
电影推荐系统-[实时推荐部分](五)Kafa Stream
注意:工作中,流式计算这部分用到Kafka Stream的概率不是很大。了解其作用就可以了。
关于Kafka Stream的代码看懂即可。
Kafka Stream简介
1)Kafka Stream 是Kafka的一个组件。装好Kafka之后自带的。
2)Kafka Stream提供的是一个基于Kafka的流式处理类库。
3)大部分流式系统中都已部署了Kafka,此时使用Kafka Stream的成本非常低。
4)使用Storm或Spark Streaming时,需要为框架本身的进程预留资源。Kafka只是一个类库,不占用资源。
5)Kafka的编程模型(其中,如果是简单的Kafka流程,就没有中间那些小方框):
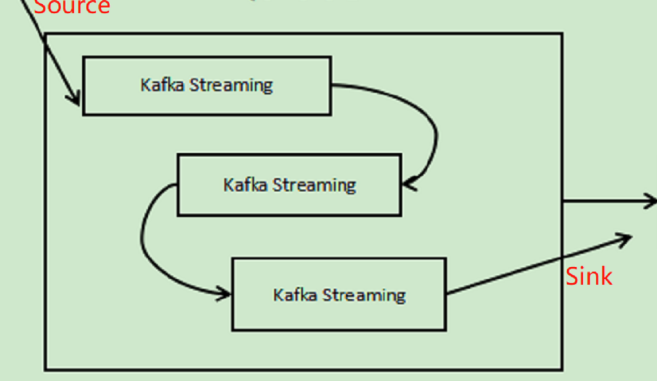
对于整个数据流转的流程如下:
数据-->Flume-->log-->Kafka Stream-->recom(topic=recom)-->Spark Streaming
接下来实现的就是log-->recom(上行高光部分)
Java代码实现:
还是在recommender里面新创建一个Module:
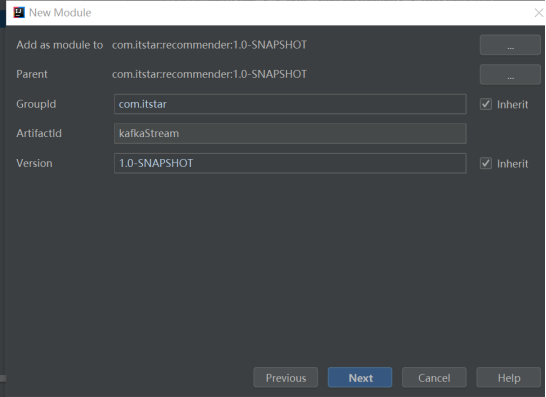
然后,再在里面创建一个包然后再在这个包里创建新的Java类
修改pom.xml文件-只添加Kafka的依赖即可:
|
<dependencies>
|
Java代码:
Application类:
Application类相当于Kafka Stream处理流程中的外面的框,里面可以有一个一个的小过程。
Java代码:
package kafkaStream;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.processor.TopologyBuilder;
import java.util.Properties;
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/27 & 1.0
* 输入topic: log
* MOVIE_RATING_PREFIX:1|20|5.0|1564412038
* 输出topic: recom
* 1|20|5.0|1564412038
*/
public class Application {
public static void main(String[] args) {
//声明
String brokers = "192.168.212.21:9092";
String zookeeper = "192.168.212.21:2181";
String fromTopic = "log";
String topTopic = "recom";
//一、初始化Kafka的环境
Properties settings = new Properties();
settings.put(StreamsConfig.APPLICATION_ID_CONFIG, "logFilter");//相当于Spark中的setName(),可以随便起
settings.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, brokers);
settings.put(StreamsConfig.ZOOKEEPER_CONNECT_CONFIG, zookeeper);
//防止Linux和Windows上的时间不统一,设置时间的class
//注:接收log的数据中最后含有时间戳字段
settings.put(StreamsConfig.TIMESTAMP_EXTRACTOR_CLASS_CONFIG, MyEventTimeExtractor.class.getName());
StreamsConfig config = new StreamsConfig(settings);
//创建拓扑图
TopologyBuilder builder = new TopologyBuilder();
builder.addSource("SOURCE", fromTopic) //Kafka Stream过程数据源名字叫SOURCE
//addprocessor()可以写多个,就是可以继续.add...
