
Spark 2.x管理与开发-Spark SQL-【在IDEA中开发Spark SQL程序】(四)从Hive里读取数据并将结果存到MySQL中
Posted on 2020-07-28 19:44 MissRong 阅读(421) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-【在IDEA中开发Spark SQL程序】(四)从Hive里读取数据并将结果存到MySQL中
1)启动进程
启动Zookeeper集群、启动Hadoop-HA
启动Hive-HA的Server:
[root@bigdata111 bin]# ./hive --service metastore
2)测试数据:
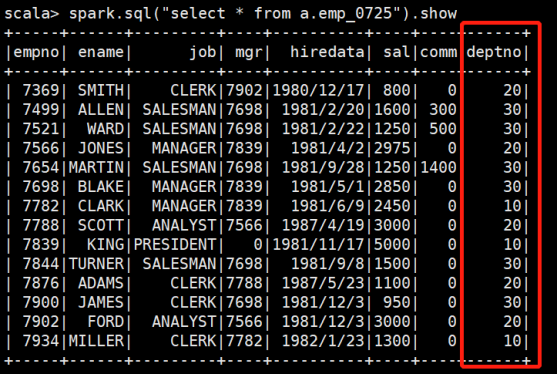
这是我之前通过Spark-shell查询到的Hive中的表格,说明此时我已将Spark兼容了Hive
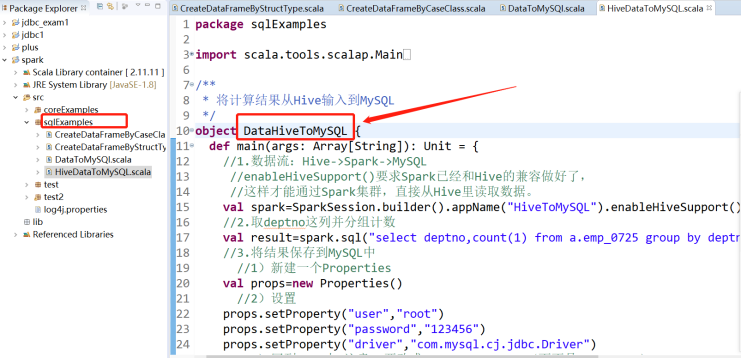
3)Scala代码:
package sqlExamples import scala.tools.scalap.Main import org.apache.spark.sql.SparkSession import java.util.Properties /** * 将计算结果从Hive输入到MySQL */ object DataHiveToMySQL { def main(args: Array[String]): Unit = { //1.数据流:Hive->Spark->MySQL //enableHiveSupport()要求Spark已经和Hive的兼容做好了, //这样才能通过Spark集群,直接从Hive里读取数据。 val spark=SparkSession.builder().appName("HiveToMySQL").enableHiveSupport().getOrCreate() //2.取deptno这列并分组计数 val result=spark.sql("select deptno,count(1) from a.emp_0725 group by deptno") //3.