
Python爬虫-数据采集应用
网络数据采集模块库
一、B/S程序的工作原理
浏览器/服务器
其主要通过 资源请求-相应 的模式运行
网络所有资源的定位均通过网络地址(即 url,uniform resource location 统一资源定位)
HTTP协议:
用户 会向 Internet 发送 请求Request,Internet 会将 请求Request 发送给 服务器
二、爬虫
爬虫一般是指网络爬虫。
本质:模拟浏览器发送请求-->
下载网页代码-->
提取有用额数据-->
存放在数据库或文件中。
基本流程:发送请求-->获取响应内容-->解析内容-->保存数据
发送请求过程:
请求地址-->请求头-->请求体-->请求方法
三、Requests模块
一个基于urllib模块简单易用的第三方网络HTTP请求模块库。
Requests是用Python编写,基于urllib,采用开源协议的HTTP库
它比urllib更加方便,可以节约我们大量的工作,完全满足HTTP访问操作需求。
四、什么是Requests?
下载安装部署:pip install -U requests
在使用的前,import requests
import requests #发送请求需要写user-agent headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36"} #1、访问网页文本内容 response1 = requests.get("https://movie.douban.com/top250", headers = headers) # print(response1.text) #获取文本字符串 #2、访问图片: response2 = requests.get("https://img3.doubanio.com/view/photo/s_ratio_poster/public/p579729551.jpg", headers = headers) with open('a.jpg', 'wb') as f: f.write(response2.content) #图片--二进制内容
请求提交的6种常见方法:
requests.get(‘http://httpbin.org/get’) #GET请求
requests.post(“http://httpbin.org/post”) #POST请求
requests.put(“http://httpbin.org/put”) #PUT请求
requests.delete(“http://httpbin.org/delete”) #DELETE请求
requests.head(“http://httpbin.org/head”) #HEAD请求
requests.options(“http://httpbin.org/get”) #OPTIONS请求
五、Response对象
使用requests方法后,会返回一个response对象,其存储了服务器响应的内容
六、cookie和session的区别
1、cookie数据存放在客户的浏览器上,session数据放在服务器上。
2、cookie不是很安全,别人可以分析放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session。
3、生存周期,session是浏览器页面关闭,超时或关闭服务器等情况会失效,而cookie只会超过有效时间后才会失效。
七、Robots协议
robots协议也叫robots.txt是一种存放在网站根目录下的ASCII编码的文本文件。
八、lxml中的xpath
1、安装lxml:
pip install lxml
2、xpath语法:
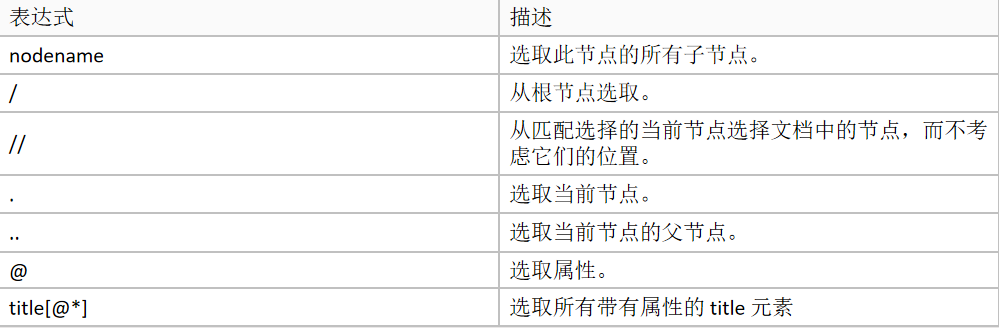
import requests from lxml import etree headers = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" } response = requests.get("https://movie.douban.com/top250", headers = headers) #html 变成 lxml html = etree.HTML(response.text) #xpath取值返回list列表 title = [] #标题 title = html.xpath("//div[@class='item']/div[@class='info']/div[@class='hd']/a/span[@class='title'][1]/text()") #图片 img = html.xpath("//div[@class='item']/div[@class='pic']/a/img/@src") print(title) print(img) for i,j in zip(title, img): with open("D:\\file\\" + i + ".jpg", "wb") as f: jj = requests.get(j, headers = headers).content f.write(jj) print("成功")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号