
电影推荐项目-[数据库+搜索服务器部分]-写代码(二)Scala代码实现(4)【将数据写入ES】
Posted on 2020-09-15 20:45 MissRong 阅读(439) 评论(0) 收藏 举报写代码(二)Scala代码实现(4)【将数据写入ES】
Scala代码
自定义类
package test
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/4
* 数据格式转换类
* ---------------电影表------------------------
* 1
* Toy Story (1995)
*
* 81 minutes
* March 20, 2001
* 1995
* English
* Adventure|Animation|Children|Comedy|Fantasy
* Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn
* John Lasseter
*/
case class Movie(val mid:Int,val name:String,val descri:String,
val timelong:String,val cal_issue:String,val shoot:String,
val language:String,val genres :String,val actors:String,val directors:String)
/**
* -----用户对电影的评分数据集--------
* 1,31,2.5,1260759144
*/
case class Rating(val uid:Int,val mid:Int,val score:Double,val timastamp:Int)
/**
* --------用户对电影的标签数据集--------
* 15,339,sandra 'boring' bullock,1138537770
*/
case class Tag(val uid:Int,val mid:Int,val tag:String,val timestamp:Int)
/**
*
* MongoDB配置对象
* @param uri
* @param db
*/
case class MongoConfig(val uri:String,val db:String)
/**
* ES配置对象
* @param httpHosts
* @param transportHosts:保存的是所有ES节点的信息
* @param clusterName
*/
case class EsConfig(val httpHosts:String,val transportHosts:String,val index:String,val clusterName:String)
DataLogs类
package test
import java.net.InetAddress
import com.mongodb.casbah.commons.MongoDBObject
import com.mongodb.casbah.{MongoClient, MongoClientURI}
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest
import org.elasticsearch.action.admin.indices.exists.indices.IndicesExistsRequest
import org.elasticsearch.common.settings.Settings
import org.elasticsearch.common.transport.InetSocketTransportAddress
import org.elasticsearch.transport.client.PreBuiltTransportClient
/**
* @Author : ASUS and xinrong
* @Version : 2020/9/4
*
* Spark SQL--初始化数据
* Spark SQL数据导入MongoDB
*/
object DataLoader {
//---------- MongoDB 中的表 Collection -------------------
// Moive在MongoDB中的Collection名称【表】
val MOVIES_COLLECTION_NAME = "Movie"
// Rating在MongoDB中的Collection名称【表】
val RATINGS_COLLECTION_NAME = "Rating"
// Tag在MongoDB中的Collection名称【表】
val TAGS_COLLECTION_NAME = "Tag"
//ES TYPE 名称
val ES_TAG_TYPE_NAME = "Movie"
//用正则表达式表示ES的port信息
//一个普通的字符串.r之后就变成了正则表达式
//(.+)-->任意多个字符
//(\\d+)-->数字有多位
val ES_HOST_PORT_REGEX = "(.+):(\\d+)".r
def main(args: Array[String]): Unit = {
//封装各个文件路径
val DATAFILE_MOVIES="D:\\tmp_files\\reco_data\\small\\movies.csv"
val DATAFILE_RATINGS="D:\\tmp_files\\reco_data\\small\\ratings.csv"
val DATAFILE_TAGS="D:\\tmp_files\\reco_data\\small\\tags.csv"
val params=scala.collection.mutable.Map[String,Any]()
params+="spark.cores"->"local"
//---------------- 关于 MongoDB 的声明 -------------------------
params+="mongo.uri"->"mongodb://192.168.212.21:27017/recom"
params+="mongo.db"->"recom" //库名-recom
// 定义mongoDB配置对象-隐式对象:
implicit val mongoConfig=new MongoConfig(params("mongo.uri").asInstanceOf[String],
params("mongo.db").asInstanceOf[String]);
//----------------- 关于ES的声明 --------------------------------
