
Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(六)【输入DStreams和接收器】
Posted on 2020-08-10 11:50 MissRong 阅读(101) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(六)【输入DStreams和接收器】
输入DStreams表示从数据源获取输入数据流的DStreams。
在NetworkWordCount例子中,lines表示输入DStream,它代表从netcat服务器获取的数据流。
每一个输入流DStream和一个Receiver对象相关联,这个Receiver从源中获取数据,并将数据存入内存中用于处理。
输入DStreams表示从数据源获取的原始数据流。
Spark Streaming拥有两类数据源:
- 基本源(Basic sources):这些源在StreamingContext API中直接可用。例如文件系统、套接字连接、Akka的actor等
- 高级源(Advanced sources):这些源包括Kafka,Flume,Kinesis,Twitter等等。
下面通过具体的案例,详细说明:
一、文件流:
通过监控文件系统的变化,若有新文件添加,则将它读入并作为数据流
需要注意的是:
① 这些文件具有相同的格式
② 这些文件通过原子移动或重命名文件的方式在dataDirectory创建
③ 如果在文件中追加内容,这些追加的新数据也不会被读取。
注意:要演示成功,需要在原文件中编辑,然后拷贝一份。
*********自己操作********
文件流(监控文件系统的变化,如果文件有增加,读取新的文件内容),用到的很少
Spark Streaming监视文件夹,如果有变化,把变化的内容采集进来。
Scala代码:
package streamingExamples
/**
* 文件流
*/
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
object FileStreaming {
def main(args: Array[String]): Unit = {
//下面的两行代码定义日志级别,可以减少打印出来的日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//一、创建Spark环境
//保证CPU的核数大于等于2,"local[2]"表示开启两个线程
//一个线程用于读取数据,一个线程用于计算处理数据
val conf=new SparkConf().setMaster("local[2]").setAppName("FileStreaming")
//二、定时采样
//因为SparkStreaming是将连续的数据流变成不连续的RDD,所以就是定时采样。
//接收两个参数,其中:Seconds(3)是采样时间间隔,这里就是3秒
val ssc=new StreamingContext(conf,Seconds(3))
//三、创建DStream
val lines=ssc.textFileStream("D:\\tmp_files\\test_file_stream")
//四、打印
lines.print()
//五、启动StreamingContext进行计算
ssc.start()
//六、等待任务结束
ssc.awaitTermination()
}
}
结果:
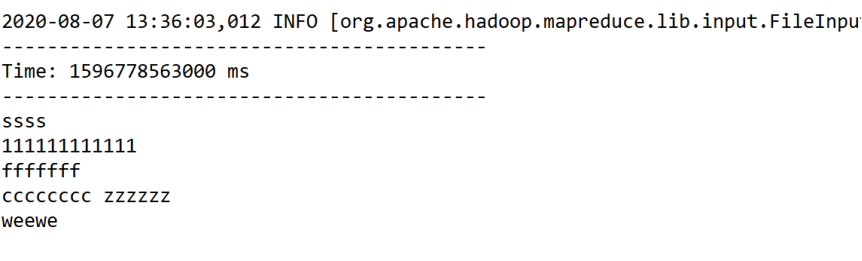
首先,运行此程序
然后在要监控的目录下新创建一个文本
添加内容如下:

接下来进行保存和重命名
发现程序执行的日志里出现了此文件的内容:
二、RDD队列流:
使用streamingContext.queueStream(queueOfRDD)创建基于RDD队列的DStream,用于调试Spark Streaming应用程序。

*********自己操作********
RDD队列流(DStream本质就是RDD),用到的很少
Scala代码:
package streamingExamples
/**
* RDD队列流
* 如果源数据直接就是一个RDD队列,Spark就直接对接这个队列即可
*/
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.apache.spark.SparkConf
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import scala.collection.mutable.Queue
import org.apache.spark.rdd.RDD
object RDDQueueStream {
def main(args: Array[String]): Unit = {
//下面的两行代码定义日志级别,可以减少打印出来的日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//一、创建Spark环境
//保证CPU的核数大于等于2,"local[2]"表示开启两个线程
//一个线程用于读取数据,一个线程用于计算处理数据
val conf=new SparkConf().setMaster("local[2]").setAppName("RDDQueueStream")
//二、定时采样
//因为SparkStreaming是将连续的数据流变成不连续的RDD,所以就是定时采样。
//接收两个参数,其中:Seconds(1)是采样时间间隔,这里就是1秒
val ssc=new StreamingContext(conf,Seconds(1))
//三、创建DStream
//1.新建RDD队列
val rddQueue=new Queue[RDD[Int]]()
//2.添加数据-循环三次
for(i<-1 to 3){
rddQueue+=ssc.sparkContext.makeRDD(1 to 10) //从数字1到10
Thread.sleep(3000) //睡3秒
}
//3.从队列中接收数据
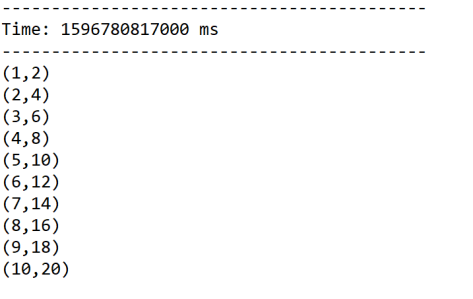
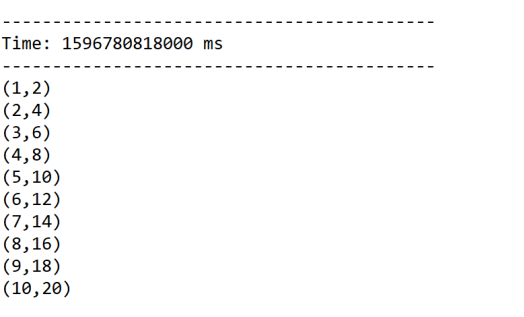
val inputDStream=ssc.queueStream(rddQueue)
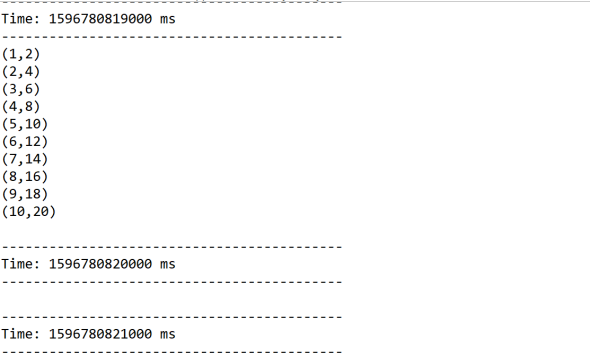
val result=inputDStream.map(x=>(x,x*2))
//四、打印
result.print()
//五、启动StreamingContext进行计算
ssc.start()
//六、等待任务结束
ssc.awaitTermination()
}
}
结果:
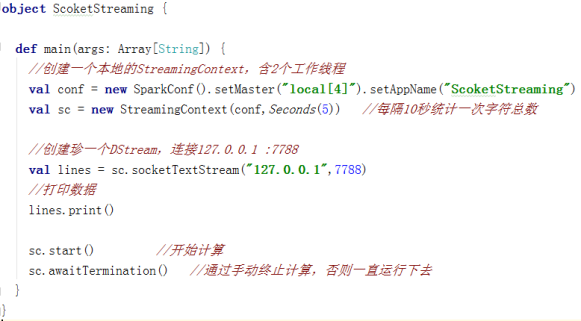
三、套接字流:
套接字流(SocketTextStream),用到的也比较有限。
通过监听Socket端口来接收数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号