
电影推荐系统-[实时推荐部分](七)问题
1. 为什么接收电影评分数据既用Redis又用Flume?
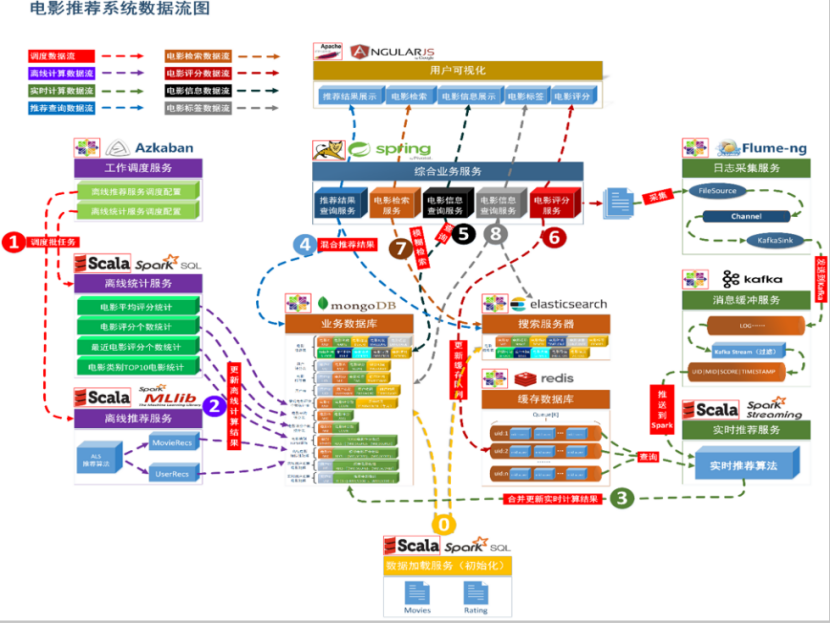
Flume算的是现在的事实数据,redis算的则是历史数据。
2. 计算待选电影的推荐分数的时候,为什么要将“Rr-用户最近对电影r的评分userRecentlyRatings”和电影P最相似的K个电影--用共享变量的方式”进行双重for循环?
以下过程图来说明:
注:红色的代表“实时”,蓝色的代表“历史/离线”

