
电影推荐系统-[实时推荐部分](三)编写代码--实时推荐(4) 【编写Scala代码--计算待选电影的推荐优先级(就是实现那个公式)】
Posted on 2020-09-27 19:18 MissRong 阅读(466) 评论(0) 收藏 举报电影推荐系统-[实时推荐部分](三)编写代码--实时推荐(4)
【编写Scala代码--计算待选电影的推荐优先级(就是实现那个公式)】
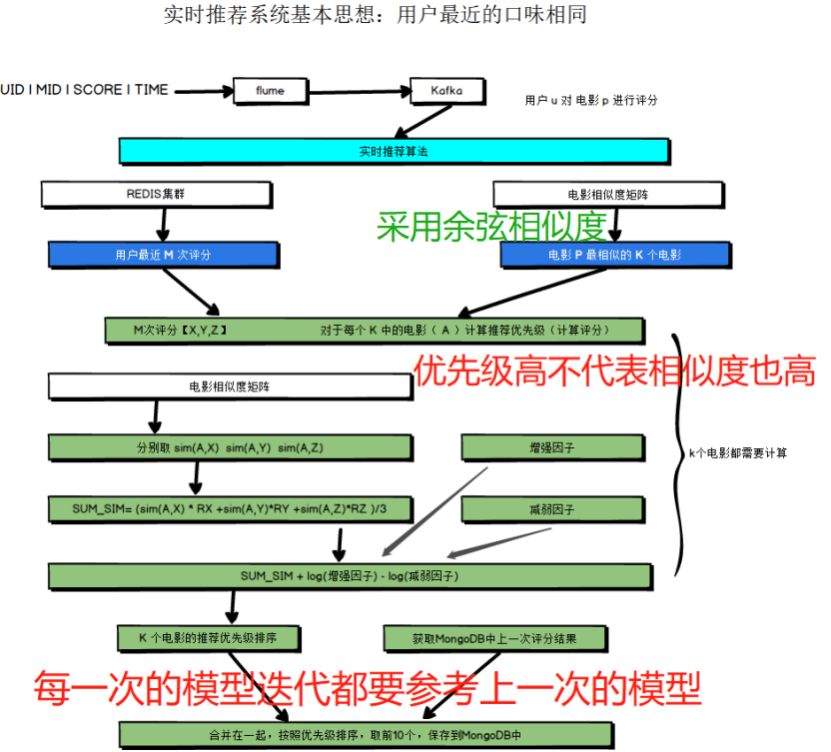
Scala代码:
package streamingRecommender import com.mongodb.casbah import com.mongodb.casbah.MongoClient import com.mongodb.casbah.commons.MongoDBObject import org.apache.kafka.common.serialization.StringDeserializer import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies} import org.apache.spark.streaming.{Seconds, StreamingContext} import redis.clients.jedis.Jedis import scala.collection.JavaConversions._ import scala.collection.mutable import scala.collection.mutable.ArrayBuffer /** * @Author : ASUS and xinrong * @Version : 2020/9/25 */ object ConnHelper{ //lazy--用到谁后再创键 lazy val jedis=new Jedis("192.168.212.21") lazy val mongoClient=MongoClient(casbah.MongoClientURI("mongodb://192.168.212.21:27017/recom")) } object StreamingRecommender { //声明 val MAX_USER_RATINGS_NUM = 20 //从Redis中获取多少个用户的评分 val MAX_SIM_MOVIES_NUM = 20 //相似电影候选表中取多少个电影 val MONGODB_MOVIE_RECES_COLLECTION = "MovieRecs" val MONGODB_RATING_COLLECTION = "Rating" val MONGODB_STREAM_RECS_COLLECTION = "StreamRecs" //实时推荐写入哪张表 def main(args: Array[String]): Unit = { //一、声明Spark的环境、Kafka和MongoDB的相关信息---------------------------------------------------------------------------------------------- val config = Map( "spark.cores" -> "local[3]", "kafka.topic" -> "recom", "mongo.uri" -> "mongodb://192.168.212.21:27017/recom", "mongo.db" -> "recom" ) val sparkConf = new SparkConf().setAppName("StreamingRecommmender").setMaster(config("spark.cores")) val spark = SparkSession.builder().config(sparkConf).getOrCreate() val sc = spark.sparkContext //使用SparkStreaming将连续的数据转化成不连续的RDD val ssc = new StreamingContext(sc, Seconds(2)) //指定采样时间:2秒 //定义隐式参数用于连接MongoDB implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db")) import spark.implicits._ //制作共享变量--这个变量保存了含有所有电影的相似度矩阵 val simMovieMatrix = spark .read .option("uri", mongoConfig.uri) .option("collection", MONGODB_MOVIE_RECES_COLLECTION) .format("com.mongodb.spark.sql") .load() //load()之后,数据由DataFrameReader变成DataFrame .as[MoviesRecs] .rdd //数据变成RDD[MoviesRecs] .map { //改变数据格式 bean => (bean.mid, bean.recs.map(x => (x.mid, x.res)).toMap) }.collectAsMap() //将整体变成Map(映射的形式)--Map[Int,Map[Int,Double]] //将共享变量(广播变量)共享出去 val simMovieMatrixBroadCast = sc.broadcast(simMovieMatrix) // val abc=sc.makeRDD(1 to 2) // abc.map(x=>simMovieMatrixBroadCast.value.get(1)).count() //**************************** Kafka的配置信息 *********************************** //存放Kafka的配置信息(基本上不太会改动) val kafkaPara = Map( "bootstrap.servers" -> "192.168.212.21:9092", //Kafka的IP "key.deserializer" -> classOf[StringDeserializer], //编码解码工具 "value.deserializer" -> classOf[StringDeserializer], //编码解码工具 "group.id" -> "recomgroup" //消费者组--注意:需要在Kafka的配置文件-server.properties里进行配置 ) //二、连接Kafka将数据获取进来-------------------------------------------------------------------------------------- //1.连接Kafka(直连的方式) //1)LocationStrategies--从...取数据,一般用:PreferConsistent(一般都是固定的) //查看其原理啥的参考:https://blog.csdn.net/Dax1n/article/details/61917718 //2)ConsumerStrategies:和消费有关的 //Subscribe后面最好加上:[String,String](不加也可) val kafkaStream = KafkaUtils.createDirectStream(ssc, LocationStrategies.PreferConsistent, ConsumerStrategies.Subscribe[String, String](Array(config("kafka.topic")), kafkaPara)) //三、接收评分流--UID | MID | Score | TIMESTAMP-------------------------------------------------------------------- val ratingStream = kafkaStream.map { case msg => val attr = msg.value().split("\\|") //注意:Scala和java 里面符号"|"都需要用转义符进行转义 (attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt) //将数据重新组织了一下--用户ID,电影ID,评分,时间戳 } ratingStream.foreachRDD { rdd => rdd.map { case (uid, mid, score, timestamp) => //################################## 实时计算逻辑的实现 ################################# //1)从redis中获取最近这段时间的M次评分(这里M=20) //getUserRecentlyRating(评分次数,用户ID,定义的Lay变量) val userRecentlyRatings = getUserRecentlyRating(MAX_USER_RATINGS_NUM, uid, ConnHelper.jedis) //2)获取最近浏览电影r最相似的M个电影--用共享变量的方式(电影之间的相似度矩阵已经在离线部分求过) //getTopSimMovies(评分次数,电影ID,用户ID,共享变量--这个变量保存了含有所有电影的相似度矩阵) //simMovieMatrixBroadCast---BroadCast[Map[Int,Map[Int,Double]]] //simMovieMatrixBroadCast.value---Map[Int,Map[Int,Double]] val simMovies = getTopSimMovies(MAX_SIM_MOVIES_NUM, mid, uid, simMovieMatrixBroadCast.value) //3)计算待选电影的推荐优先级(就是实现那个数学分析公式) //computMovieScores(共享变量-保存了含有所有电影的相似度矩阵, // 从redis中获取当前最近的M次评分(这里M=20),获取电影P最相似的K个电影) val streamRecs = computMovieScores(simMovieMatrixBroadCast.value, userRecentlyRatings, simMovies) //4)将数据保存到MongoDB中 saveRecsToMongoDB(uid, streamRecs) }.count() //触发计算才有显示,对count()的结果我们不感兴趣,只是用他触发计算 //运行Spark Streaming 启动流式计算 ssc.start() //不会停的,等待手动停止 ssc.awaitTermination() } /** * 从Redis 取数据--当前最近的(新加入的)M次评分 * * @param