
Spark 2.x管理与开发-Spark SQL-使用数据源(一)通用的Load/Save函数 (1)什么是parquet文件?+ 通用的Load/Save函数
Posted on 2020-07-25 16:13 MissRong 阅读(168) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-使用数据源(一)通用的Load/Save函数
1)什么是parquet文件?
Parquet是列式存储格式的一种文件类型,列式存储有以下的核心:
(1)可以跳过不符合条件的数据,只读取需要的数据,降低IO数据量。
(2)压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码(例如Run Length Encoding和Delta Encoding)进一步节约存储空间。
(3)只读取需要的列,支持向量运算,能够获取更好的扫描性能。
(4)Parquet格式是Spark SQL的默认数据源,可通过spark.sql.sources.default配置。
2)通用的Load/Save函数
(1)读取Parquet文件
val usersDF = spark.read.load("/root/resources/users.parquet")
(2)查询Schema和数据

(3)查询用户的name和喜爱颜色,并保存
usersDF.select($"name",$"favorite_color").write.save("/root/result/parquet")
(4)验证结果
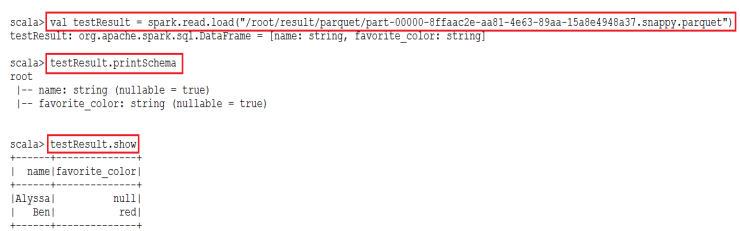
****************自己操作***************
在Spark SQL中,可以使用各种各样的数据源来操作,Spark SQL优势:对数据源兼容性好
使用load函数、save函数
load函数:加载数据的函数;save函数:存储数据的函数
注意:使用load和save函数时,默认的数据源是Parquet文件-列式存储文件。
举例(1)-parquet文件的读取与写入:
转到路径:/usr/local/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources/
将users.parquet文件复制到tmp_files目录下
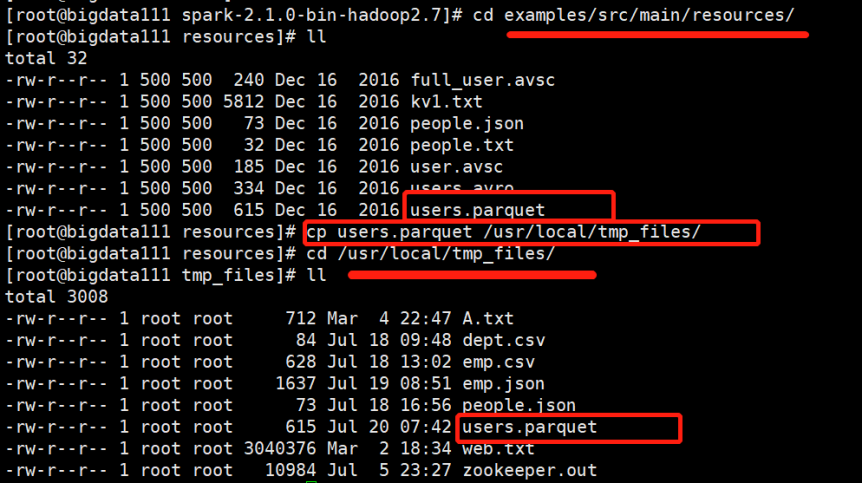
接下来用这个案例文件进行操作:
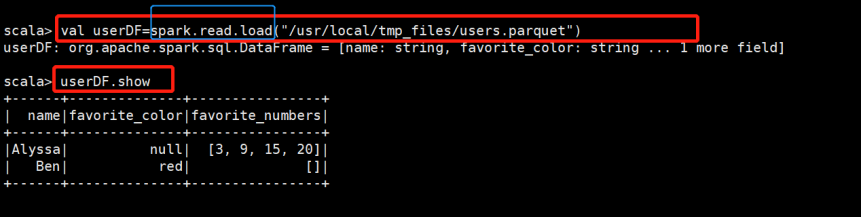
由此可以看出,parquet文件本身自带schema
也可以将结果写到某个路径下(最终文件夹不能已存在)-.write.save
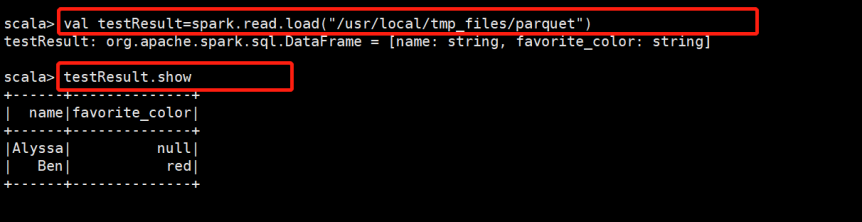
scala> userDF.select($"name",$"favorite_color").write.save("/usr/local/tmp_files/parquet")
注意:写到本地目录下的前提条件是启动的为伪分布式集群(Master和Worker在一个节点上),如果是完全分布式,就写入到HDFS上。
发现它自动创建了一个parquet文件夹:
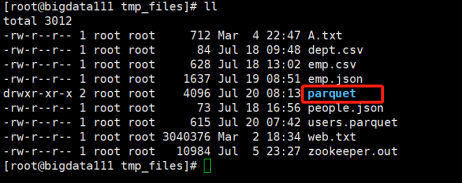
现在进入parquet文件夹下查看:

读取part-00000-...文件(只读取前两列)

也可以直接读parquet这个路径,结果相同

 浙公网安备 33010602011771号
浙公网安备 33010602011771号