
电影推荐系统-[离线统计部分](二)创建Package、类+编写代码(1)【统计评分最多的电影】
Posted on 2020-09-20 09:08 MissRong 阅读(215) 评论(0) 收藏 举报电影推荐系统-[离线统计部分](二)创建Package、类+编写代码
创建两个类-实际实现类、调用类
1)统计评分最多的电影
将上一个子项目(数据库+搜索服务器部分)中的Modle类拷贝过来
package staticRecommender
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/4
* 数据格式转换类
* ---------------电影表------------------------
* 1
* Toy Story (1995)
*
* 81 minutes
* March 20, 2001
* 1995
* English
* Adventure|Animation|Children|Comedy|Fantasy
* Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn
* John Lasseter
*/
case class Movie(val mid:Int,val name:String,val descri:String,
val timelong:String,val cal_issue:String,val shoot:String,
val language:String,val genres :String,val actors:String,val directors:String)
/**
* -----用户对电影的评分数据集--------
* 1,31,2.5,1260759144
*/
case class Rating(val uid:Int,val mid:Int,val score:Double,val timastamp:Int)
/**
* --------用户对电影的标签数据集--------
* 15,339,sandra 'boring' bullock,1138537770
*/
case class Tag(val uid:Int,val mid:Int,val tag:String,val timestamp:Int)
/**
*
* MongoDB配置对象
* @param uri
* @param db
*/
case class MongoConfig(val uri:String,val db:String)
/**
* ES配置对象
* @param httpHosts
* @param transportHosts:保存的是所有ES节点的信息
* @param clusterName
*/
case class EsConfig(val httpHosts:String,val transportHosts:String,val index:String,val clusterName:String)
Scala代码:
(1)实际实现类-StatisticsAlgorithm.scala
package staticRecommender
import org.apache.spark.sql.SparkSession
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/18
* 离线统计方法实现(存放所有离线统计实现代码)
*/
object StatisticsRecommender {
//定义常见的表名
val RATE_MORE_MOVIES="RateMoreMovies"
val RATE_MORE_MOVIES_RECENTLY="RateMoreMoviesRecently"
val AVERAGE_MOVIES_SCORE="AverageMoviesScore"
val GENRES_TOP_MOVIES="GenresTopMovies"
//一、统计评分最多的电影
//注意:没有取前几个,所以直接统计出来就好
def rateMore(spark:SparkSession)(implicit mongoConfig:MongoConfig):Unit={
val rateMoreDF = spark.sql("select mid,count(1) as count from ratings group by mid order by count desc")
//将统计好的写出去
rateMoreDF.write
.option("uri",mongoConfig.uri)
.option("collection",RATE_MORE_MOVIES)
.mode("overwrite")
.format("com.mongodb.spark.sql")
.save()
}
}
(2)调用类-StatisticsApp.scala
package staticRecommender
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/18
* 离线统计的main方法(只负责调用方法类)
* 在工作中也是这样的,将入口程序和实现的程序分开,以免混淆
*
* 一、数据流程
* spark读取MongoDB中的数据,进行离线统计后再将结果写入MongoDB中
* 二、统计值
* 1.评分最多电影:
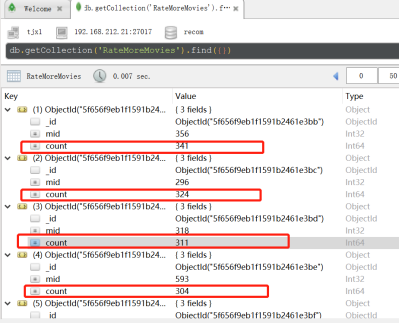
* 获取所在历史数据中,评分个数最多的电影的集合,统计每个电影评分个数 -->存入的MongoDB表名:RateMoreMovies
* 2.近期热门电影:
* 按照月来统计,这个月中,评分最多的电影我们认为是热门电影,统计每个月中每个电影的评分总量 -->RateMoreRecentlyMovies
* 3.电影平均得分
* 把每个电影所有的用户得分进行平均,计算出每个电影的平均得分--> AverageMovies
* 4.每种类别电影的Top10
* 首先,将每种类别的电影中评分最高的10个电影拿出来-->GenresTopMovies
* 注意:一个电影可能属于多个类别,而且他的结果还依赖于 3 的结果
*/
object StatisticsApp extends App {
//声明表
val RATING_COLLECTION_NAME="Rating"
val MOVIE_COLLECTION_NAME="Movie"
//一、创建运行时的环境
val params=scala.collection.mutable.Map[String,Any]()
//保证CPU的核数大于等于2,"local[2]"表示开启两个线程
//一个线程用于读取数据,一个线程用于计算处理数据
params +="spark.cores"->"local[2]"
params+="mongo.uri"->"mongodb://192.168.212.21:27017/recom"
params+="mongo.db"->"recom"
//spark环境
val conf=new SparkConf().setAppName("StatisticsApp").setMaster(params("spark.cores").asInstanceOf[String])
val spark= SparkSession.builder().config(conf).getOrCreate()
//二、初始化MongoDB对象
//传入uri,String类型
//之所以定义成隐式参数,是想便于后面的方法去调用
implicit val mongoConfig=new MongoConfig(params("mongo.uri").asInstanceOf[String],params("mongo.db").asInstanceOf[String])
//三、读表
// 1.读取mongoDB中的数据-ratings表的
import spark.implicits._
val ratings= spark
.read
.option("uri", mongoConfig.uri)
.option("collection",RATING_COLLECTION_NAME) //要读的表名
.format("com.mongodb.spark.sql")
.load()
.as[Rating] //将DataFrame转换成DataSet,这样便于执行RDD操作,参考:https://www.cnblogs.com/liuxinrong/articles/13341784.html
.cache() //将其随手存入缓存
//四、将读到的数据信息注册成临时的视图
ratings.createOrReplaceTempView("ratings")
//五、统计评分最多的电影
StatisticsRecommender.rateMore(spark)
//六、随手关闭
ratings.unpersist()
spark.close()
}
启动MongoDB
[root@tjx1 mongodb-linux-x86_64-rhel62-3.4.3]# ./bin/mongod --config ./data/mongodb.conf
然后用Robo工具连接
执行代码之后查看Robo工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号