//数据形式:(attr(0).trim.toInt, attr(1).trim.toDouble)
}.toArray


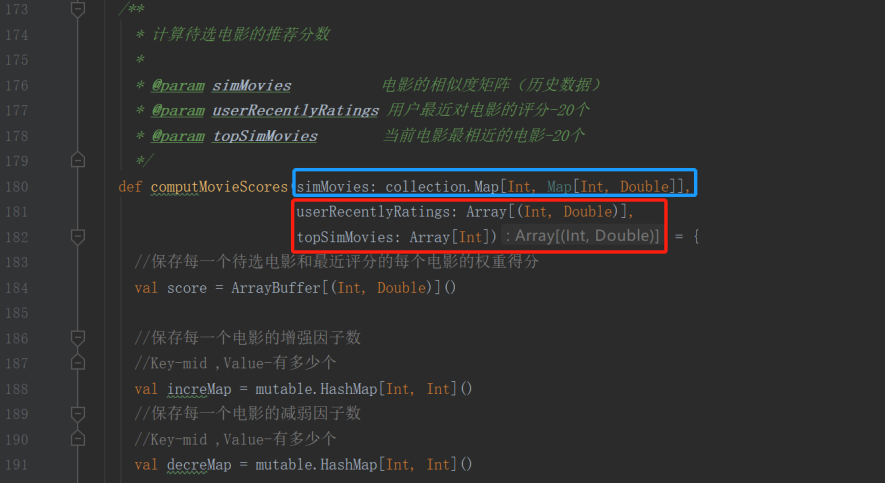
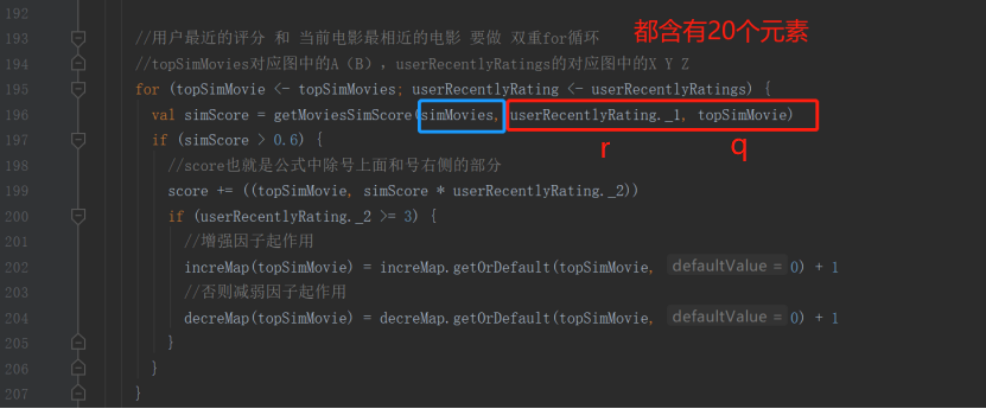
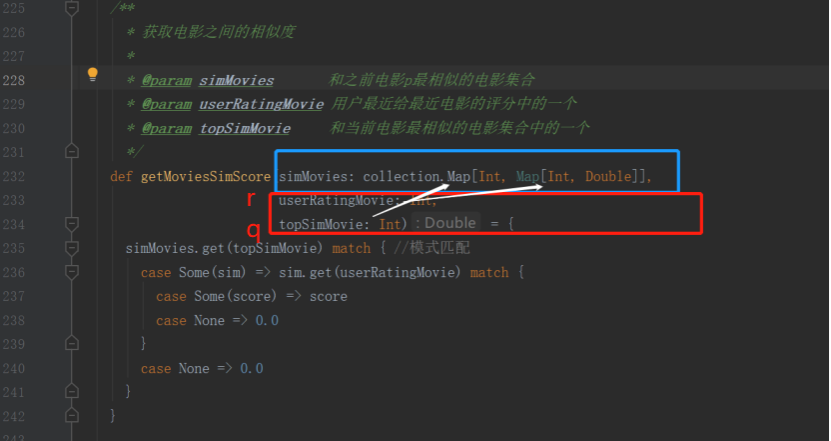
由此分析可看出,双重for循环是为了后面每个电影r和电影q与相似度矩阵(离线部分就已经算好的)进行match--比配而进行的。
这最终就是为了实现那个公式的一小部分:

3. q和r之间的电影相似度求的过程中哪句代码能表明它引入了新的数据?

在上图代码中mid就是实时地从Redis里面获取的,当然uid也是。
电影r的ID其实就是这里的mid,uid是后面用来得到用户已经看过电影的。
4.电影类别的获取:
在staticRecommender包里的StatisticsApp类里加上:
//3.取出所有的电影类别
val movieGenresDF=movies.toDF().map{
case row=>{
row.getAs[String]("genres")
}
}.flatMap(_.split("\\|")).distinct().toDF().show()
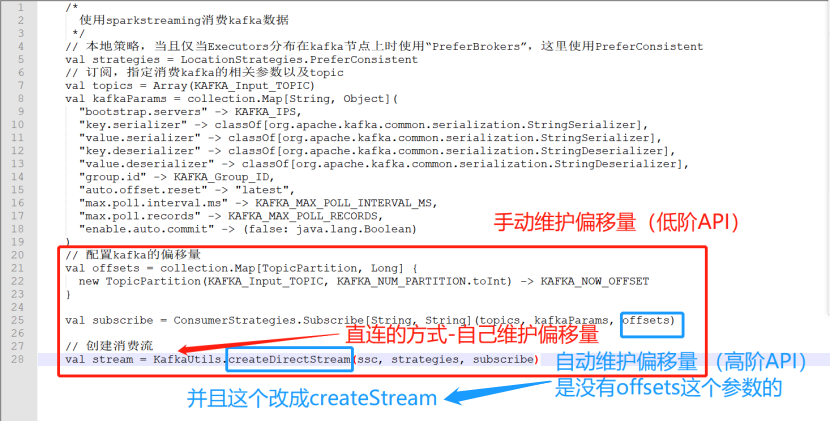
5.sparkstreaming对接kafka出现的数据积压问题
详见:https://blog.csdn.net/ntk1986/article/details/80755888
其中,常见的问题:
6.lg的表示


