
Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (六)Datasets的操作案例
Posted on 2020-07-19 22:55 MissRong 阅读(85) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (六)Datasets的操作案例
一、单表查询
1.使用emp.json 生成DataFrame
val empDF = spark.read.json("/root/resources/emp.json")
查询工资大于3000的员工
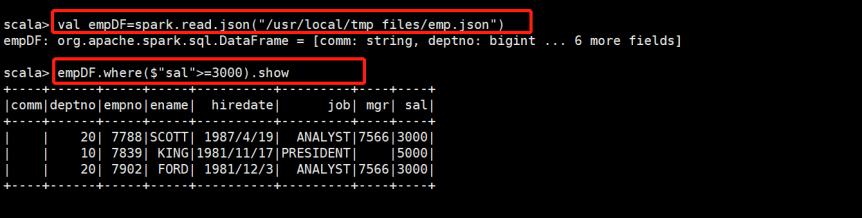
empDF.where($"sal" >= 3000).show
2.创建case class
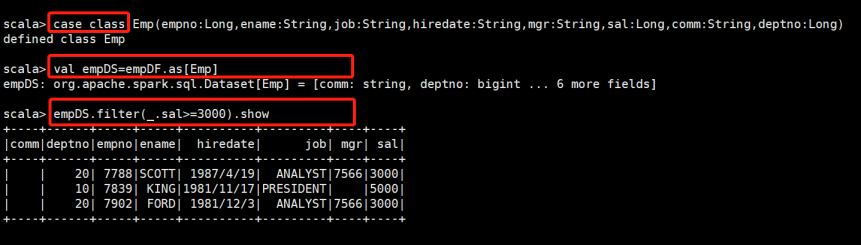
case class Emp(empno:Long,ename:String,job:String,hiredate:String,mgr:String,sal:Long,comm:String,deptno:Long)
3.生成DataSets,并查询数据
val empDS = empDF.as[Emp]
查询工资大于3000的员工
empDS.filter(_.sal > 3000).show
查看10号部门的员工
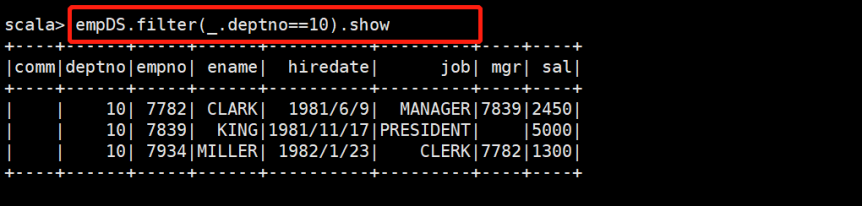
empDS.filter(_.deptno == 10).show
二、多表查询
1、创建部门表
val deptRDD=sc.textFile("/root/temp/dept.csv").map(_.split(","))
case class Dept(deptno:Int,dname:String,loc:String)
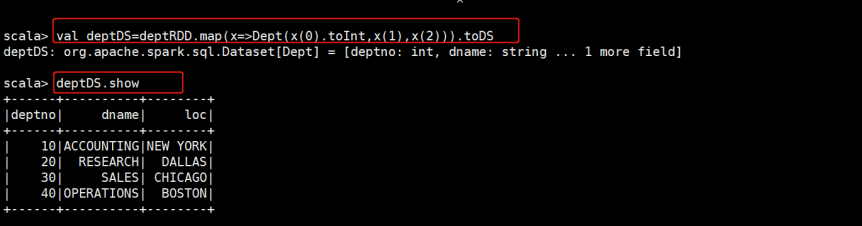
val deptDS = deptRDD.map(x=>Dept(x(0).toInt,x(1),x(2))).toDS
