
Spark 2.x管理与开发-Spark SQL-使用数据源(二)Parquet文件
Parquet文件是一个列式存储的文件,是spark SQL默认存储的数据源。
就是普通的文件
Parquet是一个列格式而且用于多个数据处理系统中。
Spark SQL提供支持对于Parquet文件的读写,也就是自动保存原始数据的schema。
当写Parquet文件时,所有的列被自动转化为nullable,因为兼容性的缘故。
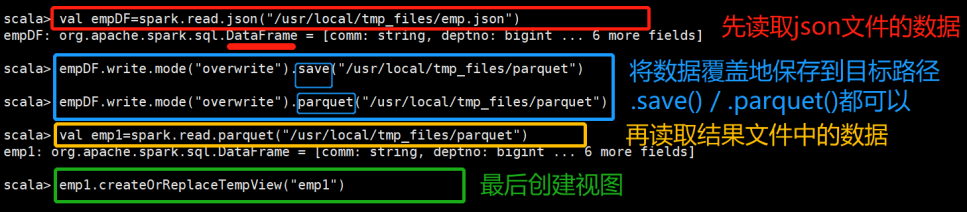
一、把json格式的文件转换成parquet格式的文件:
读入json格式的数据,将其转换成parquet格式,并创建相应的表来使用SQL进行查询。
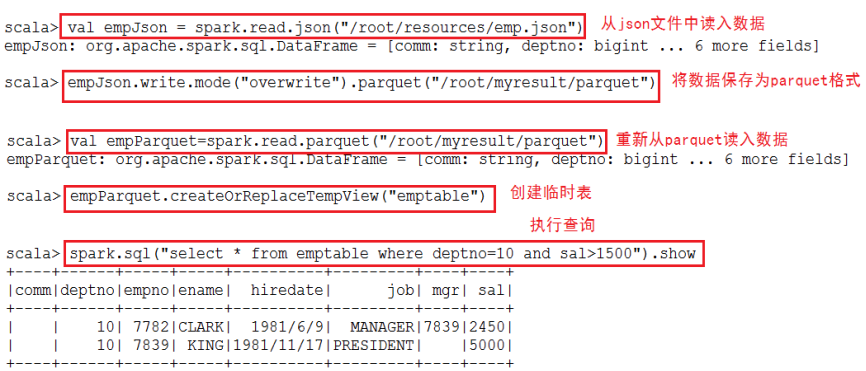
