
Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (二)核心概念:Dataset和DataFrame ✔
Posted on 2020-07-17 18:16 MissRong 阅读(107) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (二)核心概念:Dataset和DataFrame
表=表结构+数据
DataFrame=Schema(case class)+RDD
Datasets在spark1.6时,对DataFrame进行了封装,不过常用的还是DataFrame
-------------------------------------------------------------------------------------------------------------
一、DataFrame
DataFrame是组织成命名列的数据集。它在概念上等同于关系数据库中的表,但在底层具有更丰富的优化。
DataFrames可以从各种来源构建,
例如:结构化数据文件、hive中的表、外部数据库或现有RDDs
DataFrame API支持的语言有Scala,Java,Python和R。
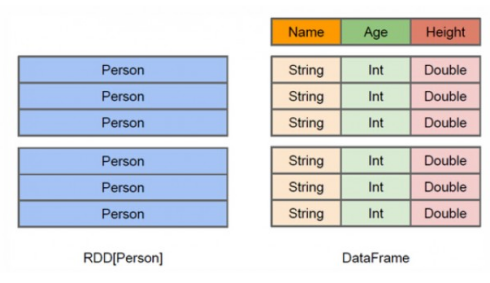
从上图可以看出,DataFrame多了数据的结构信息,即schema。
RDD是分布式的 Java对象的集合。DataFrame是分布式的Row对象的集合。
DataFrame除了提供了比RDD更丰富的算子以外,更重要的特点是提升执行效率、减少数据读取以及执行计划的优化。
二、Dataset
Dataset是数据的分布式集合。
Dataset是在Spark 1.6中添加的一个新接口,是DataFrame之上更高一级的抽象。
它提供了RDD的优点(强类型化,使用强大的lambda函数的能力)以及Spark SQL优化后的执行引擎的优点。
一个Dataset 可以从JVM对象构造,然后使用函数转换(map, flatMap,filter等)去操作。
Dataset API 支持Scala和Java, Python不支持Dataset API。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号