
Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(三)【DStream中的转换操作(transformation+updateStateByKey)】
Posted on 2020-08-06 17:14 MissRong 阅读(173) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(三)【DStream中的转换操作(transformation+updateStateByKey)】
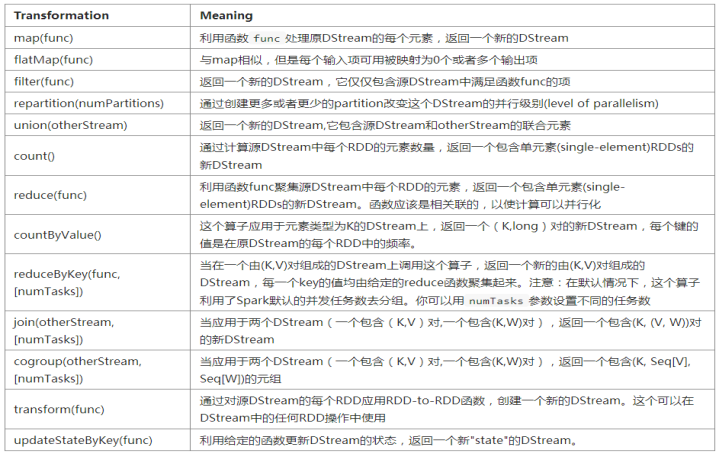
最后两个transformation算子需要重点介绍一下:
一、transform(func)
通过RDD-to-RDD函数作用于源DStream中的各个RDD,可以是任意的RDD操作,从而返回一个新的RDD
举例:在NetworkWordCount中,也可以使用transform来生成元组对
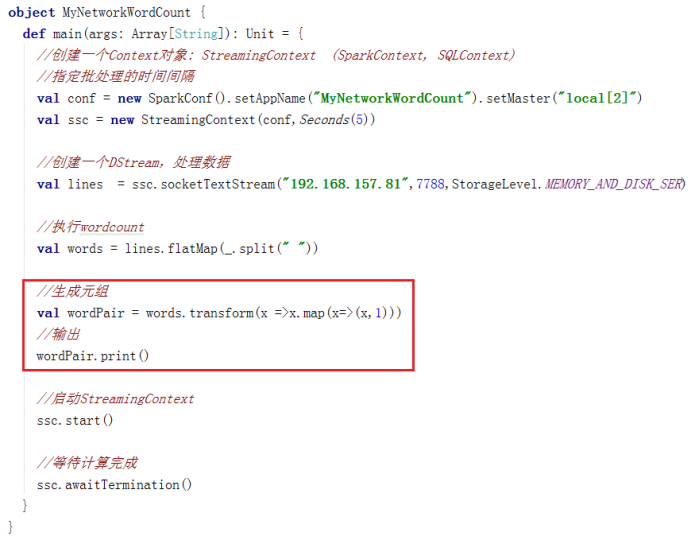
二、updateStateByKey(func)
操作允许不断用新信息更新它的同时保持任意状态。
定义状态-状态可以是任何的数据类型
定义状态更新函数-怎样利用更新前的状态和从输入流里面获取的新值更新状态
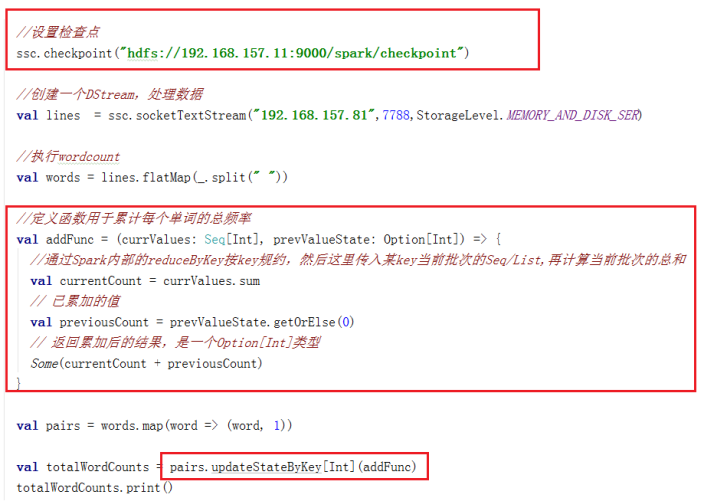
重写NetworkWordCount程序,累计每个单词出现的频率(注意:累计)
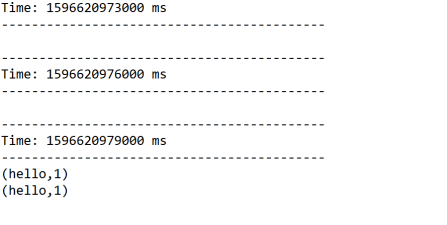
输出结果:

注意:如果在IDEA中,不想输出log4j的日志信息,可以将log4j.properties文件(放在src的目录下)的第一行改为:
log4j.rootCategory=ERROR, console
****************自己操作**************
一、transformation
Scala代码:
package streamingExamples
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.storage.StorageLevel
import org.apache.log4j.Logger
import org.apache.log4j.Level
/**
* 知识点:
* 1.创建StreamingContext 核心:DStream 离散流
* 2.DSteam的表现形式就是RDD,对二者的操作是一样的
* 3.使用DStream把连续的数据流变成不连续的RDD
* Spark Streaming最核心的内容
*/
object MyNetworkWordCount {
def main(args: Array[String]): Unit = {
//下面的两行代码定义日志级别,可以减少打印出来的日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//一、创建运行时的环境
//保证CPU的核数大于等于2,"local[2]"表示开启两个线程
//一个线程用于读取数据,一个线程用于计算处理数据
val conf=new SparkConf().setMaster("local[2]").setAppName("MyNetworkWordCount")
//二、定时采样
//因为SparkStreaming是将连续的数据流变成不连续的RDD,所以就是定时采样。
//接收两个参数,其中:Seconds(3)是采样时间间隔,这里就是3秒
val ssc=new StreamingContext(conf,Seconds(3))
//三、创建DStream,从netcat服务器上读取数据
