
Kettle (二)实战案例 (2) 关系型数据库和HDFS之间的数据同步
一、ETL流程图

开始-->
转换-初始化参数:TABLE_NAME(test.order_detail)和 IN_STAT_DATE -->
起始日志:操作的表名、操作状态、操作时间 -->
执行:将参数指代表中的数据 写入指定的文本文件-->
Shell:脚本语句创建新的文件夹、上传文本文件到此路径下-->
完成日志:操作表名、操作状态、操作时间-->
插入Hive, 如果失败就终止Job
二、解释
1、参数初始化:INIT_PARAMETERS
(1)SQL
初始化参数 TABLE_NAME(test.order_detail)和IN_STAT_DATE(本次案例中该参数并没有用到)
SELECT 'order_detail' AS TABLE_NAME, date_add(now(), interval -400 hour) AS IN_STAT_DATE FROM DUAL
(2)设置变量

2、写日志:LogStart
INSERT INTO etl.task_log (TASK_NAME, STATUS, LOG_TIME ) SELECT '${TABLE_NAME}', '${STATUS}', NOW() FROM DUAL
设置参数:

3、加载表中数据到本地指定文件上:Load Full Table To HDFS Shell
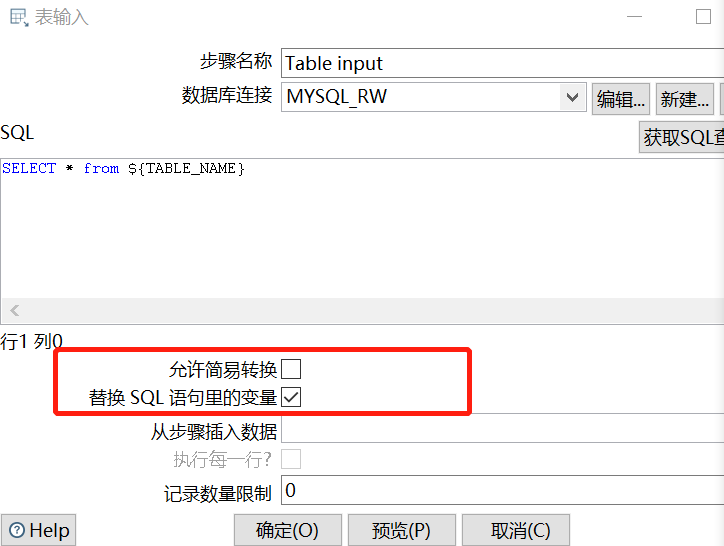
(1)Table input
SELECT * from ${TABLE_NAME}
要勾选替换SQL语句里的变量:
(2)Text file output
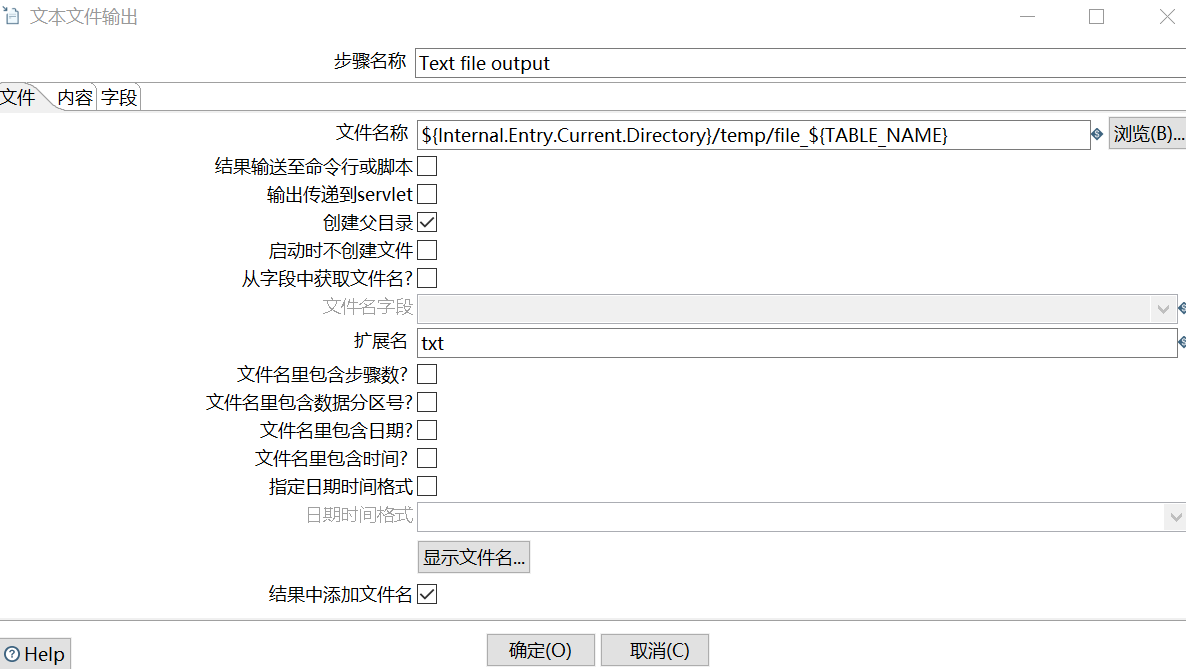
其中,文件名称和扩展名写的就是本地路径下的文件:
