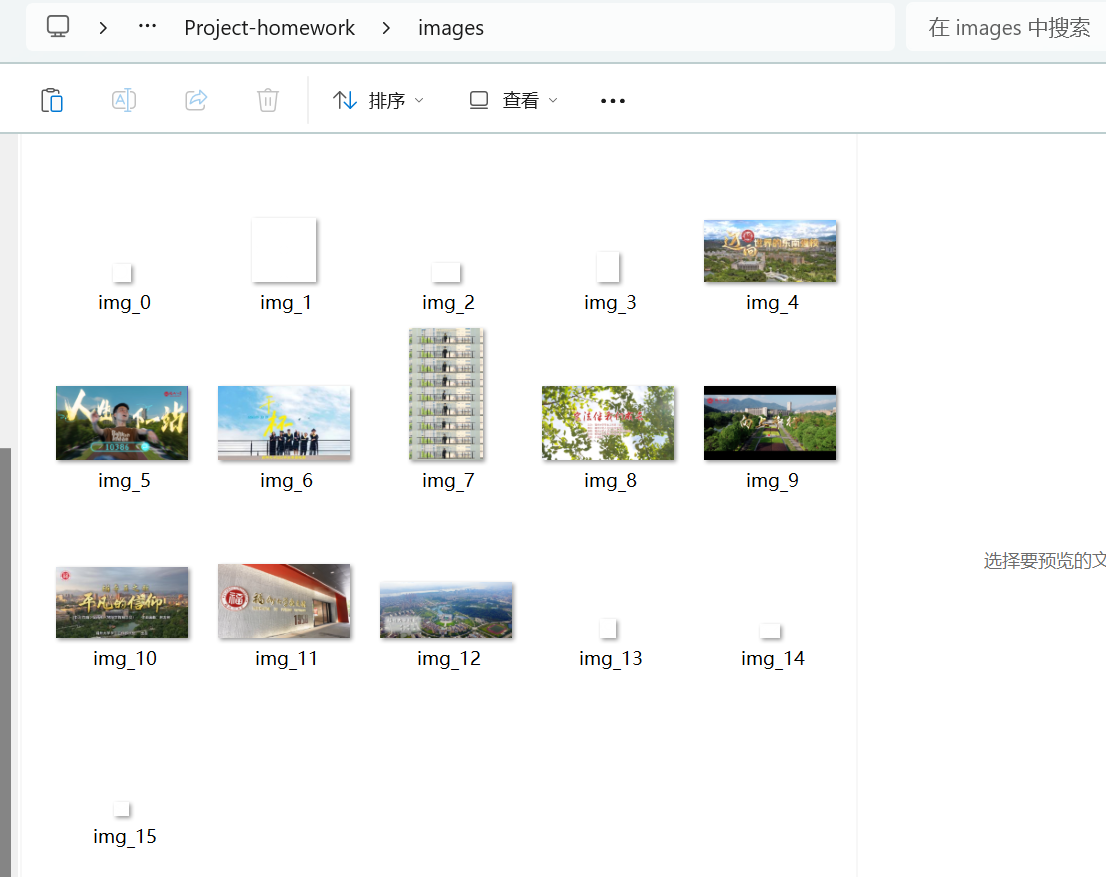

 浙公网安备 33010602011771号
浙公网安备 33010602011771号