//接收三个参数:地址,端口号,和RDD里缓存的位置一致(一般取默认值即可)
val lines=ssc.socketTextStream("192.168.212.111", 1234, StorageLevel.MEMORY_ONLY)
//四、分词
val words=lines.flatMap(_.split(" "))
//五、计数
// val wordcount=words.map((_,1)).reduceByKey(_+_)
val wordcount =words.transform(x=>x.map(x=>(x,1))) //每个单词后面都记一次数
//注意:第一个x取得是RDD,x.map()是对RDD进行操作
//六、打印
wordcount.print()
//注意:因为Spark Streaming程序是流式处理程序,所以可以不用关闭此程序
//七、启动StreamingContext进行计算
ssc.start()
//八、等待任务结束
ssc.awaitTermination()
}
}
结果:
先启动虚拟机的nc服务器
[root@bigdata111 ~]# nc -l 1234
然后再运行此程序
接下来向服务器传数据

二、updateStateByKey
默认情况下,Spark Streaming 不记录之前的状态,每次发一条数据都是从0开始计算。
使用此算子来实现累加。
设置检查点-一般设置在HDFS上,将之前的数据都保存到该检查点目录里。
启动Zookeeper-三台同步启动
[root@bigdata111 ~]# zkServer.sh start
启动Hadoop
[root@bigdata111 ~]# cd /opt/module/HA/hadoop-2.8.4/
[root@bigdata111 hadoop-2.8.4]# cd sbin/
[root@bigdata111 sbin]# ./start-all.sh
[root@bigdata112 ~]# cd /opt/module/HA/hadoop-2.8.4/sbin/
[root@bigdata112 sbin]# ./start-all.sh
Scala代码:
package streamingExamples
import org.apache.spark.SparkConf
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.log4j.Logger
import org.apache.log4j.Level
import org.apache.spark.storage.StorageLevel
object MyTotalNetworkWordCount {
def main(args: Array[String]): Unit = {
//下面的两行代码定义日志级别,可以减少打印出来的日志
Logger.getLogger("org.apache.spark").setLevel(Level.ERROR)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
//一、创建运行时的环境
//保证CPU的核数大于等于2,"local[2]"表示开启两个线程
//一个线程用于读取数据,一个线程用于计算处理数据
val conf =new SparkConf().setMaster("local[2]").setAppName("MyTotalNetworkWordCount")
//二、定时采样
//因为SparkStreaming是将连续的数据流变成不连续的RDD,所以就是定时采样。
//接收两个参数,其中:Seconds(3)是采样时间间隔,这里就是3秒
val ssc=new StreamingContext(conf,Seconds(3))