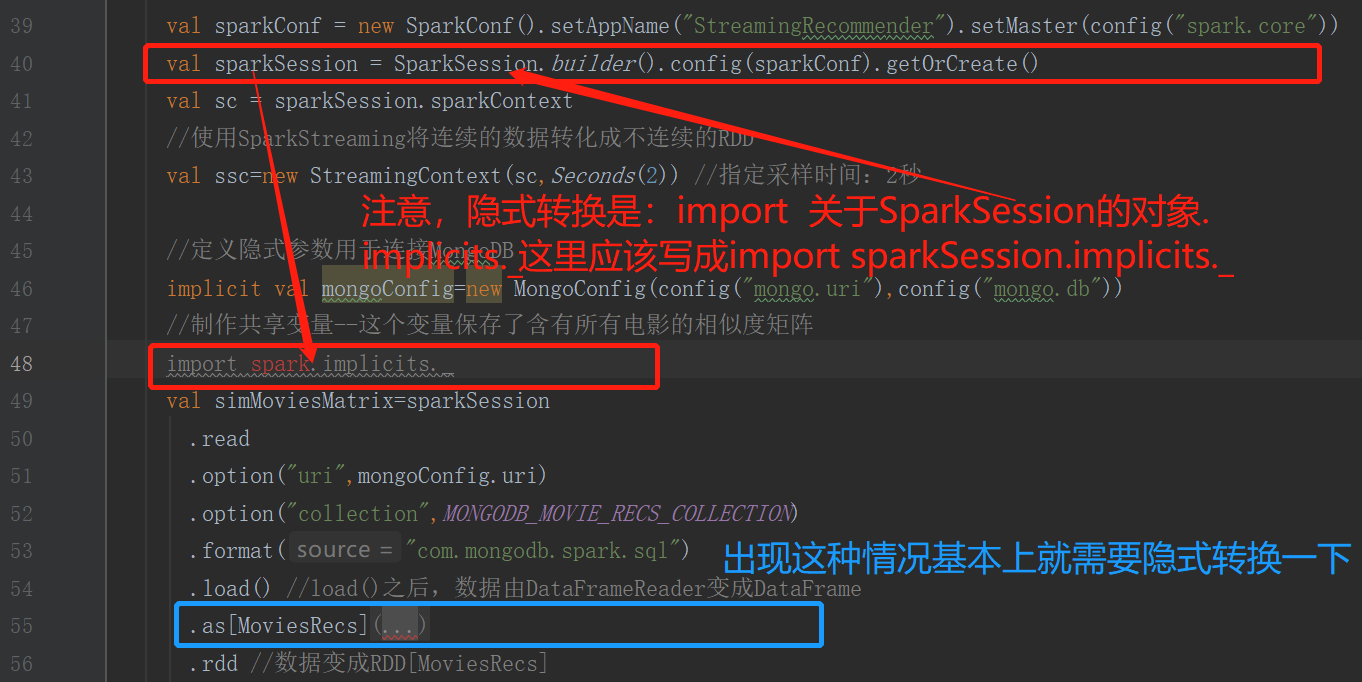
7.关于隐式转换的引入-import
8.对于电影的时间戳数据类型
时间戳数据类型最好设为Long,此项目涉及到的时间戳数据用Int也可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号