
Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (五)创建Dataset ✔
Posted on 2020-07-19 22:33 MissRong 阅读(188) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (五)创建Dataset ✔
DataSet:跟DataFrame类似,是一套新的接口。
把DataSet理解成高级的DataFrame
DataFrame的引入,可以让Spark更好的处理结构数据的计算,但其中一个主要的问题是:缺乏编译时类型安全。
为了解决这个问题,Spark采用新的Dataset API (DataFrame API的类型扩展)。
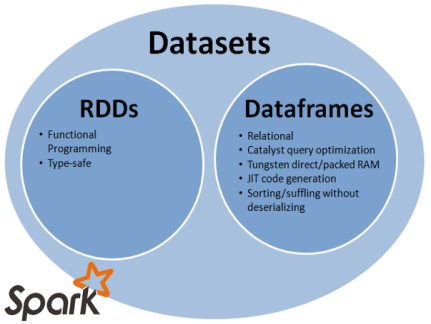
Dataset是一个分布式的数据收集器。这是在Spark1.6之后新加的一个接口,兼顾了RDD的优点(强类型,可以使用功能强大的lambda)以及Spark SQL的执行器高效性的优点。所以可以把DataFrames看成是一种特殊的Datasets,即:Dataset(Row)
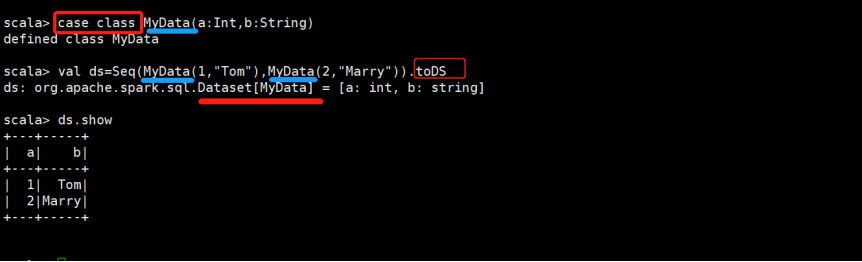
1.创建DataSet,方式一:使用序列
1)定义case class
case class MyData(a:Int,b:String)
2)生成序列,并创建DataSet
val ds = Seq(MyData(1,"Tom"),MyData(2,"Mary")).toDS
3)查看结果

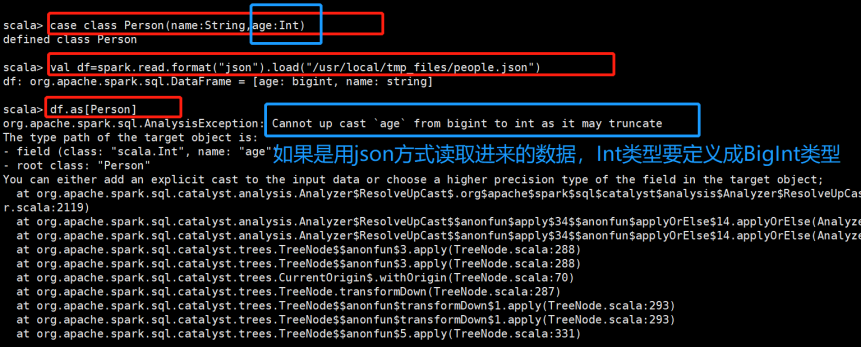
2.创建DataSet,方式二:使用JSON数据
1)定义case class
case class Person(name: String, gender: String)
2)通过JSON数据生成DataFrame
val df = spark.read.json(sc.parallelize("""{"gender": "Male", "name": "Tom"}""" :: Nil))
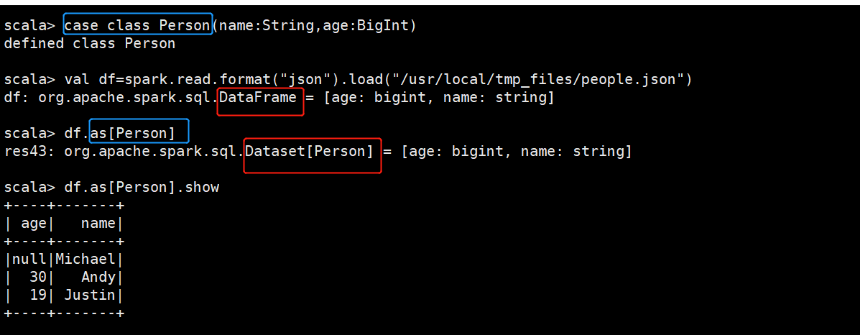
3)将DataFrame转成DataSet
df.as[Person].show
df.as[Person].collect
3.创建DataSet,方式三:使用HDFS数据
1)读取HDFS数据,并创建DataSet
val linesDS = spark.read.text("hdfs://hadoop111:9000/data/data.txt").as[String]
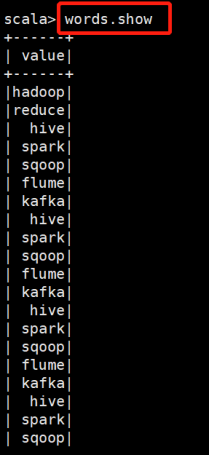
2)对DataSet进行操作:分词后,查询长度大于3的单词
val words = linesDS.flatMap(_.split(" ")).filter(_.length > 3)
words.show
words.collect
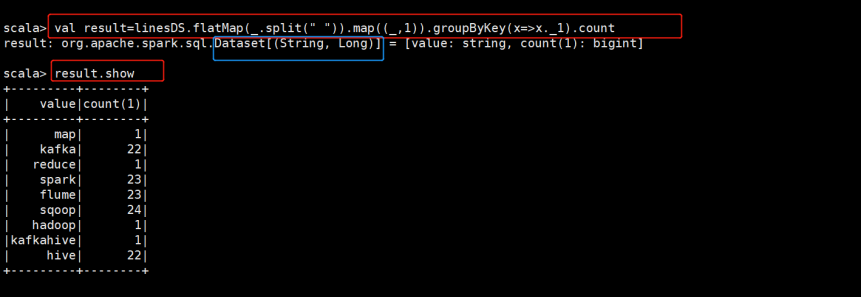
3)执行WordCount程序
val result = linesDS.flatMap(_.split(" ")).map((_,1)).groupByKey(x => x._1).count
result.show
4)排序
result.orderBy($"value").show
*************自己操作***********
创建DataSet
举例:
1)使用序列创建DataSet

2)使用Json数据
(1)定义case class
(2)通过Json生成DataFrame
(3)将DataFrame转换成DataSet
3)使用其他数据(过滤出长度大于3的字符串)
RDD操作和DataFrame操作的结合

单词计数
再对单词计数的结果进行排序:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号