
Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (一)Spark SQL简介 ✔
Posted on 2020-07-17 18:08 MissRong 阅读(130) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark SQL-Spark SQL基础 (一)Spark SQL简介
一、什么是Spark SQL?
Spark SQL是Spark用来处理结构化数据的一个模块,只能处理结构化的数据。
它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。
二、为什么要学习Spark SQL?
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性。
由于MapReduce这种计算模型执行效率比较慢,所以Spark SQL的应运而生。
它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!同时Spark SQL也支持从Hive中读取数据。
---------------------------------------------------------
Spark SQL基于Spark计算,效率比Hive高(因为Hive是基于Hadoop的)。
但是在Hive的2.x中,执行引擎可以换成Spark
除了修改Hive底层之外,也可以采用Spark连接Hive的方式去完成。
三、Spark SQL的特点:
1.容易整合(集成)
在安装Spark的时候已经安装好了Spark SQL,不需要单独安装

2.统一的数据访问方式
结构化数据类型:
JDBC、JSON、Hive、Parquet文件
访问这些文件的时候写法几乎是统一的,他们之间的转换只需要修改几行代码。

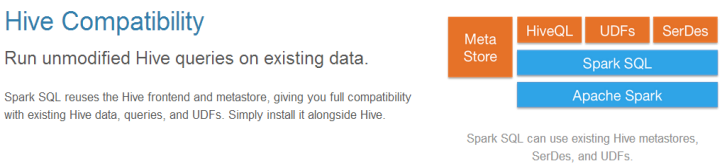
3.完全兼容Hive
可以直接读取Hive中的数据,读取过来之后,使用Spark SQL处理
可以用Spark SQL直接读取Hive中的数据然后直接用Spark MLlib来建模
4.标准的数据连接
JDBC和ODBC(一般使用的是JDBC)
直接修改驱动即可


 浙公网安备 33010602011771号
浙公网安备 33010602011771号