
Spark 2.x管理与开发-Spark SQL-使用数据源(一)通用的Load/Save函数(2)显式指定文件格式:加载json格式+存储模式(Save Modes)
Posted on 2020-07-25 18:03 MissRong 阅读(190) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-使用数据源(一)通用的Load/Save函数
一、显式指定文件格式:加载json格式
1.直接加载:val usersDF = spark.read.load("/root/resources/people.json")
会出错
2.val usersDF = spark.read.format("json").load("/root/resources/people.json") 不出错
**************自己操作*************
spark.read.load默认加载parquet文件
像下面load一个.json文件,就会报错:

二、存储模式(Save Modes)
可以采用SaveMode执行存储操作,SaveMode定义了对数据的处理模式。
需要注意的是,这些保存模式不使用任何锁定,不是原子操作。
此外,当使用Overwrite方式执行时,在输出新数据之前原数据就已经被删除。
SaveMode详细介绍如下表:

Demo:
1)usersDF.select($"name").write.save("/root/result/parquet1")
--> 出错:因为/root/result/parquet1已经存在
2)usersDF.select($"name").write.mode("overwrite").save("/root/result/parquet1")
************自己操作***********
之前查询并保存到parquet路径一次,现在再查询并保存到该路径一次,发现会报错:
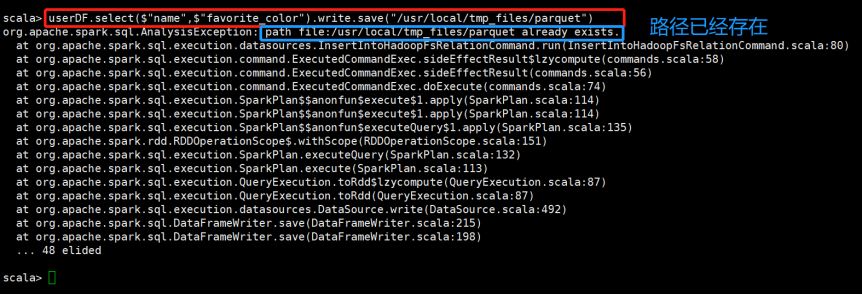
现在将原结果覆盖掉,将查询结果再写到该路径下-.write.mode("overwrite").save,发现可以操作成功:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号