num 评分个数 * @param uid 谁评的分数 * @param jedis 连接Redis的工具(客户端) * @return */ def getUserRecentlyRating(num: Int, uid: Int, jedis: Jedis) = { //Redis中保存的数据格式: //lpush uid:1 1129:2.0 1172:4.0 1263:2.0 1287:2.0 1293:2.0 1339:3.5 1343:2.0 1371:2.5 //.lrange()是因为获取Redis中的数据时,是这样的命令行,EG:192.168.212.21:6379> lrange uid:1 0 5 //其中,start这里是0,stop这里是5 //注意:jedis是Java里面的,.map()是Scala里面的东西,如果要将java 里面的东西用到Scala里面,需要引入: // import scala.collection.JavaConversions._ jedis.lrange("uid" + uid.toString, 0, num-1).map { //1129:2.0 item => val attr = item.split("\\:") (attr(0).trim.toInt, attr(1).trim.toDouble) }.toArray } /** * 取出和当前电影r相似电影的前num个 * * @param num * @param mid * @param uid * @param simMovies * @param mongoConfig */ def getTopSimMovies(num: Int, mid: Int, uid: Int, simMovies: collection.Map[Int, Map[Int, Double]])(implicit mongoConfig: MongoConfig) = { //1.从共享变量的电影相似度矩阵中获取和当前电影的所有相似电影 //.get(mid)之后的allSimMovies的数据类型是:Option[Map[Int,Double]] //.get之后allSimMovies的数据类型变成:Map[Int,Double] val allSimMovies = simMovies.get(mid).get.toArray //再.toArray之后allSimMovies的数据类型是:Array[(Int,Double)] //2.获取用户已经观看过的电影 //从Ratings表里面取出 val ratingExist = ConnHelper.mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION) .find(MongoDBObject("uid" -> uid)).toArray.map { item => item.get("mid").toString.toInt } //3.过滤掉已经评分的电影、排序输出(降序排序) allSimMovies.filter(x => !ratingExist.contains(x._1)).sortWith(_._2 > _._2).take(num) .map(x => x._1) } /** * 计算待选电影的推荐分数 * * @param simMovies 电影的相似度矩阵(历史数据) * @param userRecentlyRatings 用户最近对电影的评分-20个 * @param topSimMovies 当前电影最相近的电影-20个 */ def computMovieScores(simMovies: collection.Map[Int, Map[Int, Double]], userRecentlyRatings: Array[(Int, Double)], topSimMovies: Array[Int]) = { //保存每一个待选电影和最近评分的每个电影的权重得分 val score = ArrayBuffer[(Int, Double)]() //保存每一个电影的增强因子数 //Key-mid ,Value-有多少个 val increMap = mutable.HashMap[Int, Int]() //保存每一个电影的减弱因子数 //Key-mid ,Value-有多少个 val decreMap = mutable.HashMap[Int, Int]() //用户最近的评分 和 当前电影最相近的电影 要做 双重for循环 //topSimMovies对应图中的A(B),userRecentlyRatings的对应图中的X Y Z for (topSimMovie <- topSimMovies; userRecentlyRating <- userRecentlyRatings) { val simScore = getMoviesSimScore(simMovies, userRecentlyRating._1, topSimMovie) if (simScore > 0.6) { //score也就是公式中除号上面和号右侧的部分 score += ((topSimMovie, simScore * userRecentlyRating._2)) if (userRecentlyRating._2 >= 3) { //增强因子起作用 increMap(topSimMovie) = increMap.getOrDefault(topSimMovie, 0) + 1 }else{
