
Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(八)缓存/持久化+检查点支持
Posted on 2020-08-10 15:50 MissRong 阅读(134) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶( 八)
一、缓存/持久化
与RDD类似,DStreams还允许开发人员将流数据保留在内存中。
也就是说,在DStream上调用persist() 方法会自动将该DStream的每个RDD保留在内存中。
如果DStream中的数据将被多次计算(例如,相同数据上执行多个操作),这个操作就会很有用。
对于基于窗口的操作,如reduceByWindow和reduceByKeyAndWindow以及基于状态的操作,如updateStateByKey,数据会默认进行持久化。
因此,基于窗口的操作生成的DStream会自动保存在内存中,而不需要开发人员调用persist()。
对于通过网络接收数据(例如Kafka,Flume,sockets等)的输入流,默认持久化级别被设置为将数据复制到两个节点进行容错。
请注意,与RDD不同,DStreams的默认持久化级别将数据序列化保存在内存中。
二、检查点支持
流数据处理程序通常都是全天候运行,因此必须对应用中逻辑无关的故障(例如,系统故障,JVM崩溃等)具有弹性。
为了实现这一特性,Spark Streaming需要checkpoint足够的信息到容错存储系统,以便可以从故障中恢复。
① 一般会对两种类型的数据使用检查点:
1) 元数据检查点(Metadatacheckpointing) - 将定义流计算的信息保存到容错存储中(如HDFS)。
这用于从运行streaming程序的driver程序的节点的故障中恢复。元数据包括以下几种:
- 配置(Configuration) - 用于创建streaming应用程序的配置信息。
- DStream操作(DStream operations) - 定义streaming应用程序的DStream操作集合。
- 不完整的batch(Incomplete batches) - jobs还在队列中但尚未完成的batch。
2) 数据检查点(Datacheckpointing) - 将生成的RDD保存到可靠的存储层。
对于一些需要将多个批次之间的数据进行组合的stateful变换操作,设置数据检查点是必需的。
在这些转换操作中,当前生成的RDD依赖于先前批次的RDD,这导致依赖链的长度随时间而不断增加,由此也会导致基于血统机制的恢复时间无限增加。
为了避免这种情况,stateful转换的中间RDD将定期设置检查点并保存到到可靠的存储层(例如HDFS)以切断依赖关系链。
总而言之,元数据检查点主要用于从driver程序故障中恢复,而数据或RDD检查点在任何使用stateful转换时是必须要有的。
② 何时启用检查点:
对于具有以下任一要求的应用程序,必须启用检查点:
1) 使用状态转:
如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(具有逆函数),则必须提供检查点目录以允许定期保存RDD检查点。
2) 从运行应用程序的driver程序的故障中恢复:
元数据检查点用于使用进度信息进行恢复。
③ 如何配置检查点:
可以通过在一些可容错、高可靠的文件系统(例如,HDFS,S3等)中设置保存检查点信息的目录来启用检查点。
这是通过使用streamingContext.checkpoint(checkpointDirectory)完成的。
设置检查点后,您就可以使用上述的有状态转换操作。
此外,如果要使应用程序从驱动程序故障中恢复,您应该重写streaming应用程序以使程序具有以下行为:
1) 当程序第一次启动时,它将创建一个新的StreamingContext,设置好所有流数据源,然后调用start()方法。
2) 当程序在失败后重新启动时,它将从checkpoint目录中的检查点数据重新创建一个StreamingContext。
使用StreamingContext.getOrCreate可以简化此行为
④ 改写之前的WordCount程序,使得每次计算的结果和状态都保存到检查点目录下
package demo
import org.apache.spark.SparkConf
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.{Seconds, StreamingContext}
object MyCheckpointNetworkWordCount {
def main(args: Array[String]): Unit = {
//在主程序中,创建一个Streaming Context对象
//1、读取一个检查点的目录
//2、如果该目录下已经存有之前的检查点信息,从已有的信息上创建这个Streaming Context对象
//3、如果该目录下没有信息,创建一个新的Streaming Context
val context = StreamingContext.getOrCreate("hdfs://192.168.157.111:9000/spark_checkpoint",createStreamingContext)
//启动任务
context.start()
context.awaitTermination()
}
//创建一个StreamingContext对象,并且设置检查点目录,执行WordCount程序(记录之前的状态信息)
def createStreamingContext():StreamingContext = {
val conf = new SparkConf().setAppName("MyCheckpointNetworkWordCount").setMaster("local[2]")
//创建这个StreamingContext对象
val ssc = new StreamingContext(conf,Seconds(3))
//设置检查点目录
ssc.checkpoint("hdfs://192.168.157.111:9000/spark_checkpoint")
//创建一个DStream,执行WordCount
val lines = ssc.socketTextStream("192.168.157.81",7788,StorageLevel.MEMORY_AND_DISK_SER)
//分词操作
val words = lines.flatMap(_.split(" "))
//每个单词记一次数
val wordPair = words.map(x=> (x,1))
//执行单词计数
//定义一个新的函数:把当前的值跟之前的结果进行一个累加
val addFunc = (currValues:Seq[Int],preValueState:Option[Int]) => {
//当前当前批次的值
val currentCount = currValues.sum
//得到已经累加的值。如果是第一次求和,之前没有数值,从0开始计数
val preValueCount = preValueState.getOrElse(0)
//进行累加,然后累加后结果,是Option[Int]
Some(currentCount + preValueCount)
}
//要把新的单词个数跟之前的结果进行叠加(累计)
val totalCount = wordPair.updateStateByKey[Int](addFunc)
//输出结果
totalCount.print()
//返回这个对象
ssc
}
}
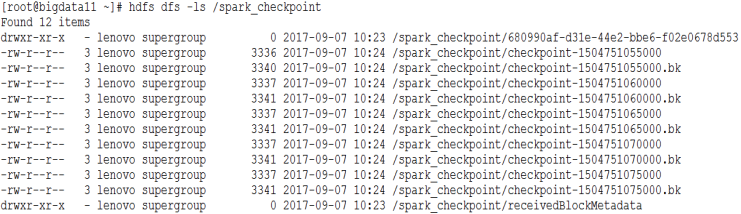
通过查看HDFS中的信息,可以看到相关的检查点信息,如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号