.addProcessor("PROCESS",()->new LogProcesser() , "SOURCE")
.addSink("SINK", topTopic, "PROCESS");
//启动Kafka
KafkaStreams streams = new KafkaStreams(builder, config);
streams.start();
}
}
LogProcesser类:
LogProcesser类相当于Kafka Stream处理过程图中里面的小框。
Java代码:
package kafkaStream;
import org.apache.kafka.streams.processor.Processor;
import org.apache.kafka.streams.processor.ProcessorContext;
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/27 & 1.0
*/
public class LogProcesser implements Processor<byte[],byte[]> {
private ProcessorContext context;
@Override
public void init(ProcessorContext processorContext) {
//初始化
//processorContext是一个完整的数据处理的上下文,将其传入私有的变量context里面,
//这样也就拿到了Kafka Stream运行时侯的上下文
this.context = processorContext;
//Kafka运行的时候会调用这个init()
//数据的流动需要context
}
@Override
public void process(byte[] bytes, byte[] line) {
//数据处理逻辑
//Kafka可以将以前单机的java代码直接用在在Kafka上,不需要改动太多的代码,
// 直接将之前的Java代码放到process()里面即可。
//如果是以前是单机的,现在要用Spark Streaming,那就需要学DStream,
//然后再将单机的东西做成DStream的样子,包装RDD,再去Map方法各种处理...
String input = new String(line);
//MOVIE_RATING_PREFIX:1|20|5.0|1564412038
if (input.contains("MOVIE_RATING_PREFIX:")){
input = input.split("MOVIE_RATING_PREFIX:")[1].trim();
System.out.println("process data");
context.forward("LogProcesser".getBytes(),input.getBytes());
}
}
@Override
public void punctuate(long l) {
}
@Override
public void close() {
}
}
MyEventTimeExtractor类:
用于防止Linux和Windows时间不一致情况的发生
Java代码:
package kafkaStream;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.streams.processor.TimestampExtractor;
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/27 & 1.0
* 时间戳提取器
* 防止数据都不进来、连接超时的情况
*/
public class MyEventTimeExtractor implements TimestampExtractor {
@Override
public long extract(ConsumerRecord<Object, Object> consumerRecord, long l) {
return System.currentTimeMillis();
}
}
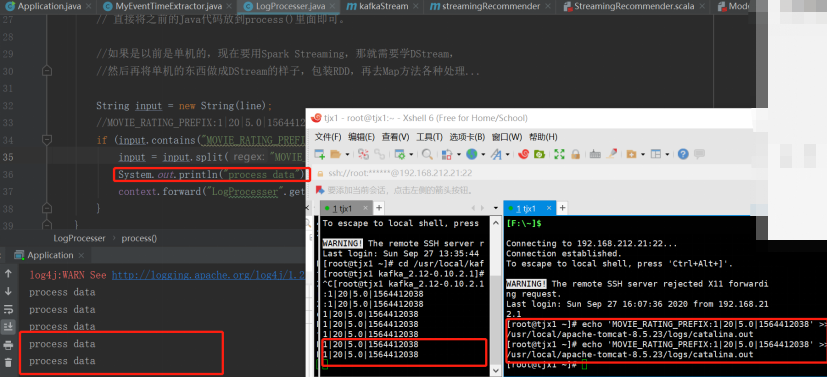
测试
首先启动Kafka的消费者端用于接收数据
[root@tjx1 kafka_2.12-0.10.2.1]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.212.21:9092 --topic recom
接着启动Kafka的生产者端用于产生数据
[root@tjx1 kafka_2.12-0.10.2.1]# ./bin/kafka-console-producer.sh --broker-list 192.168.212.21:9092 --topic log
然后启动程序,向Kafka 的生产者里面传数据:
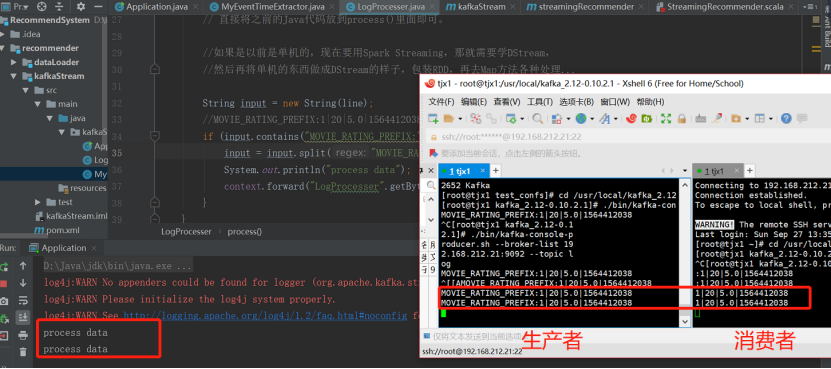
增加前面的过程--Flume从日志中去采集,然后写到log里面。
接下再启动Flume:
[root@tjx1 apache-flume-1.7.0-bin]# ./bin/flume-ng agent -c ./conf/ -f ./test_confs/log-kafka.properties -n agent
然后追加内容到Flume的source文件:
echo 'MOVIE_RATING_PREFIX:1|20|5.0|1564412038' >> /usr/local/apache-tomcat-8.5.23/logs/catalina.out
接下来再查看效果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号