
Spark 2.x管理与开发-Spark Core-Spark RDD的高级算子(二)aggregate*
Posted on 2020-07-12 23:06 MissRong 阅读(93) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark RDD的高级算子(二)aggregate*
聚合操作,类似于分组Group By
(1)先对局部进行聚合操作,再对全局进行聚合操作
(2)举例:
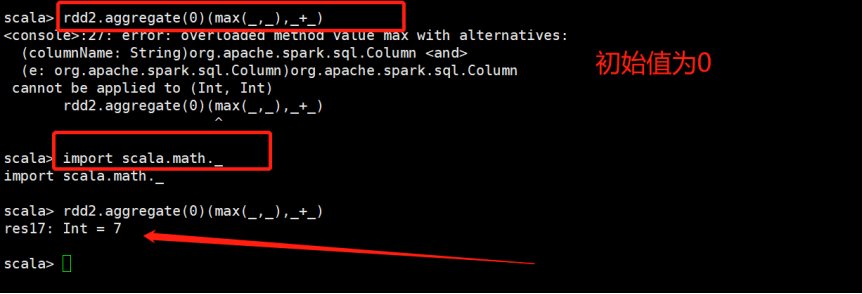
将每一个分区中的最大值加在一起
分成两步操作:
1)先在分区内部进行最大值操作
2)面对全局进行操作-求和:2+5=7

- zeroValue: U:初始值,需要赋值
后面是两个函数参数,第一个函数:表示局部操作的函数;
第二个参数:表示全局操作的函数




举一个字符的例子:


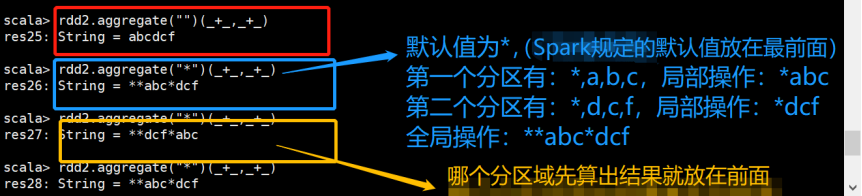
更复杂一点的例子




val rdd3 = sc.parallelize(List("12","23","345","4567"),2)
rdd3.aggregate("")((x,y) => math.max(x.length, y.length).toString, (x,y) => x + y)
结果可能是:”24”,也可能是:”42”
结果解析:
第一个分区有:”12”,”23”
第一次比较:空字符串””和”12”进行比较-求出长度的最大值-2
toString()之后2变为”2”
第二次比较:将求出的”2”和”23”进行比较-求出长度的最大值-2
toString()之后2变为”2”
第二个分区有:”34”,”4567”
第一次比较:空字符串””和”34”进行比较-求出长度的最大值-2
toString()之后2变为”2”
第二次比较:将求出的”2”和”4567”进行比较-求出长度的最大值-4
toString()之后4变为”4”
最后全局操作:拼接字符串”24”/”42”
——————————————————————————————



val rdd4 = sc.parallelize(List("12","23","345",""),2)
rdd4.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
结果是:”10”,也可能是”01”
结果分析:
第一个分区有:”12”,”23”
第一次比较:初始值-空字符串””和”12”进行比较-求出长度的最小值-0
toString()之后0变为”0”
第二次比较:将求出的”0”和”23”进行比较-求出长度的最小值-1
toString()之后1变为”1”
第二个分区有:”34”,””
第一次比较:初始值-空字符串””和”34”进行比较-求出长度的最小值-0
toString()之后0变为”0”
第二次比较:将求出的”0”和””进行比较-求出长度的最小值-0
toString()之后0变为”0”
最后全局操作:拼接字符串”10”/”01”
——————————————————————————————



val rdd5 = sc.parallelize(List("12","23","","345"),2)
rdd5.aggregate("")((x,y) => math.min(x.length, y.length).toString, (x,y) => x + y)
结果是:”11”
结果分析:
第一个分区有:”12”,”23”
第一次比较:初始值-空字符串””和”12”进行比较-求出长度的最小值-0
toString()之后0变为”0”
第二次比较:将求出的”0”和”23”进行比较-求出长度的最小值-1
toString()之后1变为”1”
第二个分区有:””,”34”
第一次比较:初始值-空字符串””和””进行比较-求出长度的最小值-0
toString()之后0变为”0”
第二次比较:将求出的”0”和”34”进行比较-求出长度的最小值-1
toString()之后1变为”1”
最后全局操作:拼接字符串”11”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号