2、创建员工表
case class Emp(empno:Int,ename:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptno:Int)
val empRDD = sc.textFile("/root/temp/emp.csv").map(_.split(","))
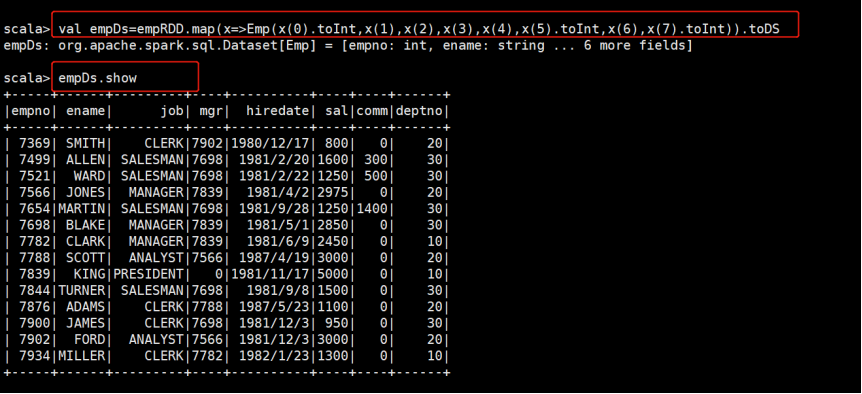
val empDS = empRDD.map(x => Emp(x(0).toInt,x(1),x(2),x(3),x(4),x(5).toInt,x(6),x(7).toInt)).toDS
3、执行多表查询:等值链接
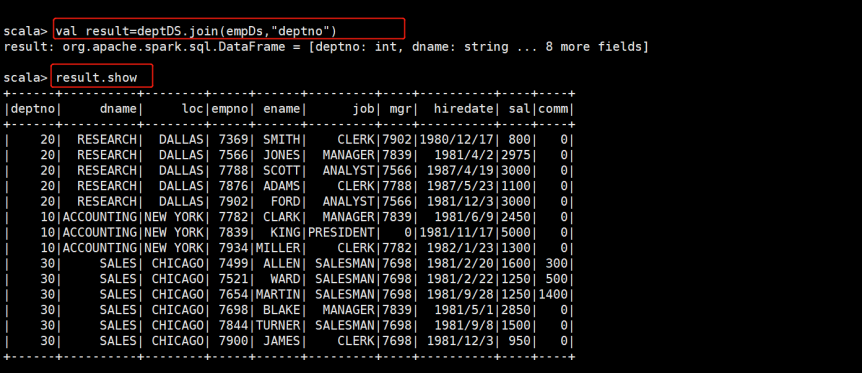
val result = deptDS.join(empDS,"deptno")
另一种写法:注意有三个等号
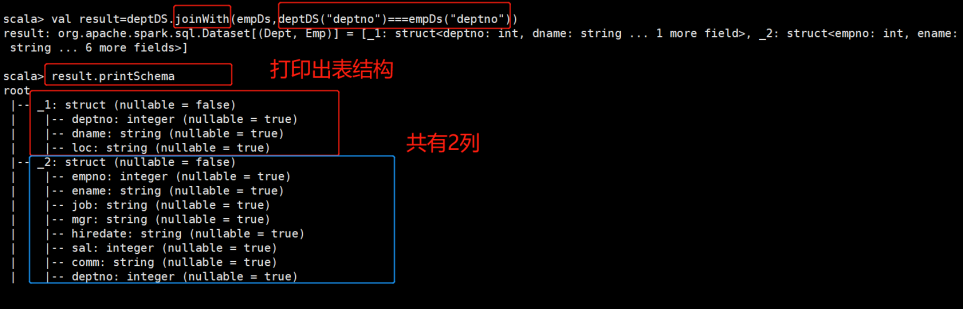
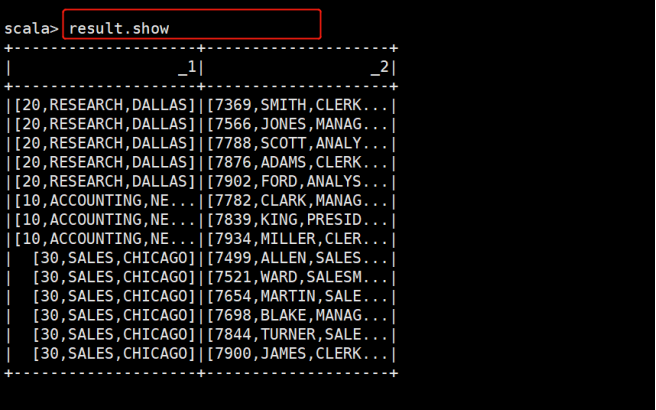
val result = deptDS.joinWith(empDS,deptDS("deptno")=== empDS("deptno"))
joinWith和join的区别是连接后的新Dataset的schema会不一样
4、查看执行计划:result.explain
*************自己操作************
1.使用json文件,查询薪水大于等于3000的员工的信息
2.创建case class ,查询薪水大于等于3000的员工的信息
查看10号部门的员工
3.多表查询
创建部门表、创建员工表、连接两表、查询操作
1)创建部门表
创建RDD、case class、再转成DataSet

2)创建员工表
创建RDD、case class、再转成DataSet

3)连接两个表
或者这样写
4)连接两表后,再查询部门号为10的所有相关信息


 浙公网安备 33010602011771号
浙公网安备 33010602011771号