




Spark 2.x管理与开发-Spark SQL-【在IDEA中开发Spark SQL程序】(二)使用case class ✔
Posted on 2020-07-28 19:26 MissRong 阅读(183) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-【在IDEA中开发Spark SQL程序】(二)使用case class
准备的数据:
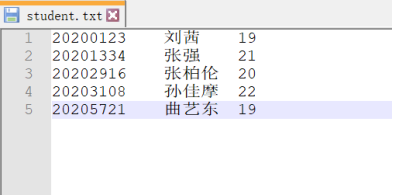
Scala代码:
package sqlExamples
import org.apache.spark.sql.SparkSession
/**
* 创建DataFrame(二)
* 通过:Case Class
*/
object CreateDataFrameByCaseClass {
def main(args: Array[String]): Unit = {
//1.首先,使用SparkSession来创建Spark的运行环境
val spark = SparkSession.builder().master("local").appName("CaseClassDemo").getOrCreate()
//2.从指定地址创建RDD
val lineRDD = spark.sparkContext.textFile("D:/student.txt").map(_.split("\t"))
//3.通过case class声明schema
//4.将RDD进行映射
val studentRDD=lineRDD.map(x=>Student(x(0).toInt,x(1),x(2).toInt))
//5.生成DataFrame,通过RDD生成DF需要导入隐式转换
import spark.sqlContext.implicits._
val studentDF=studentRDD.toDF
//6.生成视图
studentDF.createOrReplaceTempView("student")
//7.执行SQL语句
spark.sql("select * from student").show()
//8.停掉Spark
spark.stop()
}
}
//3.通过case class声明schema
case class Student(stuId:Int,stuName:String,stuAge:Int)
结果:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号