**************自己操作*************
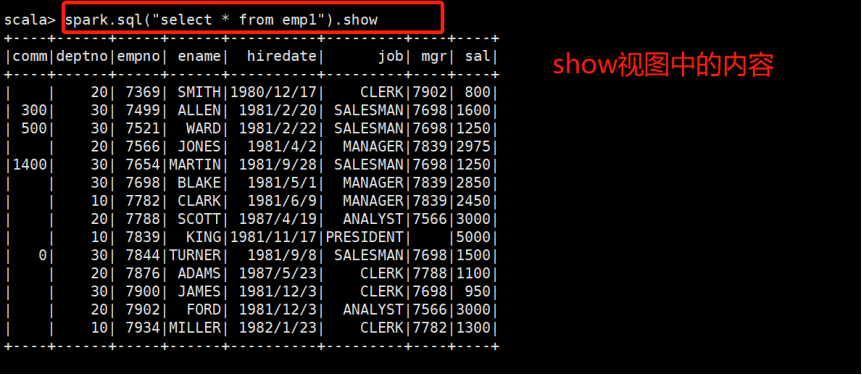
二、支持Schema的合并:
在一开始的时候,表的结构可能会很简单,但是随着需求的不断增多,表中的列需要不断地增加。
Parquet支持Schema evolution(Schema演变,即:合并)。
用户可以先定义一个简单的Schema,然后逐渐的向Schema中增加列描述。
通过这种方式,用户可以获取多个有不同Schema但相互兼容的Parquet文件。
Demo:

**********自己操作********
(1)创建两个parquet文件
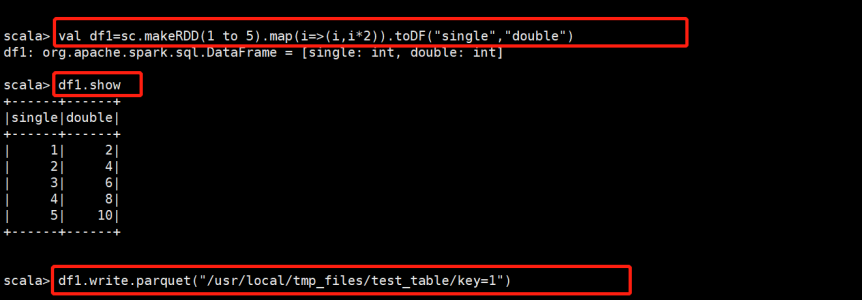
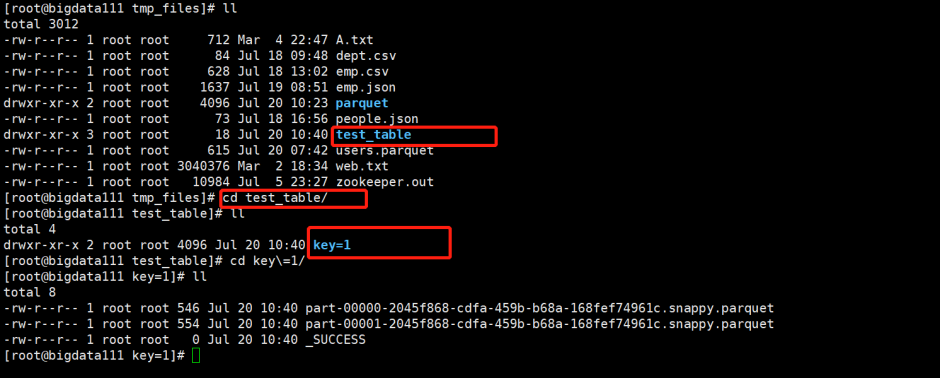
