
电影推荐系统-[离线推荐部分](四)【优化ALS】


ALS-(交替最小二乘法)算法是2008年以来,用的比较多的协同过滤算法。它已经集成到Spark的Mllib库中,使用起来比较方便。
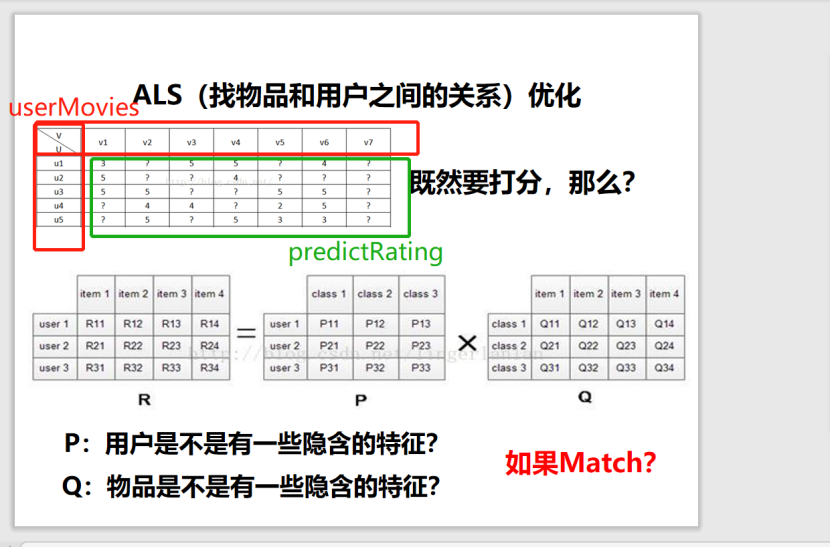
从协同过滤的分类来说,ALS算法属于User-Item CF,也叫做混合CF。它同时考虑了User和Item两个方面。
用户和商品的关系,可以抽象为如下的三元组:<User,Item,Rating>。其中,Rating是用户对商品的评分,表征用户对该商品的喜好程度。
假设我们有一批用户数据,其中包含m个User和n个Item,则我们定义Rating矩阵,其中的元素表示第u个User对第i个Item的评分。
新建一个类---Scala代码:
package offlineRecommender
import breeze.numerics.sqrt
import org.apache.spark.SparkConf
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/21
* 优化ALS
* 原理:遍历所有业务范围内的取值情况,找到最优的模型
* val(rank,iteration,lambna)=(50,5,0.01)
* 模型的评价:预测值和实际的误差值最小
*/
object ALSTrainer {
def main(args: Array[String]): Unit = {
val conf=Map(
"spark.core"->"local[2]",
"mongo.uri"->"mongodb://192.168.212.21:27017/recom",
"mongo.db"->"recom"
)
//一、创建Spark环境
val sparkConf=new SparkConf().setAppName("ALSTrainer").setMaster(conf("spark.core"))
val spark=SparkSession.builder().config(sparkConf).getOrCreate()
//二、加载评分数据
import spark.implicits._
val mongoConfig=MongoConfig(conf("mongo.uri"),conf("mongo.db"))
val ratingRDD=spark
.read
.option("uri",mongoConfig.uri)
.option("collection",OfflineRecommender.MONGODB_RATING_COLLECTION)
.format("com.mongodb.spark.sql")
.load()
.as[MovieRating]
.rdd
.map(rating=>Rating(rating.uid,rating.mid,rating.score))
//三、输出最优的参数
adjectALSParams(ratingRDD)
//四、关闭Spark
spark.close()
}
/**
* 自定义函数--输出最优参数
*
* @param ratingRDD
*/
def adjectALSParams(ratingRDD: RDD[Rating]) = {
//迭代的次数不用太在意,因为他们和自身机器的资源有关
//rank:特征维度
//lambda:跨度
val result=for(rank<-Array(30,40,50,60,70);lambda<-Array(1,0.1,0.01))
yield{
//训练模型
val model=ALS.train(ratingRDD,rank,5,lambda)
//获取模型均方根误差
val rmse=getRmse(model,ratingRDD)
(rank,lambda,rmse)
}
//打印出误差最小的:
//用第三个Double进行排序,然后得出第一个--最优参数
print(result.sortBy(_._3).head)
}
/**
* 自定义函数--获取模型均方根误差函数
* @param model
* @param ratingRDD
*/
def getRmse(model: MatrixFactorizationModel, ratingRDD: RDD[Rating]) = {
//需要构造userProductsRDD--预测一下用户打的分数
//1)先通过从MongoDB里面取出的ratingRDD得到第一行(商品)和第一列(用户)的数据
val userMovies=ratingRDD.map(item=>(item.user,item.product))
//2)再通过协同过滤算法算出预期的ratingRDD
val predictRating=model.predict(userMovies)
//3)真实写的分数-从MongoDB里面取的
val real=ratingRDD.map(item=>((item.user,item.product),item.rating))
//4)预测的分数-预测的数据-predictRating
val predict=predictRating.map(item=>((item.user,item.product),item.rating))
//5)计算误差
//最外面的sqrt--开平方
sqrt(
//join()--合并实际表和预测表(是为了将实际偏好值和预测偏好值放在一起好做差)
real.join(predict) //得到的是:(userId-int,produceId-int),(真实值-double,预测值-double)
.map {
//模式匹配
case ((uid, mid), (real, pre)) =>
val err = real - pre //计算误差
err * err //误差的平方
}.mean() //求平均
)
}
}
自定义数据类:
package offlineRecommender
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/4
* 数据格式转换类
* ---------------电影表------------------------
* 1
* Toy Story (1995)
*
* 81 minutes
* March 20, 2001
* 1995
* English
* Adventure|Animation|Children|Comedy|Fantasy
* Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn
* John Lasseter
*/
case class Movie(val mid:Int,val name:String,val descri:String,
val timelong:String,val cal_issue:String,val shoot:String,
val language:String,val genres :String,val actors:String,val directors:String)
/**
* -----用户对电影的评分数据集--------
* 1,31,2.5,1260759144
*/
case class MovieRating(val uid:Int,val mid:Int,val score:Double,val timastamp:Int)
/**
* --------用户对电影的标签数据集--------
* 15,339,sandra 'boring' bullock,1138537770
*/
case class Tag(val uid:Int,val mid:Int,val tag:String,val timestamp:Int)
/**
*
* MongoDB配置对象
* @param uri
* @param db
*/
case class MongoConfig(val uri:String,val db:String)
/**
* ES配置对象
* @param httpHosts
* @param transportHosts:保存的是所有ES节点的信息
* @param clusterName
*/
case class EsConfig(val httpHosts:String,val transportHosts:String,val index:String,val clusterName:String)
/**
* recs的二次封装数据类
* @param mid
* @param res
*/
case class Recommendation(mid:Int,res:Double)
/**
* Key-Value封装数据类
* @param genres
* @param recs
*/
case class GenresRecommendation(genres:String,recs:Seq[Recommendation])
//注:Seq-Sequence是一个特质,Recommendation是一个实现类
case class UserRecs(uid:Int,recs:Seq[Recommendation])
启动MongoDB、执行程序
[root@tjx1 mongodb-linux-x86_64-rhel62-3.4.3]# ./bin/mongod -config ./data/mongodb.conf
执行结果:

最后一个就是采用最优参数后,预测值和实际值之间的误差
对于程序中定义的两个常量的解释

 浙公网安备 33010602011771号
浙公网安备 33010602011771号