
Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(一)StreamingContext对象详解
Posted on 2020-08-06 16:29 MissRong 阅读(373) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark Streaming-Spark Streaming进阶(一)StreamingContext对象详解
一、初始化StreamingContext
1.方式一:从SparkConf对象中创建

2.方式二:从一个现有的SparkContext实例中创建
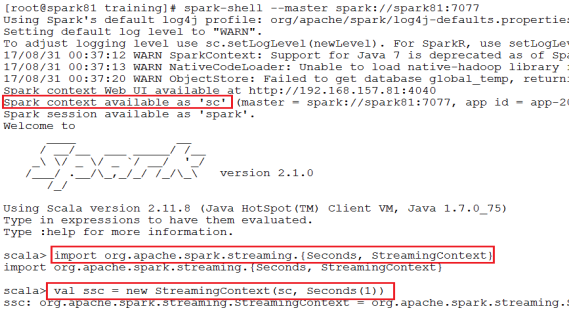
二、程序中的几点说明:
1)appName参数是应用程序在集群UI上显示的名称(可以和该程序的类名不同)。
2)master是Spark,Mesos或YARN集群的URL,或者一个特殊的“local [*]”字符串来让程序以本地模式运行。
3) 当在集群上运行程序时,不需要在程序中硬编码master参数,而是使用spark-submit提交应用程序并将master的URL以脚本参数的形式传入。但是,对于本地测试和单元测试,您可以通过“local[*]”来运行Spark Streaming程序(请确保本地系统中的cpu核心数够用)。
4) StreamingContext会内在的创建一个SparkContext的实例(所有Spark功能的起始点),你可以通过ssc.sparkContext访问到这个实例。
5) 批处理的时间窗口长度必须根据应用程序的延迟要求和可用的集群资源进行设置。
三、请务必记住以下几点:
1.一旦一个StreamingContextt开始运作,就不能设置或添加新的流计算。
2.一旦一个上下文被停止,它将无法重新启动。
3.同一时刻,一个JVM中只能有一个StreamingContext处于活动状态。
4.StreamingContext上的stop()方法也会停止SparkContext。
要仅停止StreamingContext(保持SparkContext活跃),请将stop() 方法的可选参数stopSparkContext设置为false。
5.只要前一个StreamingContext在下一个StreamingContext被创建之前停止(不停止SparkContext),SparkContext就可以被重用来创建多个StreamingContext。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号