
Flink(五)Flink开发IDEA环境搭建与测试(3)【使用IDEA开发离线程序--批量处理数据--WordCountBatch】
Posted on 2020-08-30 16:12 MissRong 阅读(321) 评论(0) 收藏 举报Flink(五)Flink开发IDEA环境搭建与测试(3)
使用IDEA开发离线程序--批量处理数据--WordCountBatch
Dataset是flink的常用程序,数据集通过source进行初始化,例如读取文件或者序列化集合,然后通过transformation(filtering、mapping、joining、grouping)将数据集转成,然后通过sink进行存储,既可以写入hdfs这种分布式文件系统,也可以打印控制台,flink可以有很多种运行方式,如local、flink集群、yarn等.
(1)scala程序
|
import org.apache.flink.api.scala.ExecutionEnvironment import org.apache.flink.api.scala._
object WordCountScala{ def main(args: Array[String]) { //初始化环境 val env = ExecutionEnvironment.getExecutionEnvironment //从字符串中加载数据 val text = env.fromElements( "Who's there?", "I think I hear them. Stand, ho! Who's there?") //分割字符串、汇总tuple、按照key进行分组、统计分组后word个数 val counts = text.flatMap { _.toLowerCase.split("\\W+") filter { _.nonEmpty } } .map { (_, 1) } .groupBy(0) .sum(1) //打印 counts.print() } } |
(2)java程序
|
import org.apache.flink.api.common.functions.FlatMapFunction; import org.apache.flink.api.java.DataSet; import org.apache.flink.api.java.ExecutionEnvironment; import org.apache.flink.api.java.tuple.Tuple2; import org.apache.flink.util.Collector;
public class WordCountJava { public static void main(String[] args) throws Exception { //构建环境 final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //通过字符串构建数据集 DataSet<String> text = env.fromElements( "Who's there?", "I think I hear them. Stand, ho! Who's there?"); //分割字符串、按照key进行分组、统计相同的key个数 DataSet<Tuple2<String, Integer>> wordCounts = text .flatMap(new LineSplitter()) .groupBy(0) .sum(1); //打印 wordCounts.print(); } //分割字符串的方法 public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) { for (String word : line.split(" ")) { out.collect(new Tuple2<String, Integer>(word, 1)); } } } } |
运行
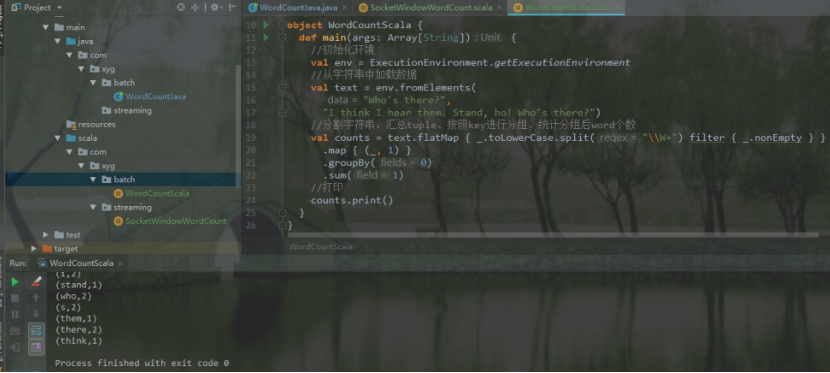
----自己操作----
Java代码:
package WordCount;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
* @Author : ASUS and xinrong
* @Version : 2020/8/29 & 1.0
*/
public class WordCountBatch {
public static void main(String[] args) throws Exception {
//一、首先创建运行时的环境-判断是本地还是集群
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
//二、构建数据集
DataSet<String> text = environment.fromElements("Who's there?", "I think I hear them.Stand,ho! Who's there!");
/**
* transformation
* 所有的转换操作
*/
DataSet<Tuple2<String, Integer>> wordCount = text.flatMap(new LinSplitter()).groupBy(0).sum(1);//自定义分词的方法,计数
wordCount.print();
//触发执行-由于用了DataSet的API所以不调用execute()也可,如果调用:除了打印结果之外还会报错
//environment.execute();
}
/**
* 自定义分词方法
*/
private static class LinSplitter implements FlatMapFunction<String, Tuple2<String,Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String,Integer>> out) throws Exception {
for(String word:line.split(" ")){
out.collect(new Tuple2<>(word,1));
}
}
}
}
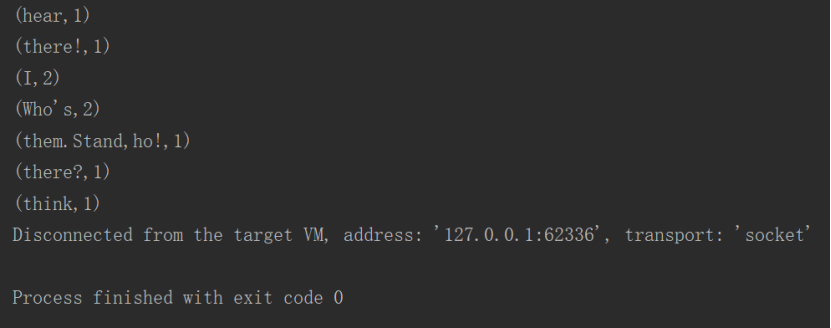
结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号