Spark 2.x管理与开发-【Spark基础编程案例】案例四:使用JdbcRDD操作数据库(不常用)
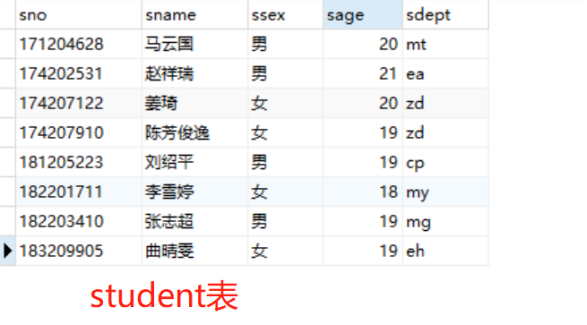
一、表格数据展示
![]()
二、Scala代码实现
package coreExamples
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import java.sql.DriverManager
import org.apache.spark.rdd.JdbcRDD
/**
* Spark Core案例-4
* 使用JdbcRDD 操作数据库(不常用)
*/
object JdbcRDD {
val connection = () => {
Class.forName("com.mysql.jdbc.Driver").newInstance()
DriverManager.getConnection("jdbc:mysql://localhost:3306/xinrong_2?characterEncoding=UTF-8&useSSL=false", "root", "123456")
}
def main(args: Array[String]): Unit = {
//创建SparkContext对象
val conf = new SparkConf().setMaster("local").setAppName("JdbsRDD")
val sc = new SparkContext(conf)
// SQL语句 ,第一个?,第二个? partition数-分区数,结果
val mysqlRDD = new JdbcRDD(sc, connection, "select * from student where sage >= ? and sage <= ?", 19, 20, 2, result => {
val sname = result.getString(2) //取表格的第二列
val sage = result.getInt(4)
(sname, sage)
})
val result = mysqlRDD.collect()
//打印结果
println(result.toBuffer)
sc.stop()
}
}
三、结果
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号