params+="es.httpHosts"->"192.168.212.21:9200" //外网访问
params+="es.transportHosts"->"192.168.212.21:9300" //内部端口
params+="es.index"->"recom"
params+="es.cluster.name"->"my-application"
//定义ES配置对象
implicit val esConf=new EsConfig(params("es.httpHosts").asInstanceOf[String],
params("es.transportHosts").asInstanceOf[String],params("es.index").asInstanceOf[String],
params("es.cluster.name").asInstanceOf[String])
//一、声明Spark环境
//1.config--对"local"做一层封装:
val config= new SparkConf().setAppName("DataLoader").setMaster(params("spark.cores").asInstanceOf[String]);
//2.SparkSession
val spark=SparkSession.builder().config(config).getOrCreate()
//二、加载数据集
//1.声明各个数据所在路径(单独拿出来的原因:生产和测试时的路径通常不同,将各个文件的路径放在一起便于修改)
val movieRDD=spark.sparkContext.textFile(DATAFILE_MOVIES)
val ratingRDD=spark.sparkContext.textFile(DATAFILE_RATINGS)
val tagRDD=spark.sparkContext.textFile(DATAFILE_TAGS)
//2.将RDD转换成DataFrame--使用SparkSQL比较好的特性(读入/写出数据的时候很方便)
//知识点参考:https://www.cnblogs.com/liuxinrong/articles/13393309.html
// https://www.cnblogs.com/liuxinrong/articles/13332014.html
//1)import 导入隐式转换
import spark.sqlContext.implicits._
//2)关联数据和Schema
val movieOF=movieRDD.map(
line=>{
//用"\^"分割行数据
val x=line.split("\\^")
//2)定义Schema--通过case class方式(trim是将前后的空格去掉)
Movie(x(0).trim.toInt,x(1).trim,x(2).trim,
x(3).trim,x(4).trim, x(5).trim,x(6).trim,x(7).trim,x(8).trim,x(9).trim)
}
).toDF() //3)RDD转换成DF
val ratingOF=ratingRDD.map(
line=>{
val x=line.split(",")
Rating(x(0).trim.toInt,x(1).trim.toInt,x(2).trim.toDouble,x(3).trim.toInt)
}
).toDF()
val tagOF=tagRDD.map(
line=>{
val x=line.split(",")
Tag(x(0).trim.toInt,x(1).trim.toInt,x(2).trim,x(3).trim.toInt)
}
).toDF()
// movieOF.show() //默认最多展示20行数据
// ratingOF.show(2) //只展示2行结果数据
// tagOF.show()
//--------------------------------------- MongoDB --------------------------------------
//三、将数据写入到MongoDB
storeDataInMongo(movieOF,ratingOF,tagOF)
//------------------------------------ ElasticSearch -----------------------------------
//将movie表和tag表(这两个表中含有文字类的数据)进行合并之后再存入ES
//因为movie和tag表需要相交,所以直接随手就将他们缓存起来
movieOF.cache()
tagOF.cache()
//tag的聚合-agg()
// 需要引入内置的函数库
import org.apache.spark.sql.functions._
//将tag这一列用分隔符“|”分隔开,在起一个新的名字-叫tags
val tagCollectDF=tagOF.groupBy("mid").agg(concat_ws("|",collect_set("tag")).as("tags"))
val esMovieDF= movieOF.join(tagCollectDF, Seq("mid", "mid"), "left")
.select("mid","name","descri","timelong","cal_issue","shoot","language","genres","actors","directors","tags")
//展示一下Join之后的表
// esMovieDF.show()
//自定义写入ES的方法
storeDataInES(esMovieDF)
//使用(cache())完之后最好将他们unpersist()掉
movieOF.unpersist()
tagOF.unpersist()
//关闭Spark
spark.close()
}
/**
* MongoDB方法
* 隐式参数:mongoConfig
*/
def storeDataInMongo(movieOF: DataFrame, ratingOF: DataFrame, tagOF: DataFrame)(implicit mongoConfig: MongoConfig)= {
//1.创建到MongoDB的连接去操作MongoDB--用到的是传入的隐式参数
val mongoClient=MongoClient(MongoClientURI(mongoConfig.uri)) //mongoURI是MongoDB的地址
//对于MongoDB的删表操作--删除某个库下的表
//MongoDB的驱动会自动创建Collection(表),这个和ES不同
