
Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(四)【窗口操作】
Posted on 2020-08-06 23:17 MissRong 阅读(311) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(四)【窗口操作】
Spark Streaming还提供了窗口计算功能,允许您在数据的滑动窗口上应用转换操作。
下图说明了滑动窗口的工作方式:

如图所示,每当窗口滑过originalDStream时,落在窗口内的源RDD被组合并被执行操作以产生windowed DStream的RDD。
在上面的例子中,操作应用于最近3个时间单位的数据,并以2个时间单位滑动。这表明任何窗口操作都需要指定两个参数。
1.窗口长度(windowlength) - 窗口的时间长度(上图的示例中为:3)。
2.滑动间隔(slidinginterval) - 两次相邻的窗口操作的间隔(即每次滑动的时间长度)(上图示例中为:2)。
这两个参数必须是源DStream的批间隔的倍数(上图示例中为:1)。
我们以一个例子来说明窗口操作。
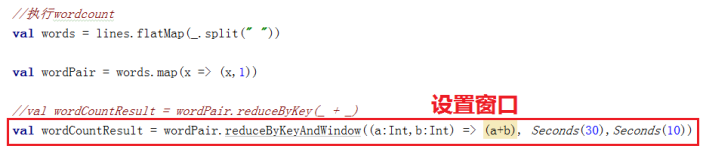
假设您希望对之前的单词计数的示例进行扩展,每10秒钟对过去30秒的数据进行wordcount。
为此,我们必须在最近30秒的pairs DStream数据中对(word, 1)键值对应用reduceByKey操作。
这是通过使用reduceByKeyAndWindow操作完成的。
一些常见的窗口操作如下表所示。所有这些操作都用到了上述两个参数 - windowLength和slideInterval。
1)window(windowLength, slideInterval)
基于源DStream产生的窗口化的批数据计算一个新的DStream
2)countByWindow(windowLength, slideInterval)
返回流中元素的一个滑动窗口数
3)reduceByWindow(func, windowLength, slideInterval)
返回一个单元素流。利用函数func聚集滑动时间间隔的流的元素创建这个单元素流。函数必须是相关联的以使计算能够正确的并行计算。
4)reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。每一个key的值均由给定的reduce函数聚集起来。
注意:在默认情况下,这个算子利用了Spark默认的并发任务数去分组。你可以用numTasks参数设置不同的任务数
5)reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks])
上述reduceByKeyAndWindow() 的更高效的版本,其中使用前一窗口的reduce计算结果递增地计算每个窗口的reduce值。
这是通过对进入滑动窗口的新数据进行reduce操作,以及“逆减(inverse reducing)”离开窗口的旧数据来完成的。
一个例子是当窗口滑动时对键对应的值进行“一加一减”操作。但是,它仅适用于“可逆减函数(invertible reduce functions)”,即具有相应“反减”功能的减函数(作为参数invFunc)。
像reduceByKeyAndWindow一样,通过可选参数可以配置reduce任务的数量。 请注意,使用此操作必须启用检查点。
6)countByValueAndWindow(windowLength, slideInterval, [numTasks])
应用到一个(K,V)对组成的DStream上,返回一个由(K,V)对组成的新的DStream。每个key的值都是它们在滑动窗口中出现的频率。
******自己操作******
Scala代码:
package streamingExamples
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.apache.spark.SparkConf
