
电影推荐系统-[实时推荐部分](三)编写代码--计算两个电影之间的余弦相似度
依然在离线推荐代码包的离线推荐算法类-offlineRecommender里完成,因为求电影的相似度矩阵需要用到之前求出的推荐的电影集合。
在原来的代码基础上再增添求计算电影相似度矩阵的部分:
//5.计算电影相似度矩阵------------------------------------------------------------
//1)获取电影的50维向量的特征矩阵(productFeatures)-S(q属于S)
//DoubleMatrix就是来自org.jblas包
//movieFeatures是RDD[(Int-mid,DoubleMatrix-feature)],这两列数据
val movieFeatures=model.productFeatures.map{
case (mid,features)=>(mid,new DoubleMatrix(features))
}
//2)自己和自己做笛卡儿积--求出每一个电影和所有电影的相似性
val movieRecs= movieFeatures.cartesian(movieFeatures) //过滤前--movieRecs:RDD[(Int,DoubleMatrix),(Int,DoubleMatrix)]
.filter {
case (a, b) => a._1 != b._1
}.map { //3)求余弦相似度、格式变换
case (a, b) =>
val simScore = this.consinSim(a._2, b._2) //电影相似性评分--余弦相似性,自定义方法
(a._1, (b._1, simScore)) //(电影1,(电影2,电影1和电影2的相似度))
} //(Int,(Int,Double))
.filter(_._2._2 > 0.6) //4)取出相似度大于0.6的数据(余弦值越接近1,就越相似)
.groupByKey() //5)分组 (Int,Iterable[(Int,Double)])
.map { //6)转换成MongoDB可以存储的形式-通过自定义数据类
case (mid, items) =>
//自定义数据类
MoviesRecs(mid, items.toList.map(x => Recommendation(x._1, x._2)))
}.toDF() //7)转成DataFrame
//8)写入MongoDB
.write
.option("uri",mongoConfig.uri)
.option("collection",MONGO_MOVIE_RECS)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
//6.关闭Spark---------------------------------------------------------------------
spark.close()
此类中自定义方法-计算余弦相似度部分:
/**
* 计算两个电影间的余弦相似度
* @param movie1 在求余弦相似度的时候,将其看成一个向量
* @param movie2 在求余弦相似度的时候,将其看成一个向量
* @return
*/
def consinSim(movie1: DoubleMatrix,movie2: DoubleMatrix):Double = {
//点乘:dot()、模:norm2()
movie1.dot(movie2)/(movie1.norm2()* movie2.norm2())
}
自定义数据类里面添加的部分:
/**
* 定义电影相似度
* @param mid
* @param recs
* 注:Seq-Sequence是一个特质,可以理解成一个列表;Recommendation是一个自定义实现类
*/
case class MoviesRecs(mid:Int,recs:Seq[Recommendation])
其中,Recommendation类是之前就有实现过的,内容如下:
/**
* recs的二次封装数据类
* @param mid
* @param res
*/
case class Recommendation(mid:Int,res:Double)
启动MongoDB、Robo查看结果:
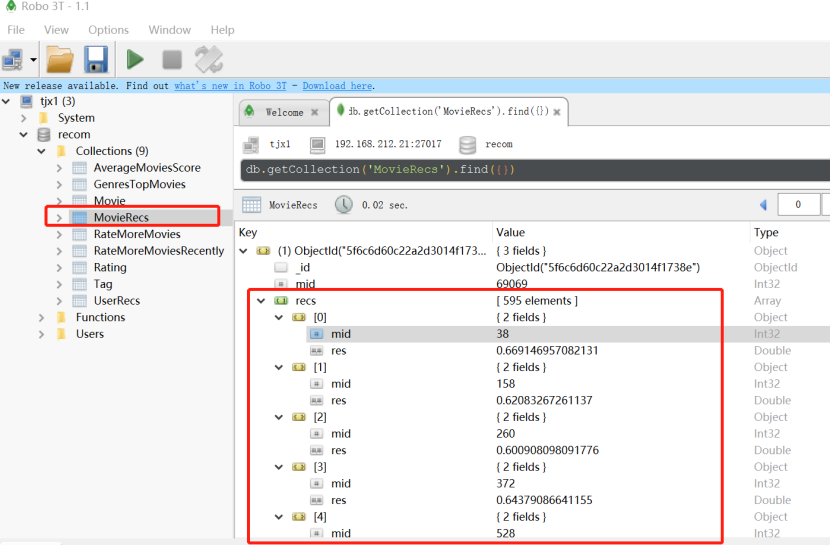
过程图 (较之前离线推荐多了求电影相似度矩阵的部分):


 浙公网安备 33010602011771号
浙公网安备 33010602011771号