//减弱因子起作用
decreMap(topSimMovie) = decreMap.getOrDefault(topSimMovie,0) + 1
} } } score.groupBy(_._1).map { case (mid, sims) => (mid, sims.map(_._2).sum / sims.length + log(increMap(mid)) - log(decreMap(mid)) ) }.toArray //变成一个数组保存 } /** * 自写log()--实现lg() * * @param m * @return */ def log(m: Int) = { math.log(m) / math.log(10) //按照规定的公式来的话这里应该写log(10) } /** * 获取电影之间的相似度 * * @param simMovies 和之前电影p最相似的电影集合 * @param userRatingMovie 用户最近给最近电影的评分中的一个 * @param topSimMovie 和当前电影最相似的电影集合中的一个 */ def getMoviesSimScore(simMovies: collection.Map[Int, Map[Int, Double]], userRatingMovie: Int, topSimMovie: Int) = { simMovies.get(topSimMovie) match { //模式匹配 case Some(sim) => sim.get(userRatingMovie) match { case Some(score) => score //注意写Some,这样最后得出结果的数据类型才会和simMovies里面的相同,都是Double case None => 0.0 //None是Some的对立面 } case None => 0.0 } } /** * 向数据库中写入信息 * * @param uid * @param streamRecs * @param mongoConfig */ def saveRecsToMongoDB(uid: Int, streamRecs: Array[(Int, Double)])(implicit mongoConfig: MongoConfig) = { val streamRecsCollect = ConnHelper.mongoClient(mongoConfig.db)(MONGODB_STREAM_RECS_COLLECTION) //先删除 streamRecsCollect.findAndRemove(MongoDBObject("uid" -> uid)) //再插入 //将数据从(Int,Double)(Int,Double)(Int,Double)(Int,Double) //转换成Int:Double|Int:Double|Int:Double|Int:Double streamRecsCollect.insert(MongoDBObject("uid" -> uid, "recs" -> streamRecs.map(x => x._1 + ":" + x._2).mkString("|"))) println("save to mongodb") } } }
启动MongoDB
[root@tjx1 mongodb-linux-x86_64-rhel62-3.4.3]# ./bin/mongod -config ./data/mongodb.conf
启动Zookeeper
[root@tjx1 zookeeper-3.4.10]# ./bin/zkServer.sh start
启动Kafka
[root@tjx1 kafka_2.12-0.10.2.1]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
启动Redis
[root@tjx1 redis]# ./bin/redis-server ./redis.conf
查看进程:
[root@tjx1 redis]# ps -ef | grep redis
root 2734 1 0 10:28 ? 00:00:00 ./bin/redis-server 0.0.0.0:6379
root 2754 2342 0 10:29 pts/0 00:00:00 grep --color=auto redis
启动Kafka的生产者-producer
[root@tjx1 kafka_2.12-0.10.2.1]# ./bin/kafka-console-producer.sh --broker-list 192.168.212.21:9092 --topic recom
启动程序
在kafka的producer端输入几行数据:1|2|5.0|1564412033
然后查看IDEA里打印出来的信息:
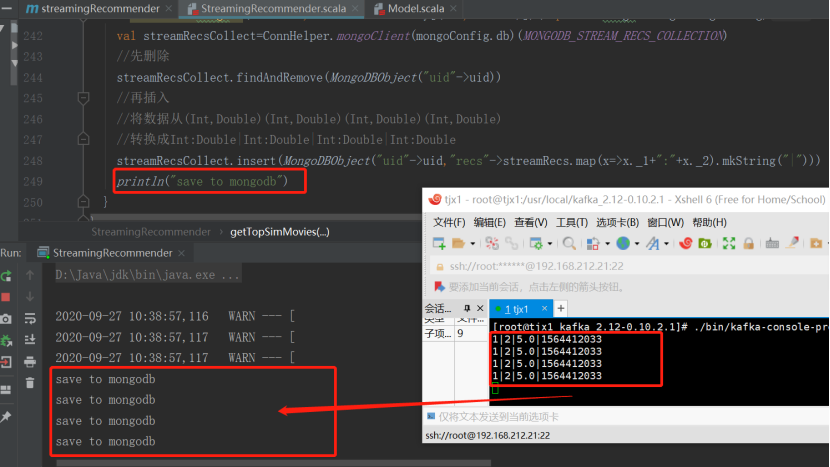
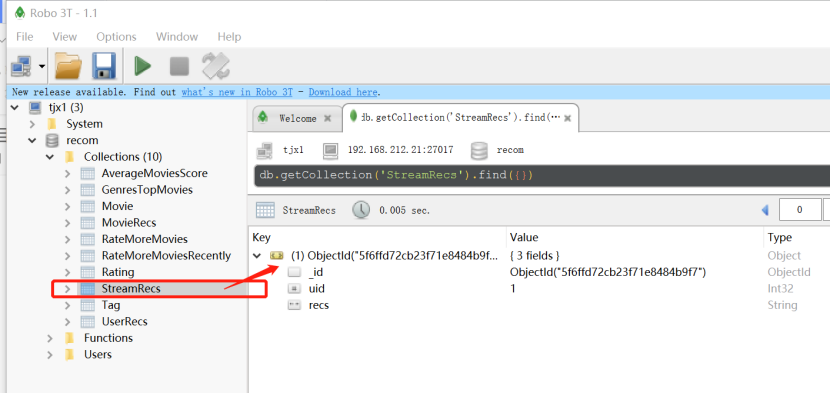
接着查看MongoDB中新加入的表:
备注:
实时推荐的表是在表StreamRecs
离线推荐的表是在表UserRecs
实时和离线之间的再做的一层过滤放在Java后台进行-交给上层应用(大数据这边只做两个表即可),因为如果也放在实时推荐里面,再对比之后如果出现结果不统一的情况又需要再做一次实时推荐计算,又需要消耗一些时间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号