
电影推荐项目-[数据库+搜索服务器部分]-写代码(二)Scala代码实现(3)【ElasticSearch--将数据输入】
Posted on 2020-09-15 20:17 MissRong 阅读(151) 评论(0) 收藏 举报写代码(二)Scala代码实现(3)【ElasticSearch--将数据输入】
(1)合并记录过程举例解释:
tags:
68,2174,music,1249808064
68,2174,weird,1249808102
68,8623,Steve Martin,1249808497
movies:
68^French Twist (Gazon maudit) (1995)^ ^95 minutes^August 5, 2003^1995^Français|Español ^Comedy|Romance ^Victoria Abril|Josiane Balasko|Alain Chabat|Ticky Holgado|Catherine Hiegel|Katrine Boorman|Telsche Boorman|Véronique Barrault|Victoria Abril|Josiane Balasko|Alain Chabat|Ticky Holgado|Catherine Hiegel ^Josiane Balasko
+
聚合的tag- tags
tag加工:
68 music|weird|Steve
(2)关于两个表的合并--Scala代码:
//------------------------------------ ElasticSearch -----------------------------------
//将movie表和tag表(这两个表中含有文字类的数据)进行合并之后再存入ES
//因为movie和tag表需要相交,所以直接随手就将他们缓存起来
movieOF.cache()
tagOF.cache()
//tag的聚合-agg()
// 需要引入内置的函数库
import org.apache.spark.sql.functions._
//将tag这一列用分隔符“|”分隔开,再起一个新的名字-叫tags
val tagCollectDF=tagOF.groupBy("mid").agg(concat_ws("|",collect_set("tag"))).as("tags")
val esMovieDF=movieOF.join(tagCollectDF,Seq("mid","mid"),"left")
.select("mid","name","descri","timelong","cal_issue","shoot","language","genres","actors","directors","tags")
//展示一下Join之后的表
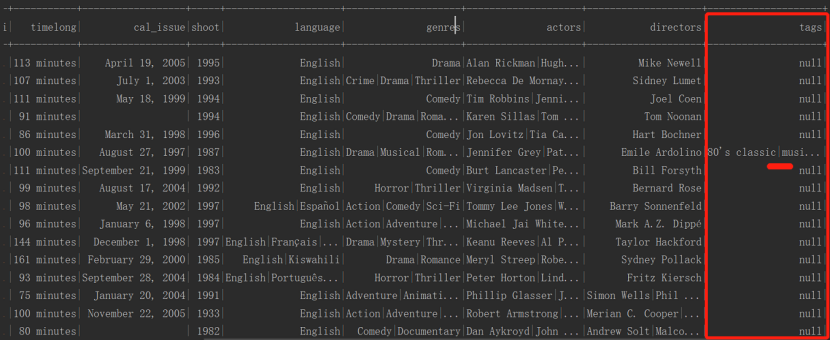
esMovieDF.show()
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号