
电影推荐系统-[实时推荐部分](三)编写代码--实时推荐(2) 【编写Scala代码--先实现Kafka连接Spark Streaming】
Posted on 2020-09-27 18:43 MissRong 阅读(322) 评论(0) 收藏 举报电影推荐系统-[实时推荐部分](三)编写代码--实时推荐(2)
【编写Scala代码--先实现Kafka连接Spark Streaming】
package streamingRecommender
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/25
*/
object StreamingRecommender {
def main(args: Array[String]): Unit = {
//一、声明Spark的环境------------------------------------------------------------------------------
val config=Map(
"spark.cores"->"local[3]",
"kafka.topic"->"recom"
)
val sparkConf=new SparkConf().setAppName("StreamingRecommmender").setMaster(config("spark.cores"))
val spark=SparkSession.builder().config(sparkConf).getOrCreate()
val sc=spark.sparkContext
//使用SparkStreaming将连续的数据转化成不连续的RDD
val ssc=new StreamingContext(sc,Seconds(2)) //指定采样时间:2秒
//存放Kafka的配置信息(基本上不太会改动)**************************************
val kafkaPara=Map(
"bootstrap.servers" -> "192.168.212.21:9092", //Kafka的IP
"key.deserializer" -> classOf[StringDeserializer], //编码解码工具
"value.deserializer" -> classOf[StringDeserializer], //编码解码工具
"group.id" -> "recomgroup" //消费者组--注意:需要在Kafka的配置文件-server.properties里进行配置
)
//二、连接Kafka将数据获取进来------------------------------------------------------------------------------
//1.连接Kafka
//1)LocationStrategies--从...取数据,一般用:PreferConsistent(一般都是固定的)
//查看其原理啥的参考:https://blog.csdn.net/Dax1n/article/details/61917718
//2)ConsumerStrategies:和消费有关的
//Subscribe后面最好加上:[String,String](不加也可)
val kafkaStream=KafkaUtils.createDirectStream(ssc,LocationStrategies.PreferConsistent,ConsumerStrategies.Subscribe[String,String](Array(config("kafka.topic")),kafkaPara))
//三、接收评分流--UID | MID | Score | TIMESTAMP----------------------------------------------------------------
val ratingStream=kafkaStream.map{
case msg=>
val attr=msg.value().split("\\|") //注意:Scala和java 里面符号"|"都需要用转义符进行转义
println("get data from kafka ---------ratingStream")
(attr(0).toInt,attr(1).toInt,attr(2).toDouble,attr(3).toInt) //将数据重新组织了一下--用户ID,电影ID,评分,时间戳
}
ratingStream.foreachRDD{
rdd=>
rdd.map{
case(uid,mid,score,timestamp)=>
println("get data from kafka ")
//实时计算逻辑的实现
//1)从redis中获取当前最近的M次评分
//2)获取电影P最相似的K个电影
//3)计算待选电影的推荐优先级
//4)将数据保存到MongoDB中
}.count() //触发计算才有显示,对count()的结果我们不感兴趣,只是用他触发计算
}
//运行Spark Streaming 启动流式计算
ssc.start()
//不会停的,等待手动停止
ssc.awaitTermination()
}
}
启功Kafka--需要先启动Zookeeper
因为kafka将其数据都存在Zookeeper中
[root@tjx1 zookeeper-3.4.10]# ./bin/zkServer.sh start
[root@tjx1 zookeeper-3.4.10]# ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: standalone
接下来启动Kafka:
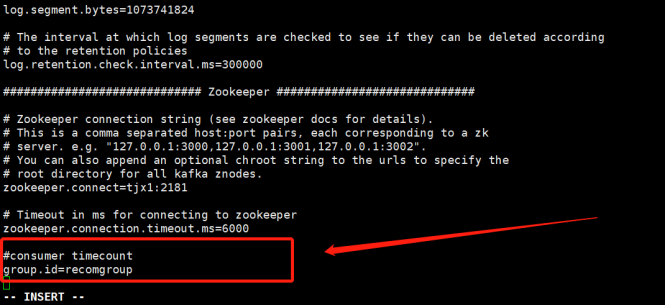
注意,因为程序中写的:"group.id" -> "recomgroup",
所以,要在kafka配置文件server.properties里进行配置,添加如下内容:
#consumer timecount
group.id=recomgroup
[root@tjx1 zookeeper-3.4.10]# cd /usr/local/kafka_2.12-0.10.2.1/
[root@tjx1 kafka_2.12-0.10.2.1]# ./bin/kafka-server-start.sh -daemon ./config/server.properties
查看进程-jps:
[root@tjx1 kafka_2.12-0.10.2.1]# jps
2916 Jps
2854 Kafka
2329 QuorumPeerMain
启动Kafka的生产者
[root@tjx1 kafka_2.12-0.10.2.1]# ./bin/kafka-console-producer.sh --broker-list 192.168.212.21:9092 --topic recom
启动Kafka的消费者
[root@tjx1 kafka_2.12-0.10.2.1]# ./bin/kafka-console-consumer.sh --bootstrap-server 192.168.212.21:9092 --topic recom
发现有报错:
![]()
解决:
再次修改配置文件:server.properties
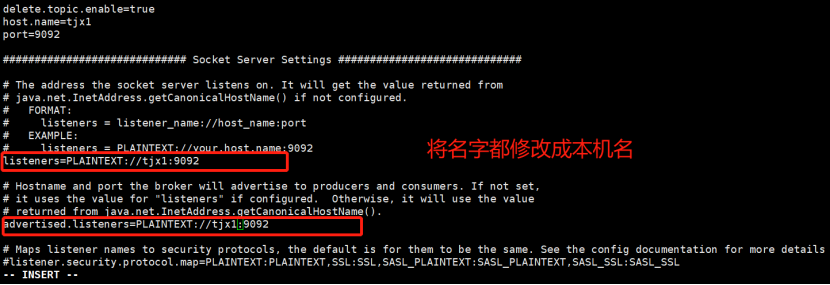
这样Kafka就能监听得到了。
然后重新启动Zookeeper、Kafka、启动其生产者和消费者
然后再向里面写数据:

然后关闭Kafka的消费者、启动程序
然后再在producer对话框内输入数据信息:1|2|5.0|1564412033
就能在程序运行日志内看到打印出的结果:
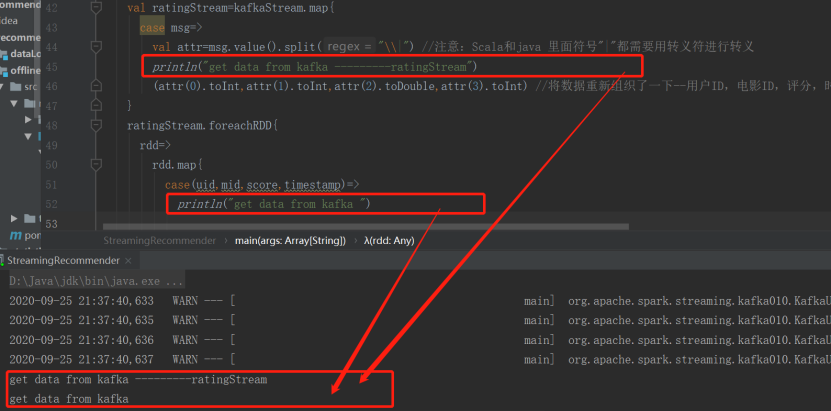
注意上面程序中的:
}.count() //触发计算才有显示,对count()的结果我们不感兴趣,只是用他触发计算

 浙公网安备 33010602011771号
浙公网安备 33010602011771号