将结果保存到MySQL中 //1)新建一个Properties val props=new Properties() //2)设置 props.setProperty("user","root") props.setProperty("password","123456") props.setProperty("driver","com.mysql.cj.jdbc.Driver") //3)写到JDBC中,注意IP要改成:192.168.212.1(而不是localhost) result.write.mode("overwrite").jdbc("jdbc:mysql://192.168.212.1:3306/xinrong?serverTimezone=UTC&characterEncoding=UTF-8&useSSL=false", "emp_deptno", props) //4.停止Spark spark.stop() } }
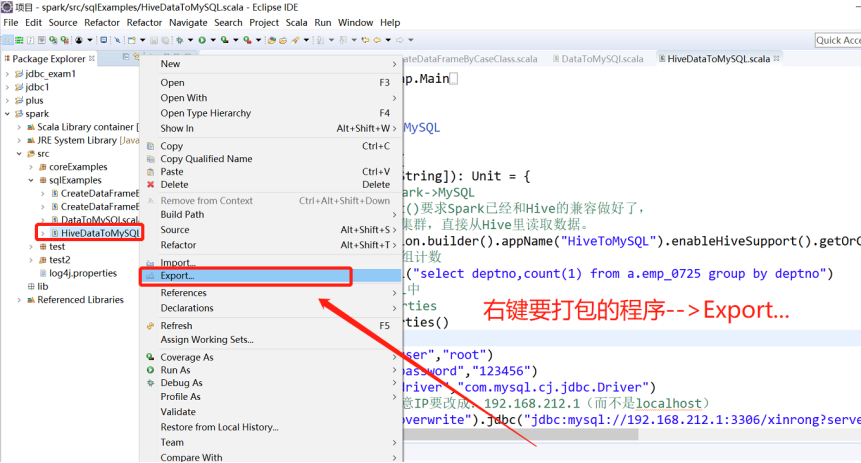
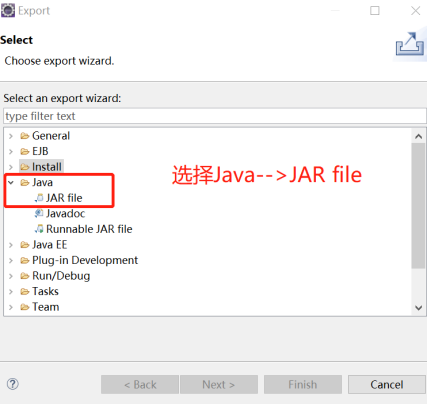
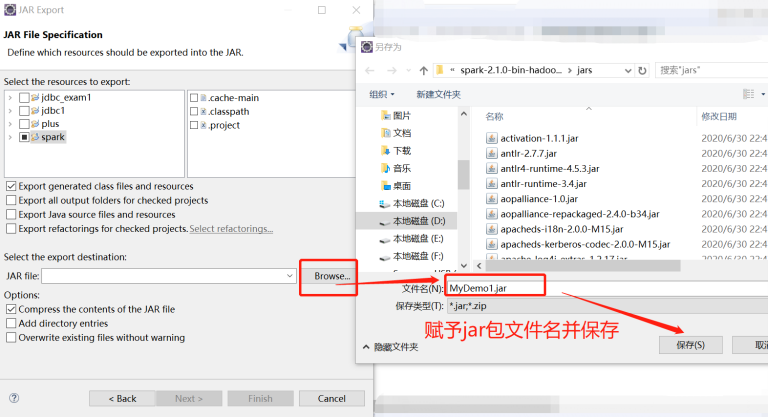
4)打包:
5)上传jar包、运行:
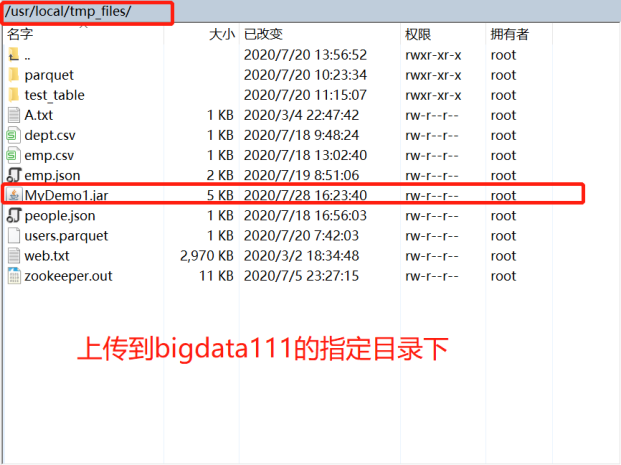
通过Spark运行jar包:
[root@bigdata111 bin]# pwd
/usr/local/spark-2.1.0-bin-hadoop2.7/bin
[root@bigdata111 bin]# ./spark-submit --master spark://bigdata111:7077 --jars /usr/local/mysql-connector-java-8.0.11.jar --driver-class-path /usr/local/mysql-connector-java-8.0.11.jar --class sqlExamples.DataHiveToMySQL /usr/local/tmp_files/MyDemo1.jar
--class sqlExamples.HiveDataToMySQL /usr/local/tmp_files/MyDemo1.jar 中:sqlExamples.DataHiveToMySQL是指:
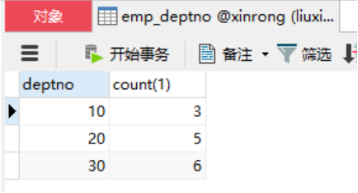
6)运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号