
Spark 2.x管理与开发-Spark Core-Spark RDD的高级算子(四)coalesce与repartition+其他高级算子
Posted on 2020-07-12 23:24 MissRong 阅读(73) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark RDD的高级算子(四)coalesce与repartition+其他高级算子
一、coalesce与repartition
都是将RDD中的分区进行重分区。
区别是:coalesce默认不会进行shuffle(false);而repartition会进行shuffle(true),即:会将数据真正通过网络进行重分区。
示例:

![]()

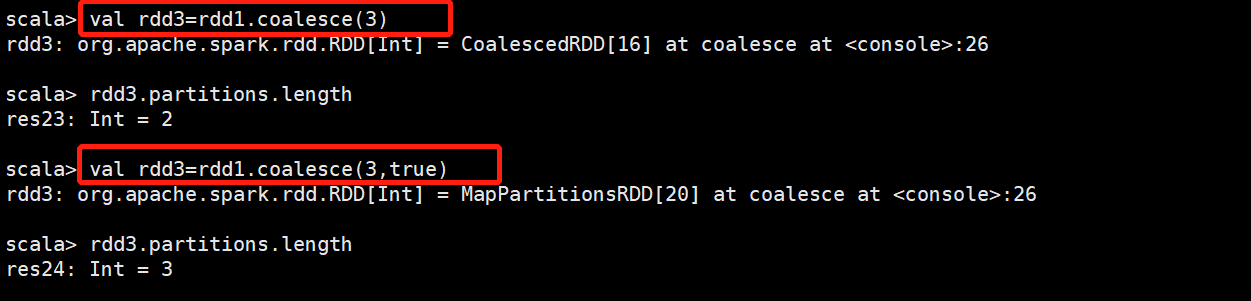
下面两句话是等价的:
val rdd2 = rdd1.repartition(3)
val rdd3 = rdd1.coalesce(3,true) --->如果是false,查看RDD的length依然是2
二、其他高级算子
参考:http://homepage.cs.latrobe.edu.au/zhe/ZhenHeSparkRDDAPIExamples.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号