mongoClient(mongoConfig.db)(MOVIES_COLLECTION_NAME).dropCollection()
mongoClient(mongoConfig.db)(RATINGS_COLLECTION_NAME).dropCollection()
mongoClient(mongoConfig.db)(TAGS_COLLECTION_NAME).dropCollection()
//2.写入MongoDB
movieOF.write
.option("uri",mongoConfig.uri)
.option("collection", MOVIES_COLLECTION_NAME) //表名
.mode("overwrite") //采用overwrite的写入方式可以不用先删除表格,先删除(双重保险)的话也可以
.format("com.mongodb.spark.sql") //驱动的名字
.save() //保存
ratingOF.write
.option("uri",mongoConfig.uri)
.option("collection", RATINGS_COLLECTION_NAME)
.mode("overwrite")
.format("com.mongodb.spark.sql") //驱动的名字
.save() //保存
tagOF.write
.option("uri",mongoConfig.uri)
.option("collection", TAGS_COLLECTION_NAME)
.mode("overwrite")
.format("com.mongodb.spark.sql") //驱动的名字
.save() //保存
//3.创建mongodb索引--写完数据之后就创建索引
mongoClient(mongoConfig.db)(MOVIES_COLLECTION_NAME).createIndex(MongoDBObject("mid"->1)) //针对mid列创建索引
mongoClient(mongoConfig.db)(RATINGS_COLLECTION_NAME).createIndex(MongoDBObject("mid"->1)) //针对mid列和uid列创建索引
mongoClient(mongoConfig.db)(RATINGS_COLLECTION_NAME).createIndex(MongoDBObject("uid"->1))
mongoClient(mongoConfig.db)(TAGS_COLLECTION_NAME).createIndex(MongoDBObject("mid"->1)) //针对mid列和uid列创建索引
mongoClient(mongoConfig.db)(TAGS_COLLECTION_NAME).createIndex(MongoDBObject("uid"->1))
//4.关闭MongoDB的连接
mongoClient.close()
}
/**
* ElasticSearch方法
* 隐式参数:esConfig(定义ES的配置,并将其以隐式参数的形式传入进来)
*/
def storeDataInES(esMovieDF: DataFrame)(implicit esConf:EsConfig) = {
//1.给要操作的Index取名称--ES中的库名
val indexName=esConf.index
//2.连接ES的配置
val settings=Settings.builder().put("cluster.name",esConf.clusterName).build()
//3.创建连接ES的客户端
val esClient=new PreBuiltTransportClient(settings)
//4.设置ES集群的IP(集群解析)
//ES对象中的TransportHost属性保存所有ES节点信息,
// 以下方法将送有节点的信息遍历出来
//"192.168.109.141:9300,192.168.109.142:9300,192.168.109.143:9300"
esConf.transportHosts.split(",")
.foreach{
//Scala中正则而表达式的用法:case+正则表达式
//192.168.212.21:9300
case ES_HOST_PORT_REGEX(host:String,port:String) =>
esClient.addTransportAddresses(new InetSocketTransportAddress(InetAddress.getByName(host),port.toInt))
}
//先判断,如果Index已经存在,就先删除
if(esClient.admin().indices().exists(new IndicesExistsRequest(indexName)).actionGet.isExists){
//存在Index
//删除
esClient.admin().indices().delete(new DeleteIndexRequest(indexName))
}
//5.创建Index
esClient.admin().indices().create(new CreateIndexRequest(indexName))//6.创建Type
//将indexName--库名"recom"和另外一个变量--表名"Movie"拼到一起
val movieTypeName=s"$indexName/$ES_TAG_TYPE_NAME"
//失效时间为100秒
val movieOption=Map("es.nodes"->esConf.httpHosts,"es.http.timeout"->"100m" ,"es.mappting.id"->"mid")
//7.写数据
esMovieDF.write
.options(movieOption)
.mode("overwrite")
.format("org.elasticsearch.spark.sql")
.save(movieTypeName)
}
}
启动ES
注意切换用户(不能用root用户进行)
[root@tjx1 elasticsearch-5.6.2]# su demouser
[demouser@tjx1 elasticsearch-5.6.2]$ ./bin/elasticsearch
用ElasticSearch插件连接:

运行Scala代码:
注意:此时MongoDB和ES都是启动的
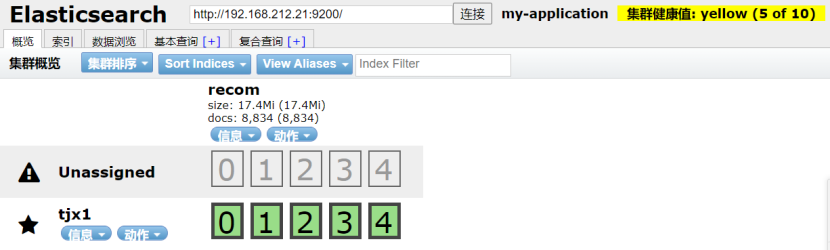
然后刷新ES可视化插件:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号