
Spark 2.x管理与开发-Spark Core-Spark的算子(四)RDD的特性(2)RDD的Checkpoint(检查点)机制:容错机制
Posted on 2020-07-12 10:30 MissRong 阅读(102) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark的算子(四)RDD的特性(2)RDD的Checkpoint(检查点)机制:容错机制
检查点(本质是通过将RDD写入Disk做检查点)是为了通过lineage(血统)做容错的辅助,lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
设置checkpoint的目录,可以是本地的文件夹、也可以是HDFS。
一般是在具有容错能力,高可靠的文件系统上(比如HDFS, S3等)设置一个检查点路径,用于保存检查点数据。
分别举例说明:
1.本地目录
注意:这种模式,需要将spark-shell运行在本地模式上
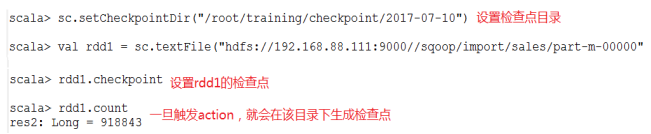
2.HDFS的目录
注意:这种模式,需要将spark-shell运行在集群模式上

3.源码中的一段话
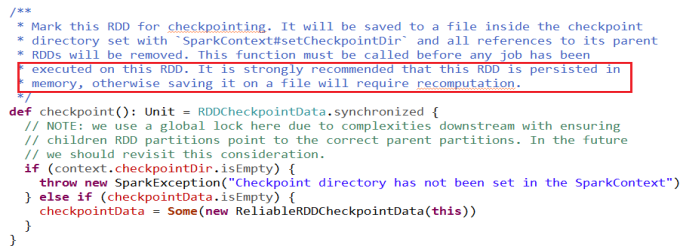
******************自己总结、操作****************
RDD的容错机制一般是通过检查点(Checkpoint)来实现的。
(1)复习检查点:HDFS中,SecondaryNameNode来合并日志
Oracle中,数据持久化
(2)RDD检查点:是一种容错机制
Lineage血统-----表示任务执行的生命周期
如果血统越长,就越容易出错
Spark基于内存计算,内存不可靠,可能会丢失中间结果,需要重新计算。
如果有检查点,出错就可以从最近的检查点往后计算,而不用从头计算。
(3)RDD检查点的类型有两种:可以通过sc.setCheckpointDir()来设置检查点
- 本地目录(略)
- HDFS目录-可用于生产:
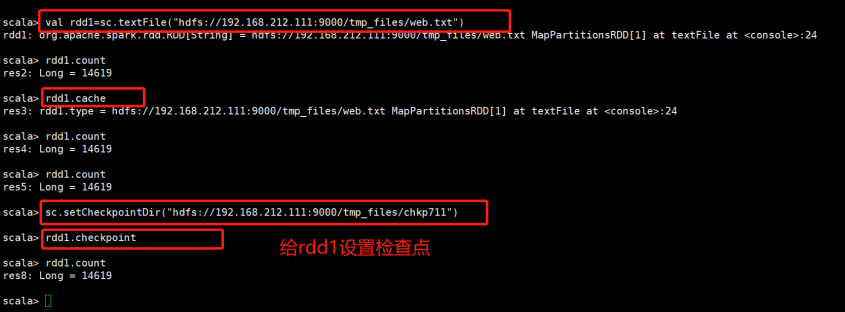
举例:设置检查点
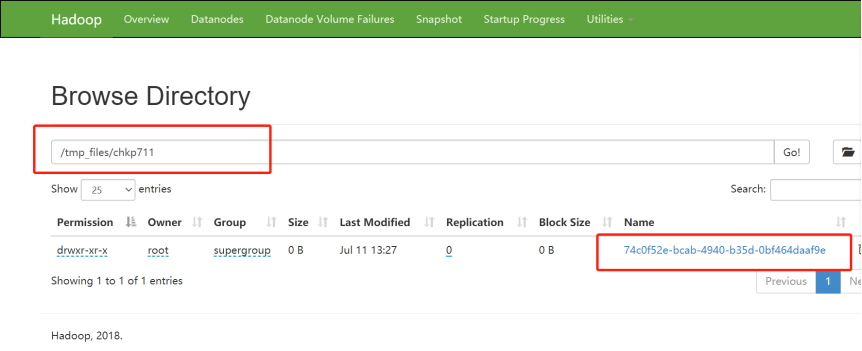
先创建一个路径在HDFS上:[root@bigdata111 /]# hadoop fs -mkdir /tmp_files/chkp711

 浙公网安备 33010602011771号
浙公网安备 33010602011771号