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.storage.StorageLevel
object MyNetworkWordCountByWindow {
def main(args: Array[String]): Unit = {
//下面的两行代码定义日志级别,可以减少打印出来的日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//一、创建运行时的环境
//保证CPU的核数大于等于2,"local[2]"表示开启两个线程
//一个线程用于读取数据,一个线程用于计算处理数据
val conf =new SparkConf().setMaster("local[2]").setAppName("MyNetworkWordCountByWindow")
//二、定时采样
//因为SparkStreaming是将连续的数据流变成不连续的RDD,所以就是定时采样。
//接收两个参数,其中:Seconds(3)是采样时间间隔,这里就是3秒
val ssc=new StreamingContext(conf,Seconds(3))
//三、创建DStream,从netcat服务器上读取数据
//接收三个参数:地址,端口号,和RDD里缓存的位置一致(一般取默认值即可)
//注意:IP可以不是Active状态主机的IP,只要是集群里的即可
val lines=ssc.socketTextStream("192.168.212.111", 1234, StorageLevel.MEMORY_ONLY)
//四、分词
val words=lines.flatMap(_.split(" "))
//五、计数
val wordcount =words.map((_,1)) //每个单词后面都记一次数
/**
* 需求:每3秒把过去30秒的数据读取出来
* 窗口的长度是30秒
* 滑动距离是3秒
* 也就是:每3秒钟进行移动一次,长度为30秒不变
* 注意:每次移动的长度必须是采样时间间隔的整数倍,因为RDD不能被分割
*/
val result=wordcount.reduceByKeyAndWindow((x:Int,y:Int)=>(x+y), Seconds(30), Seconds(3))
//六、打印
result.print()
//注意:因为Spark Streaming程序是流式处理程序,所以可以不用关闭此程序
//七、启动StreamingContext进行计算
ssc.start()
//八、等待任务结束
ssc.awaitTermination()
}
}
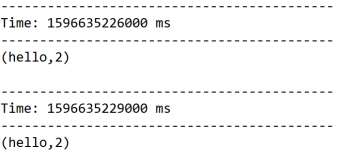
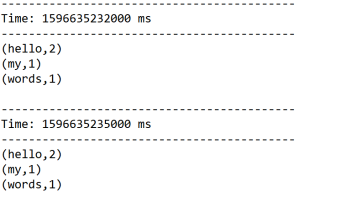
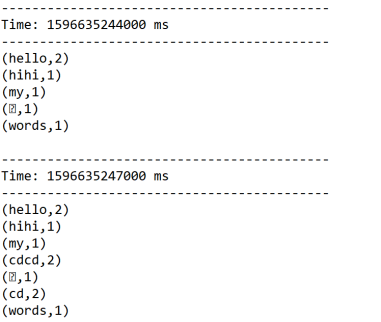
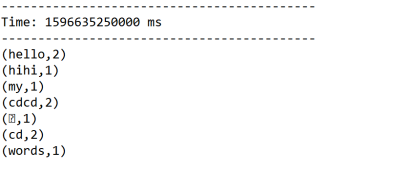
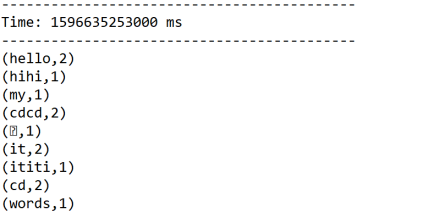
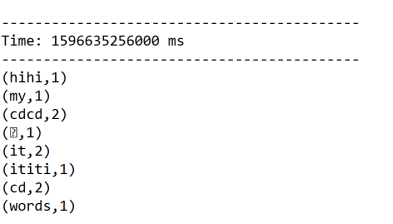
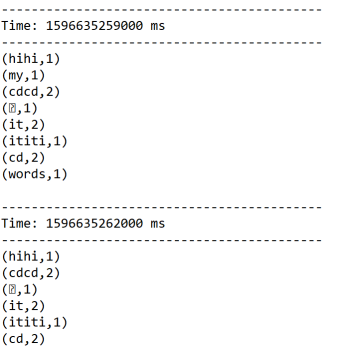
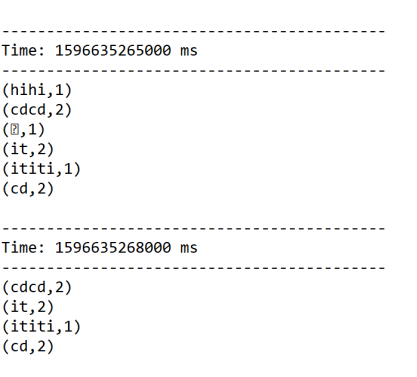
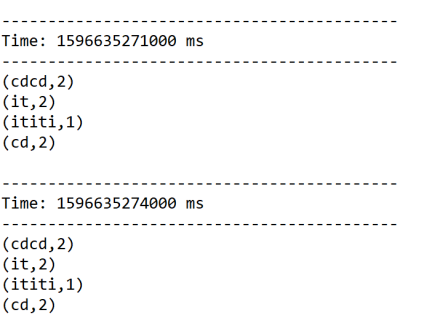
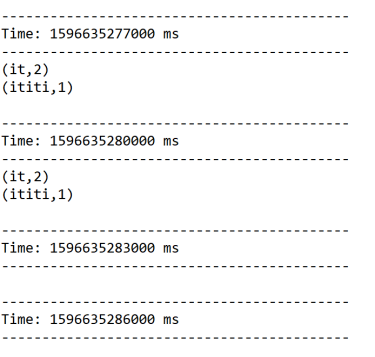
结果:
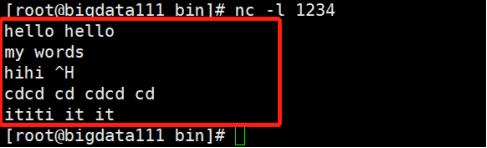
启动nc服务器:
[root@bigdata111 bin]# nc -l 1234


 浙公网安备 33010602011771号
浙公网安备 33010602011771号