
Elasticsearch-IK分词器(二)IK分词器的使用(2)【JavaAPI操作】+Store 的解释
Posted on 2020-08-17 22:26 MissRong 阅读(370) 评论(0) 收藏 举报Elasticsearch-IK分词器(二)IK分词器的使用
一、JavaAPI操作
1)创建索引
@Test
public void createIndex_blog() {
client.admin().indices().prepareCreate("blog1").get();
// 关掉连接
client.close();
}
2)创建mapping
//十四、使用IK分词器进行mapping-映射
@Test
public void createMapping_ik() throws Exception {
//1.设置mapping
XContentBuilder builder = XContentFactory.jsonBuilder().startObject().startObject("article") // 表
.startObject("properties").startObject("id") // properties里面有id1
.field("type", "text").field("store", "true").field("analyzer","ik_smart").endObject().startObject("title") // properties里面有title2
.field("type", "text").field("store", "false").field("analyzer","ik_smart").endObject().startObject("content") // properties里面有content3
.field("type", "text").field("store", "true").field("analyzer","ik_smart").endObject().endObject().endObject().endObject();
//2.添加mapping
//注意:最好先新建一个索引-blog1,
// 或者将id和title和content名字都改一下,否则会操作失败
PutMappingRequest mappingRequest = Requests.putMappingRequest("blog1").type("article").source(builder);
client.admin().indices().putMapping(mappingRequest).get();
//3.关闭资源
client.close();
}
结果:

3)插入数据
// 十五、新建文档 / 插入数据--使用map+ik分词器
@Test
public void createDocByMap_forik() {
// 源数据map构建器添加json
Map<String, Object> json = new HashMap<String, Object>();
json.put("id", "2");
json.put("title", "基于Lucene的搜索服务器");
json.put("content", "它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口");
// 创建文档
// 注意:这里没有传第三个数-ID,但是ES依然会自动产生ID的
IndexResponse indexResponse = client.prepareIndex("blog1", "article").setSource(json).execute().actionGet();
// 打印返回结果
System.out.println("index:" + indexResponse.getIndex());
System.out.println("type:" + indexResponse.getType());
System.out.println("id:" + indexResponse.getId());
System.out.println("version:" + indexResponse.getVersion());
System.out.println("结果:" + indexResponse.getResult());
// 关闭连接
client.close();
}
结果:

4)词条查询
// 十六、词条查询-TermQuery+ik分词器
// 注意:需要加入分词器,不然容易搜不到匹配的词
@Test
public void termQuery_forik() {
// 类似于MySQL中的=
// 注意:这个=不是真正的=,它不是与字段等于,而是和字段的分词结果等于。
SearchResponse searchResponse = client.prepareSearch("blog1").setTypes("article")
.setQuery(QueryBuilders.termQuery("content", "接口")).get();
SearchHits hits = searchResponse.getHits();
System.out.println("查询结果有:" + hits.getTotalHits() + " 条");
for (SearchHit searchHits : hits) {
System.out.println(searchHits.getSourceAsString());
}
client.close();
}
结果查看:
查询结果有:1 条结果查看
{"id":"2","title":"基于Lucene的搜索服务器","content":"它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口"}
--------------------------------------------------------------------------------------------------------
如果要执行的话,需要再添加以下代码来建立连接:
public class ESTest_1 { // 对ES的操作都是通过client private TransportClient client; // 注意:加注解才能运行 @SuppressWarnings("unchecked") @Before // @Before 以后在操作ES的时候首先获取连接-初始化Client // 获取连接-初始化Client public void getClient() throws Exception { // 1.设置连接集群的名称 Settings settings = Settings.builder().put("cluster.name", "my-application").build(); // 2.连接集群 client = new PreBuiltTransportClient(settings); // IP,client-客户机操作ES的端口号 client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("192.168.212.111"), 9300)); }
整体代码参考:https://www.cnblogs.com/liuxinrong/articles/13515694.html
二、Store 的解释:
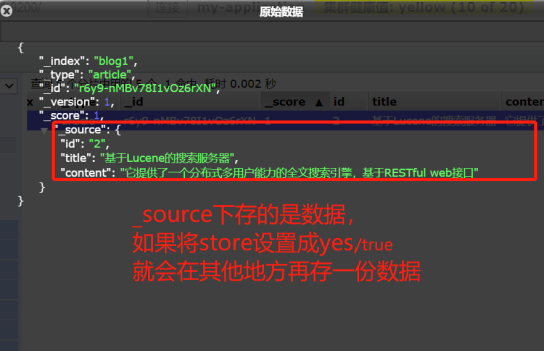
使用 elasticsearch 时碰上了很迷惑的地方,我看官方文档说 store 默认是 no ,我想当然的理解为也就是说这个 field 是不会 store 的,但是查询的时候也能查询出来,经过查找资料了解到原来 store 的意思是,是否在 _source 之外在独立存储一份,这里要说一下 _source 这是源文档,当你索引数据的时候, elasticsearch 会保存一份源文档到 _source ,如果文档的某一字段设置了 store 为 yes (默认为 no),这时候会在 _source 存储之外再为这个字段独立进行存储,这么做的目的主要是针对内容比较多的字段,放到 _source 返回的话,因为_source 是把所有字段保存为一份文档,命中后读取只需要一次 IO,包含内容特别多的字段会很占带宽影响性能,通常我们也不需要完整的内容返回(可能只关心摘要),这时候就没必要放到 _source 里一起返回了(当然也可以在查询时指定返回字段)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号