
Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (三)创建DataFrame(2)使用SparkSession
Posted on 2020-07-18 18:46 MissRong 阅读(421) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (三)创建DataFrame(2)使用SparkSession
一、什么是SparkSession
Apache Spark 2.0引入了SparkSession,其为用户提供了一个统一的切入点来使用Spark的各项功能,并且允许用户通过它调用DataFrame和Dataset相关API来编写Spark程序。最重要的是,它减少了用户需要了解的一些概念,使得我们可以很容易地与Spark交互。
在2.0版本之前,与Spark交互之前必须先创建SparkConf和SparkContext。然而在Spark 2.0中,我们可以通过SparkSession来实现同样的功能,而不需要显式地创建SparkConf, SparkContext 以及 SQLContext,因为这些对象已经封装在SparkSession中。

二、创建过程
1.创建StructType,来定义Schema结构信息

注意,需要:import org.apache.spark.sql.types._
2.读入数据并且切分数据
![]()
3.将RDD中的数据映射成Row
注意,需要:import org.apache.spark.sql.Row
4.创建DataFrames
val df = spark.createDataFrame(rowRDD,myschema)
*******************自己操作****************
1.创建StructType,来定义Schema结构信息
import org.apache.spark.sql.types._

scala> val myschema = StructType(List(StructField("empno", DataTypes.IntegerType), StructField("ename", DataTypes.StringType),StructField("job", DataTypes.StringType),StructField("mgr", DataTypes.IntegerType),StructField("hiredate", DataTypes.StringType),StructField("sal", DataTypes.IntegerType),StructField("comm", DataTypes.IntegerType),StructField("deptno", DataTypes.IntegerType)))
2.读入数据并切分数据
scala> var lines=sc.textFile("/usr/local/tmp_files/emp.csv").map(_.split(","))
3.将RDD中的数据映射成Row
scala> import org.apache.spark.sql.Row
scala> val allEmp=lines.map(x=>Row(x(0).toInt,x(1),x(2),x(3).toInt,x(4),x(5).toInt,x(6).toInt,x(7).toInt))

4.创建DataFrames-createDataFrame(表数据,表结构)
scala> val df2=spark.createDataFrame(allEmp,myschema)

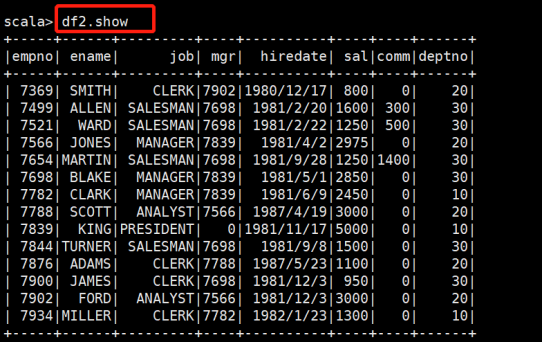
5.查询数据-df2.show

 浙公网安备 33010602011771号
浙公网安备 33010602011771号