
Spark 2.x管理与开发-Spark Core-Spark的算子(二)Transformation*
Posted on 2020-07-12 09:55 MissRong 阅读(110) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark的算子(二)Transformation*
Transformation:延时计算lazy修饰,不会立刻触发计算。(重点)
RDD中的所有转换都是延迟加载的,也就是说,它们并不会直接计算结果。相反的,它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。
只有当发生一个要求返回结果给Driver的动作时,这些转换才会真正运行。这种设计让Spark更加有效率地运行。
|
转换 |
含义 |
|
map(func) |
对原来的RDD进行某种操作,返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成
|
|
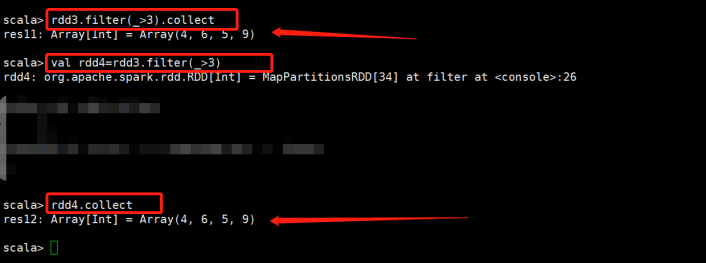
filter(func):过滤 |
返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成
|
|
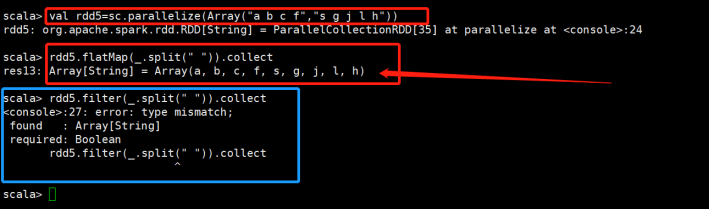
flatMap(func):压平 |
类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素)
|
|
mapPartitions(func):对RDD的每个分区进行操作 |
类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
|
mapPartitionsWithIndex(func): 对RDD的每个分区进行操作,且可以获取分区号 |
类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是(Int, Interator[T]) => Iterator[U] |
|
sample(withReplacement, fraction, seed):采样 |
根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
|
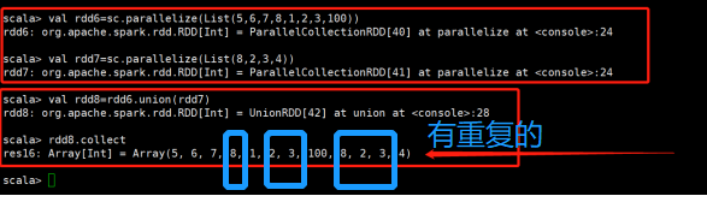
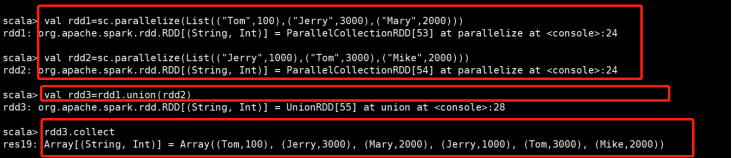
union(otherDataset):集合运算 |
对源RDD和参数RDD求并集后返回一个新的RDD
|
|
intersection(otherDataset):集合运算 |
对源RDD和参数RDD求交集后返回一个新的RDD
|
|
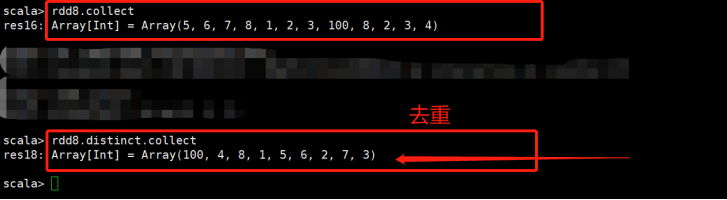
distinct([numTasks])):去重 |
对源RDD进行去重后返回一个新的RDD
|
|
groupByKey([numTasks]):底层方法 |
在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD
|
|
reduceByKey(func, [numTasks]):调用groupByKey |
在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置
|
|
aggregateByKey(zeroValue)(seqOp,combOp,[numTasks]): 调用groupByKey (常用) |
|
|
sortByKey([ascending], [numTasks]):排序 |
在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
|
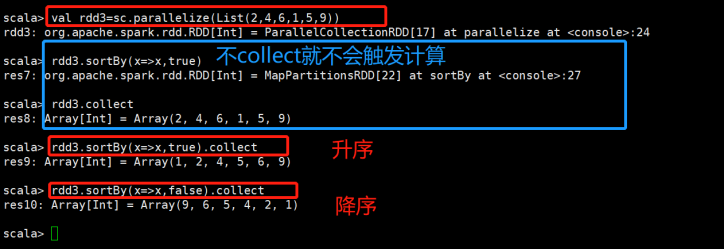
sortBy(func,[ascending], [numTasks]):排序 |
与sortByKey类似,但是更灵活
|
|
join(otherDataset, [numTasks]) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
|
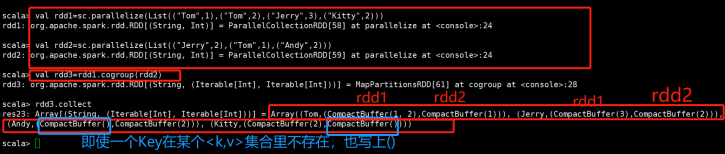
cogroup(otherDataset, [numTasks])(用到的很少) |
在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD
|
|
cartesian(otherDataset):笛卡尔积 |
笛卡尔积 |
|
pipe(command, [envVars]) |
|
|
coalesce(numPartitions) |
|
|
repartition(numPartitions):重分区 |
|
|
repartitionAndSortWithinPartitions(partitioner):重分区 |
|







需求:按照value值降序排序
做法:把kay和value交换位置,并且交换两次
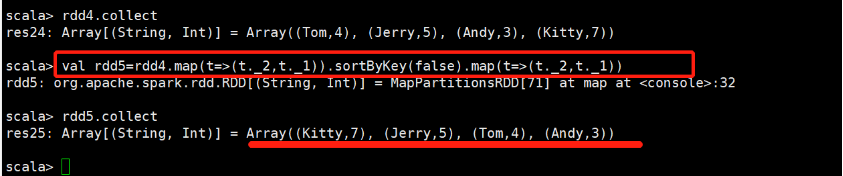
执行过程:
rdd4=Array((Tom,4), (Jerry,5), (Andy,3), (Kitty,7))
scala> val rdd5=rdd4.map(t=>(t._2,t._1)).sortByKey(false).map(t=>(t._2,t._1))
(1)rdd4.map(t=>(t._2,t._1)):交换一次---Array((4,Tom), (5,Jerry), (3,Andy), (7,Kitty))
(2).sortByKey(false):排序,倒序排序---Array( (7,Kitty),(5,Jerry),(4,Tom),(3,Andy))
(3).map(t=>(t._2,t._1)):再交换一次---Array((Kitty,7), (Jerry,5), (Tom,4), (Andy,3))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号