
Spark 2.x管理与开发-Spark Core-【Spark基础编程案例】案例三:访问数据库
Posted on 2020-07-17 17:35 MissRong 阅读(133) 评论(0) 收藏 举报Spark 2.x管理与开发-【Spark基础编程案例】案例三:访问数据库
一、需求
将RDD数据保存到MySQL中
取出所有的Tomcat访问日志中的jsp名,计数并将其存入MySQL中。
二、MySQL表格设计
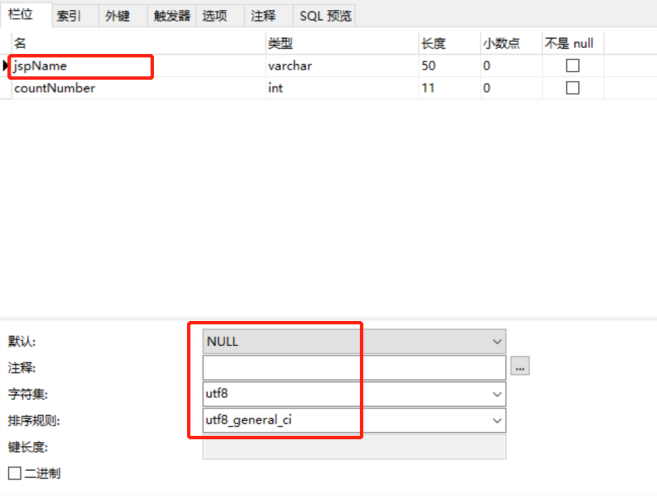
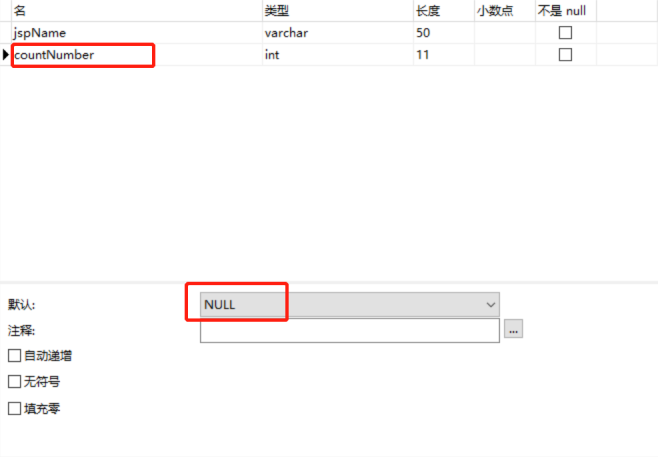
三、Scala代码实现
package coreExamples
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
import java.sql.Connection
import java.sql.PreparedStatement
import java.sql.DriverManager
/**
* Spark Core 案例-3
* 访问数据库-将jsp名字计数并存入MySQL中
*/
object FangWenShuJuKu {
//本质就是WordCount
def main(args: Array[String]): Unit = {
//首先,创建SparkContext对象
val conf = new SparkConf().setMaster("local").setAppName("FangWenShuJuKu")
val sc = new SparkContext(conf)
/**
* 读入日志解析
* 192.168.88.1 - - [30/Jul/2017:12:54:42 +0800] "GET /MyDemoWeb/web.jsp HTTP/1.1" 200 239
* (web.jsp,1)
*/
val rdd1 = sc.textFile("D:/大数据高级资料及测试/Spark Core案例数据/localhost_access_log.2017-07-30.txt")
.map(
line => {
//一、解析字符串
//1.得到两个引号之间的东西
val index1 = line.indexOf("\"")
val index2 = line.lastIndexOf("\"")
//GET /MyDemoWeb/web.jsp HTTP/1.1
val line1 = line.substring(index1 + 1, index2)
//2.得到两个空格之间的东西
val index3 = line1.indexOf(" ")
val index4 = line1.lastIndexOf(" ")
///MyDemoWeb/web.jsp
val line2 = line1.substring(index3 + 1, index4)
//3.得到jsp名字
//web.jsp
val jspName = line2.substring(line2.lastIndexOf("/") + 1)
//4.返回jsp名字并计数
(jspName, 1)
})
// rdd1.foreach(
// t => {
// var conn: Connection = null
// var pst: PreparedStatement = null
// conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/xinrong_2?characterEncoding=UTF-8&useSSL=false", "root", "123456")
// pst = conn.prepareStatement("insert into jspName value(?,?)")