//三、设置检查点目录-一般设置在HDFS上
//注意:IP必须是Active状态主机的IP
ssc.checkpoint("hdfs://192.168.212.111:9000/tmp_files/chkp0805")
//四、创建DStream,从netcat服务器上读取数据
//接收三个参数:地址,端口号,和RDD里缓存的位置一致(一般取默认值即可)
//注意:IP可以不是Active状态主机的IP,只要是集群里的即可
val lines=ssc.socketTextStream("192.168.212.112", 1234, StorageLevel.MEMORY_ONLY)
//四、分词
val words=lines.flatMap(_.split(" "))
//五、计数
val wordcount =words.map((_,1)) //每个单词后面都记一次数
/**
* 匿名函数
* curreValues:当前的值是多少
* previousValues:当前的结果是多少
*/
val addFunc=(curreValues:Seq[Int],previousValues:Option[Int]) =>{
//1)把当前值的序列进行累加
val currentTotal=curreValues.sum
//2)在之前的值上再进行累加
//注意:如果没有值就取0 ,
//注释:Some---如果有值可以引用,就是用Some来包含这个值,Some也是Option的子类。
Some(currentTotal+previousValues.getOrElse(0))
}
//自定义操作函数
val total =wordcount.updateStateByKey(addFunc)
//六、打印
total.print()
//注意:因为Spark Streaming程序是流式处理程序,所以可以不用关闭此程序
//七、启动StreamingContext进行计算
ssc.start()
//八、等待任务结束
ssc.awaitTermination()
}
}
结果:
先启动虚拟机的nc服务器
[root@bigdata111~]# nc -l 1234
然后再运行此程序
|
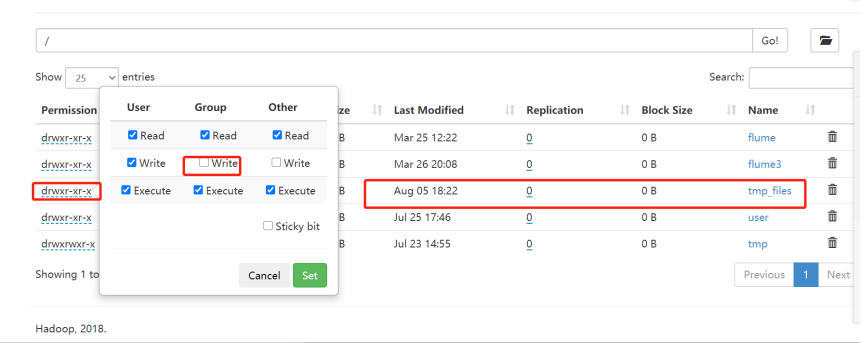
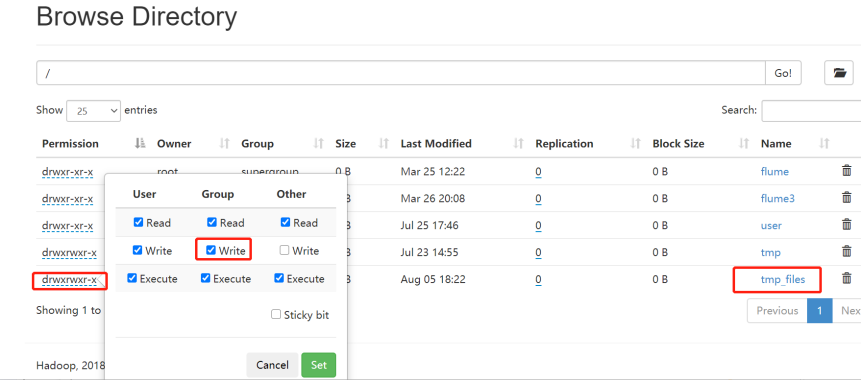
如果创建HDFS上的新目录是采用下面的命令: [root@bigdata111bin]# ./hadoop fs -mkdir -p /tmp_files 可能会出现的问题: Permission denied: user=ASUS, access=WRITE, inode="/tmp_files":root:supergroup:drwxr-xr-x 尝试(一)创建/tmp_files之后记得给它写的权限 [root@bigdata111 bin]# ./hadoop fs -chmod g+w /tmp_files 再次运行程序发现还是报错: Permission denied: user=ASUS, access=WRITE, inode="/tmp_files":root:supergroup:drwxrwxr-x 尝试(二)给予此目录最高权限: [root@bigdata111 bin]# ./hadoop fs -chmod 777 /tmp_files 运行程序,可以正常运行了 |

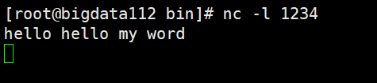
接下来向服务器传数据
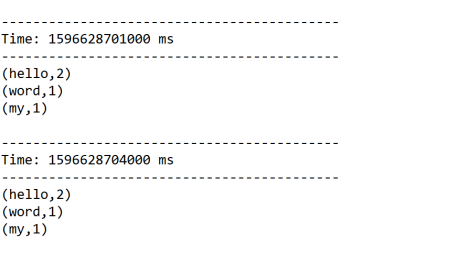
每3秒钟进行一次采样


 浙公网安备 33010602011771号
浙公网安备 33010602011771号