
Sqoop简介和实战 (二) 常用操作命令
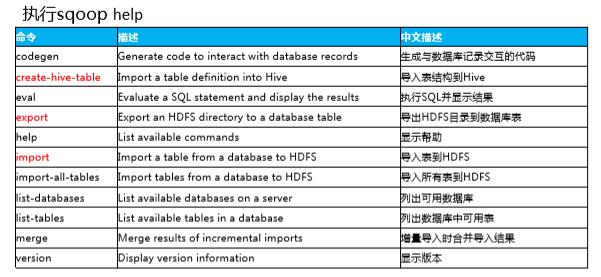
一、命令及常用选项:

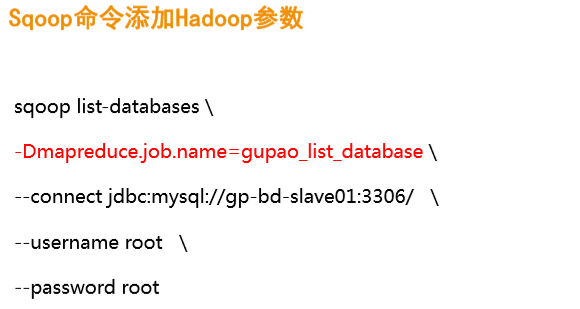

二、全表数据导入
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password 000000 \ --table 'order_detail' \ --target-dir '/user/root/vingo/data/order_detail' \ --delete-target-dir \ -m 1
解释:
import:导入表到HDFS
Dmapreduce.job.name: MR任务的名称
Dmapreduce.job.queuename: 设置一个队列,sqoop启动的MR作业就在这个队列中执行
table: 要导入表的表名
target-dir: 要导入到HDFS的路径
delete-target-dir: 导入前先删除HDFS路径中的数据
m: 使用map的数量
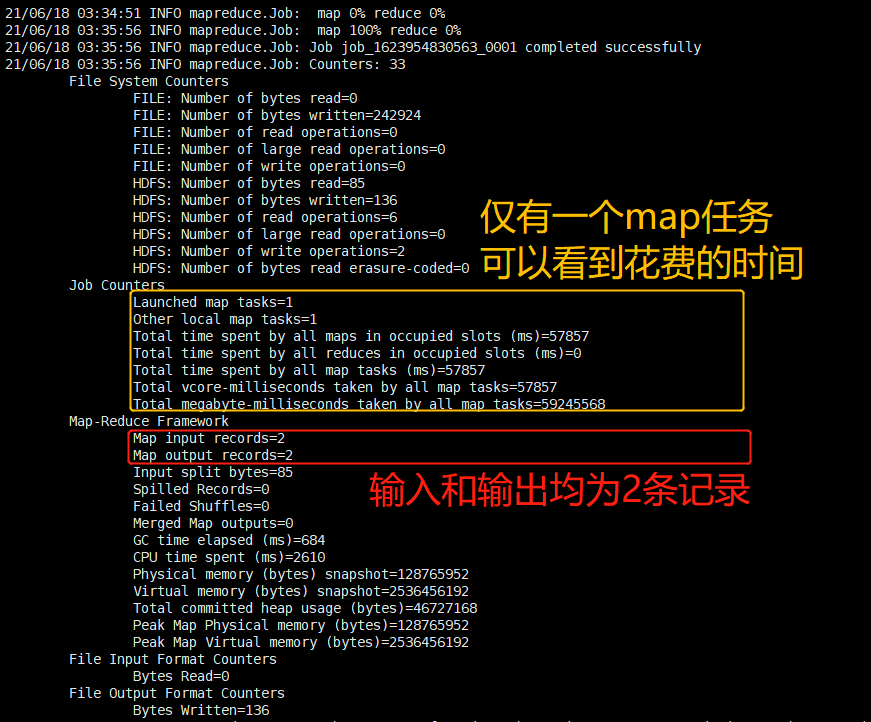
查看运行结果:

可以看到输出文件的命名是:part-m-00000,
HDFS文件的命名规则就是part-开头,然后map输出就再加上m-,最后再加上他的后缀为00000(如果还有文件的话,就在结尾的数字依次增一).
三、指定列导入
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password 000000 \ --table 'order_detail' \ --columns 'id, user_id, product_id, status' \ --target-dir '/user/root/vingo/data/order_detail/' \ --delete-target-dir \ -m 1
结果:

-------------------------------------- 如果 要导入一个以 id 为自增列的表 ---------------------------------------------
需要加上--column"a,b,c"
sqoop export --connect jdbc:mysql://192.168.212.80:3306/bigdatawarehouse --username root -password 000000 --table conpusMonthStatistics --export-dir '/user/hive/warehouse/app.db/conpusmonthstatistics' --fields-terminated-by '\t' --columns "conpusflag,statusflag,monthtime,usernums,productnums,shopnums,merchartnums" --input-null-non-string '\\N' --input-null-string '\\N'
四、指定查询
无论有没有过滤条件,需加上$CONDITIONS
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password 000000 \ --query "select * from order_detail where \$CONDITIONS" \ --target-dir '/user/root/vingo/data/order_detail/' \ --delete-target-dir \ -m 1
结果:

对于有过滤条件的查询:
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password 000000 \ --query "select * from order_detail where \$CONDITIONS and status='success'" \ --target-dir '/user/root/vingo/data/order_detail/' \ --delete-target-dir \ -m 1
结果:
![]()
五、追加模式
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.uses.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password 000000 \ --query "select * from order_detail where \$CONDITIONS and status='success'" \ --target-dir '/user/root/vingo/data/order_detail/' \ --append \ -m 1
执行两次后的结果:

六、数据增量更新
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password 000000 \ --table 'order_detail' \ --check-column 'updated_at' \ --incremental lastmodified \ --last-value '2021-06-18 13:20:13.0' \ --target-dir '/user/root/vingo/data/order_detail/' \ --merge-key 'id' \ -m 1
解释:
check-column: 更新根据的列名
incremental lastmodified: 更新模式为 最后更新
last-value: 新的数据
这里也就是判断'updated_at'所指的数据是否大于 last-value 的值,如果大于就更新成改值,否则就不修改.
merge-key: 根据主键进行合并操作 (会有两个阶段-map、reduce)
过程:
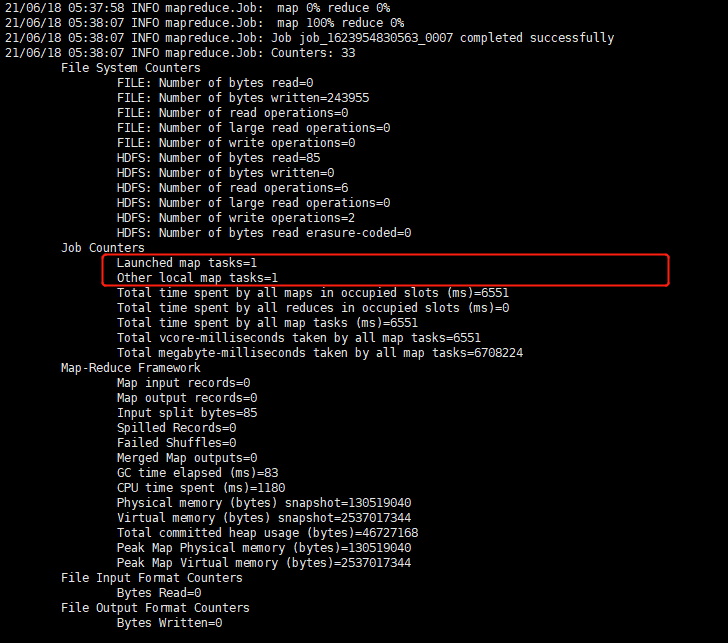
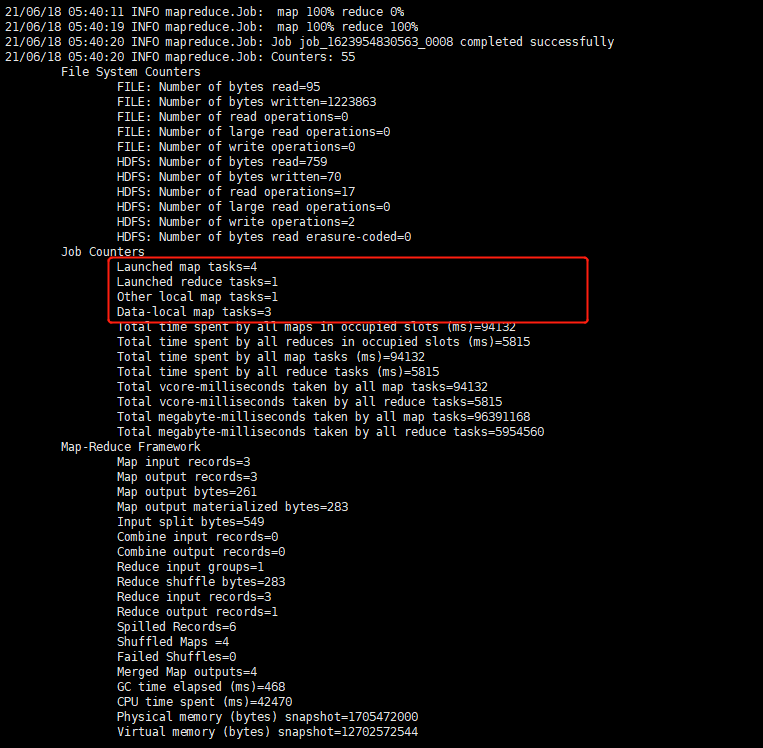
结果:


七、数据量大加大并发
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password 000000 \ --table 'order_detail' \ --check-column 'updated_at' \ --incremental lastmodified \ --last-value '2018-04-14 16:40:53.0' \ --target-dir '/user/root/vingo/data/order_detail/' \ --merge-key 'id' \ --split-by 'updated_at' \ -m 4
可以指定split列,以及增加map任务数量.
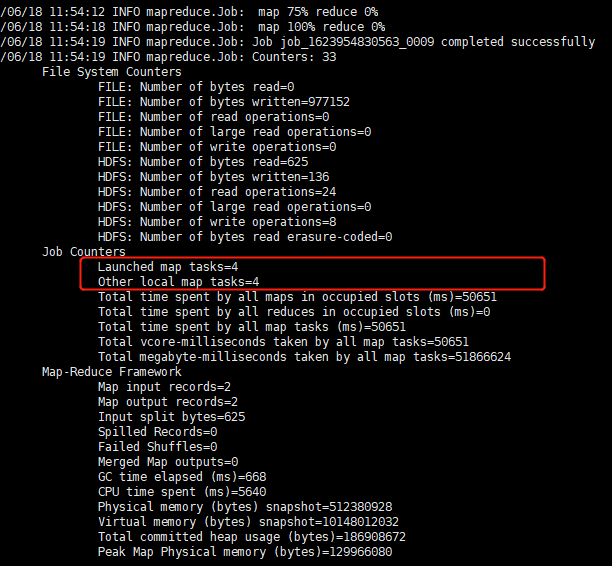
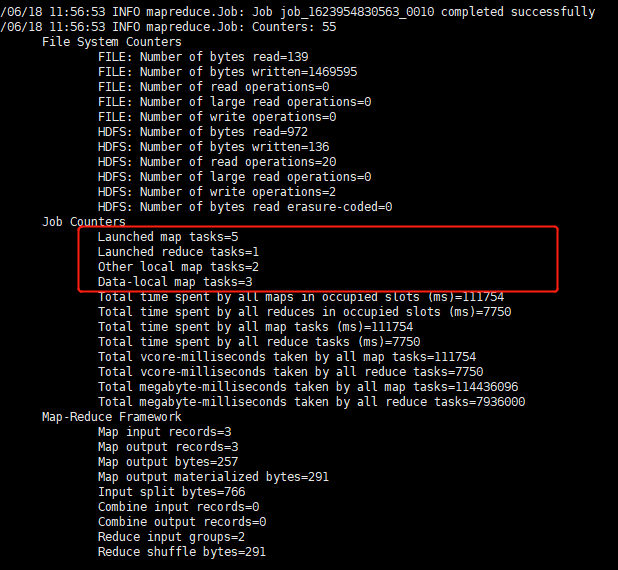
结果:

八、使用密码文件
直接将密码写入命令行是不安全的,因此最好设置一个密码文件.
echo -n '000000' > /home/sqoop/data/vingo/sqoop.pwd
hdfs dfs -put -f sqoop.pwd /user/root/vingo/
hdfs dfs -cat /user/root/vingo/sqoop.pwd
hdfs dfs -chmod 400 /user/root/vingo/sqoop.pwd
sqoop import \ -Dmapreduce.job.name=sqoop_import \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/test \ --username root \ --password-file /user/root/vingo/sqoop.pwd \ --table 'order_detail' \ --target-dir '/user/root/vingo/data/order_detail/' \ --delete-target-dir \ --split-by 'updated_at' \ -m 3
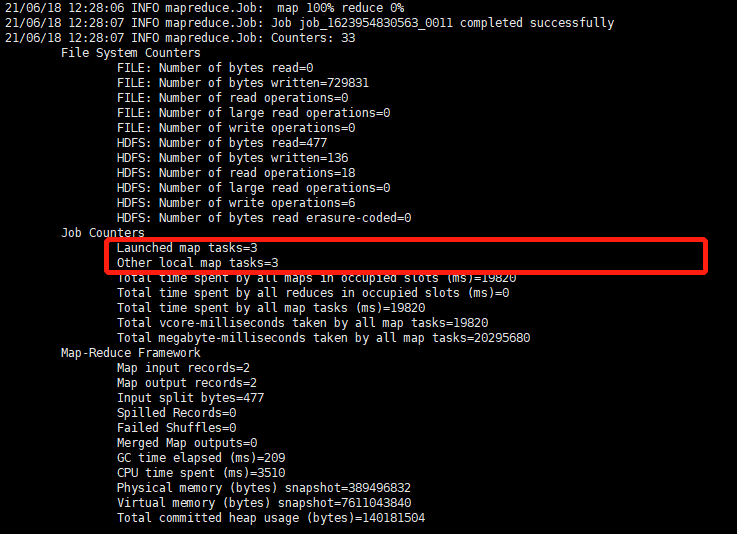
结果:

九、Sqoop数据导出到MySQL
sqoop export \ -Dmapreduce.job.name=sqoop_export \ -Dmapreduce.job.queuename=root.users.root \ --connect jdbc:mysql://master:3306/ods \ --username root \ --password-file /user/root/vingo/sqoop.pwd \ --table 'order_detail' \ --export-dir '/user/hive/warehouse/ods.db/ods_order_detail' \ --update-key id \ --update-mode allowinsert
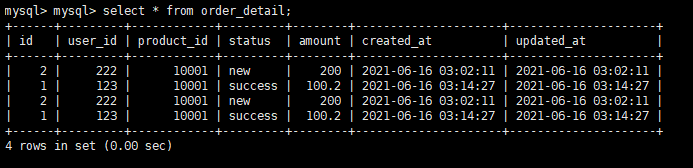
前提是 MySQL中原来是有表order_detail的,比如我这里原来的表就是:

HDFS中的数据和他是一样的:

但是导入后不会发生覆盖,而是追加,如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号