/opt/module/Kettle7.1/data-integration/KettlePractice/ETL_KETTLE_DEMO_HDFS/temp/file_order_detail.txt
4、Shell 脚本编写命令将文件上传到HDFS上
可以选择插入脚本,也可以选择已有脚本文件
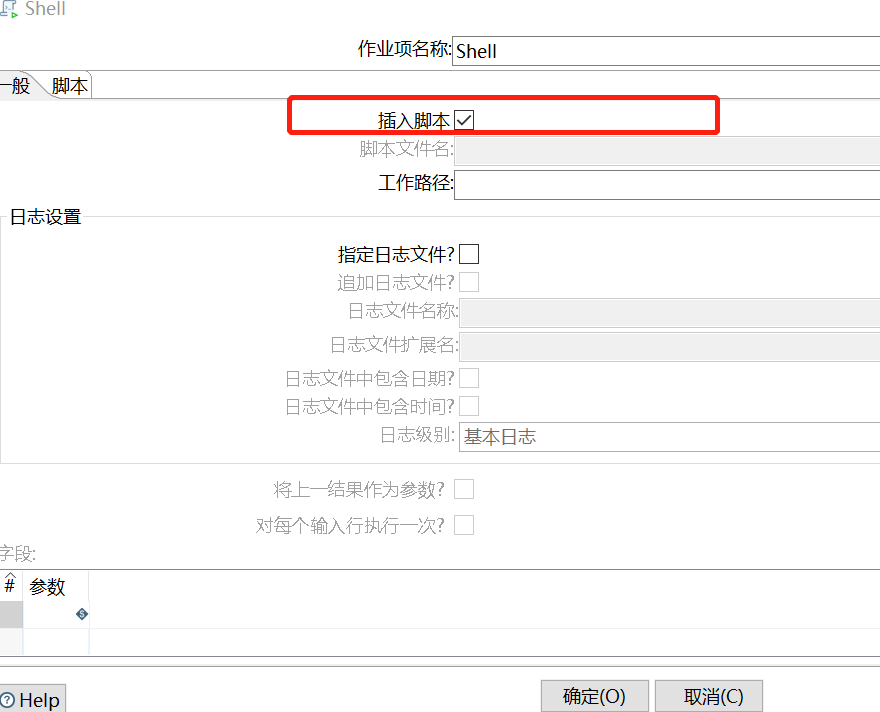
这里直接插入脚本,脚本内容:
hdfs dfs -mkdir -p /user/root/vingo/data/${TABLE_NAME}/ hdfs dfs -put -f ${Internal.Entry.Current.Directory}/temp/file_${TABLE_NAME}.txt /user/root/vingo/data/${TABLE_NAME}/
创建目录:/user/root/vingo/data/order_detail/
上传输出的文件 file_order_detail.txt 到刚创建好的HDFS路径 /user/root/vingo/data/order_detail/ 下。
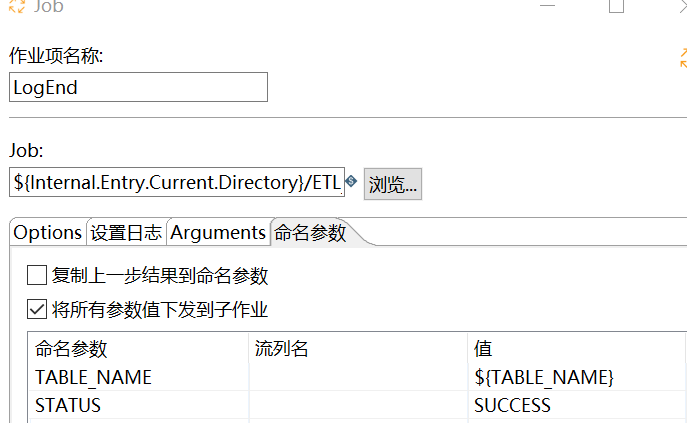
5、结束日志:LogEnd
SQL 和 LogStart 相同
INSERT INTO etl.task_log (TASK_NAME, STATUS, LOG_TIME ) SELECT '${TABLE_NAME}', '${STATUS}', NOW() FROM DUAL
设置参数:
6、在Hive中创建数据库和表:INSERT INTO HIVE ODS
DROP DATABASE IF EXISTS ODS; CREATE DATABASE ODS; CREATE TABLE ODS.TEST(ID INT);
这里只是可以在Hive创建一个表test, 他有int类型的ID字段.
