
Spark 2.x管理与开发-Spark Streaming-性能优化(二)诊断Spark内存使用
Posted on 2020-08-10 17:50 MissRong 阅读(198) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark Streaming-性能优化(二)诊断Spark内存使用
首先需要看到内存使用情况,才能进行针对性优化
1. 内存花费:
1)每个Java对象,都有一个对象头,占16个字节,主要包含对象的元信息,比如说类的指针。
如果这个对象本身很小,他的对象头可能比实际的数据都大。
2)String对象不仅有对象头,还会比它内部原始数据多出40个字节
String内部会使用char数组来保存内部的字符串序列,需要保存一些诸如数组长度的信息。
如果String使用UTF-16编码,每个字符会占用2个字节,比如:包含10个字符的String,占用2*10+40=60个字节
3)集合类型,例如HashMap、LinkedList,内部使用链表数据结构,会对每个数据使用Entry对象包装。
Entry对象:不光有对象头,还有指向下一个entry的指针,通常占用8个字节。
4)原始数据类型,会使用包装类型来存储元数据
2.如何判断Spark程序消耗内存情况
启动Spark、Spark shell
[root@bigdata111 myagent]# cd /usr/local/spark-2.1.0-bin-hadoop2.7/sbin/
[root@bigdata111 sbin]# ./start-all.sh
[root@bigdata111 sbin]# cd ../bin/
[root@bigdata111 bin]# ./spark-shell --master spark://bigdata111:7077
输入Spark命令行:
scala> val rdd1=sc.textFile("/usr/local/tmp_files/test_Cache.txt")
rdd1: org.apache.spark.rdd.RDD[String] = /usr/local/tmp_files/test_Cache.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> rdd1.cache
res0: rdd1.type = /usr/local/tmp_files/test_Cache.txt MapPartitionsRDD[1] at textFile at <console>:24
scala> rdd1.count
res1: Long = 923452
scala> rdd1.count
res2: Long = 923452
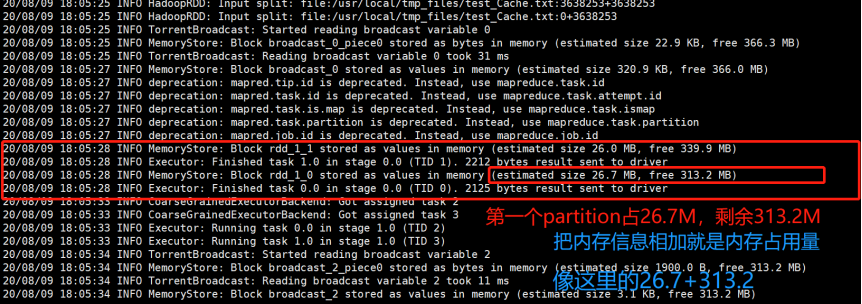
接下来进入如下路径查看指定文件里的信息:
[root@bigdata111 0]# pwd
/usr/local/spark-2.1.0-bin-hadoop2.7/work/app-20200809180023-0000/0
[root@bigdata111 0]# ll
total 8
-rw-r--r-- 1 root root 7061 Aug 9 18:05 stderr
-rw-r--r-- 1 root root 0 Aug 9 18:00 stdout
[root@bigdata111 0]# cat stderr

 浙公网安备 33010602011771号
浙公网安备 33010602011771号