// pst.setString(1, t._1)
// pst.setInt(2, t._2)
// pst.executeUpdate()
// })
/**
* 对上面的程序进行优化:
* 针对分区数据操作
*/
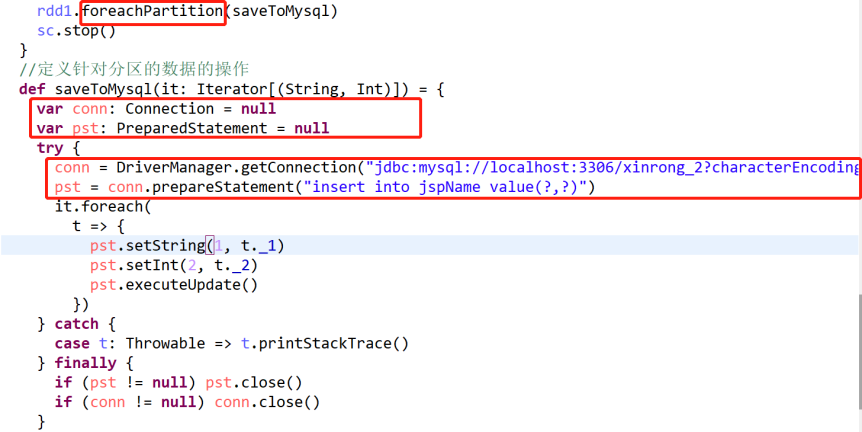
rdd1.foreachPartition(saveToMysql)
sc.stop()
}
//二、定义针对分区的数据的操作
def saveToMysql(it: Iterator[(String, Int)]) = {
var conn: Connection = null
var pst: PreparedStatement = null
try {
conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/xinrong_2?characterEncoding=UTF-8&useSSL=false", "root", "123456")
pst = conn.prepareStatement("insert into jspName value(?,?)")
it.foreach(
t => {
pst.setString(1, t._1)
pst.setInt(2, t._2)
pst.executeUpdate()
})
} catch {
case t: Throwable => t.printStackTrace()
} finally {
if (pst != null) pst.close()
if (conn != null) conn.close()
}
}
}
四、注意-容易出现的问题
Task not serializable-没有序列化
产生错误原因:
原来:conn和pst的定义和赋值都是在foreach()之前

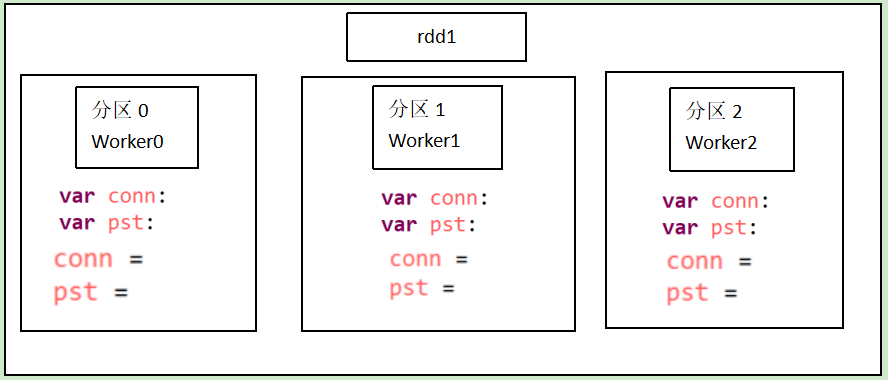
修改之后:conn和pst的定义和赋值都是在foreach()里面
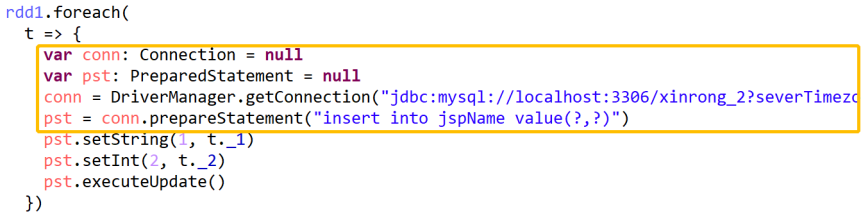
虽然这样运行没毛病,但是每一条数据都要获取一次jdbc的连接,然后访问MySQL数据库,性能太低
优化后:针对分区的数据进行操作
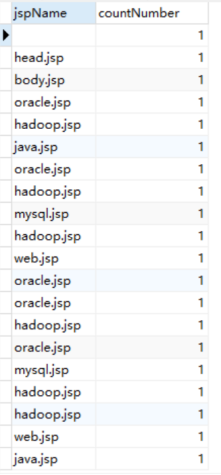
五、结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号