三、查看结果
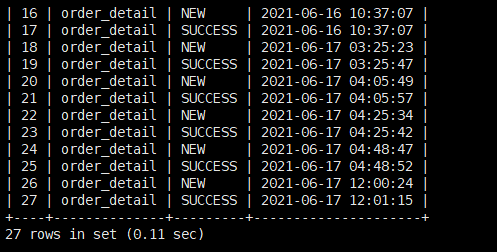
日志表etl.task_log有更新的数据:
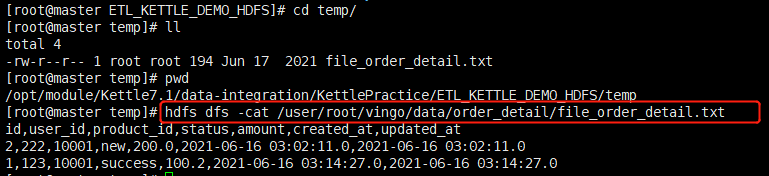
HDFS中新创建的文件:
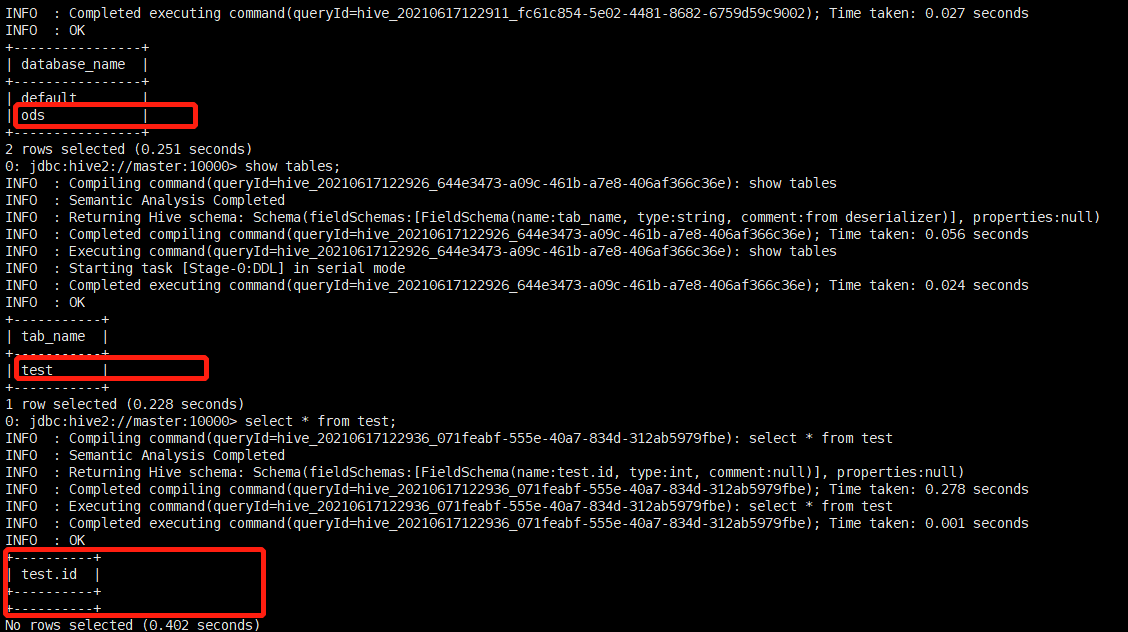
Hive中有新创建的数据库ods和表test:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号