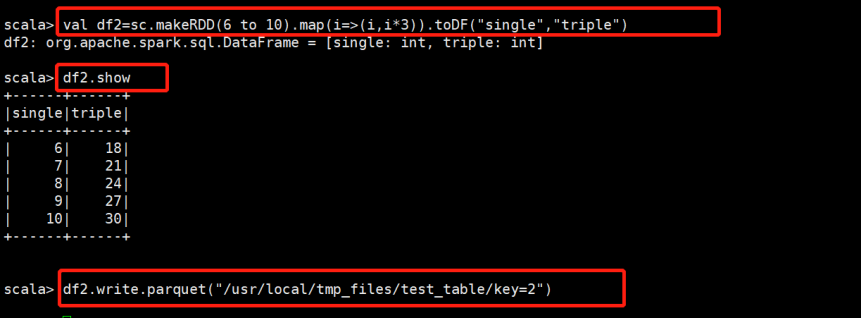

(2)接下来合并Schema
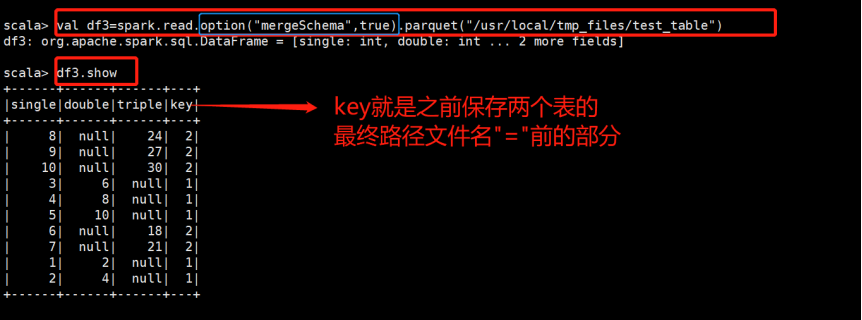
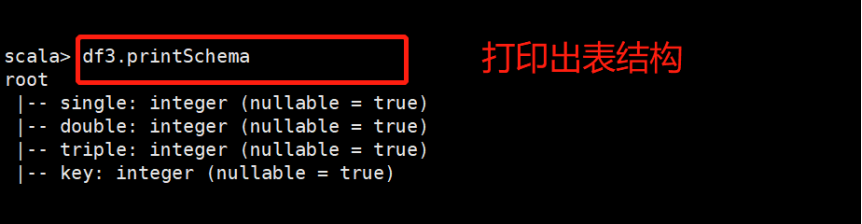
如果”=”左边的字符串不相同:
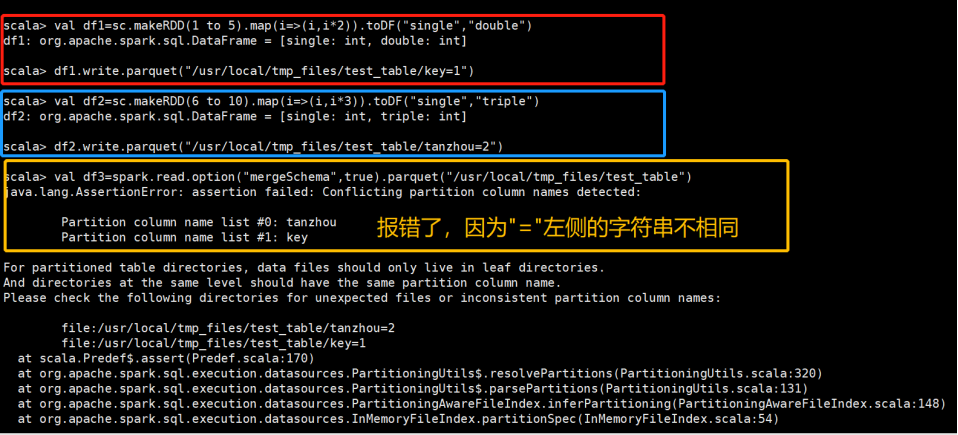

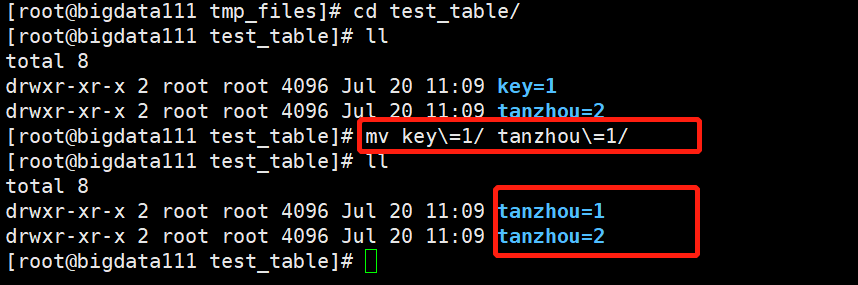
现在将key=1改成tanzhou=1,之后再执行一次:
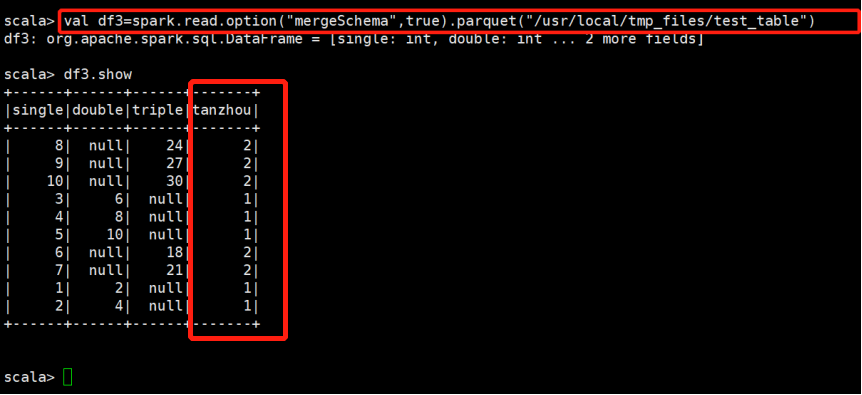
并没有报错

 浙公网安备 33010602011771号
浙公网安备 33010602011771号