
Spark 2.x管理与开发-Spark Core-执行Spark Demo程序(一)使用Spark submit工具
Posted on 2020-07-08 23:13 MissRong 阅读(261) 评论(0) 收藏 举报Spark 2.x管理与开发-执行Spark Demo程序(一)使用Spark submit工具
准备:
以下操作都是在伪分布式的基础上进行的(因为全分布式状态下容易发生内存溢出状况)。
将之前开启的各个进程都停掉,修改配置文件到伪分布式的状态。
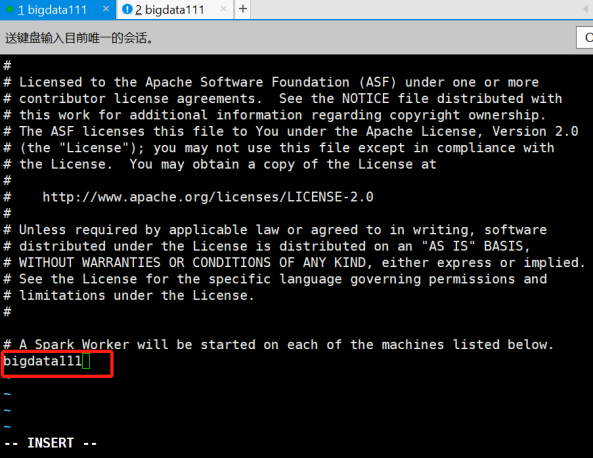
[root@bigdata111 conf]# vi slaves
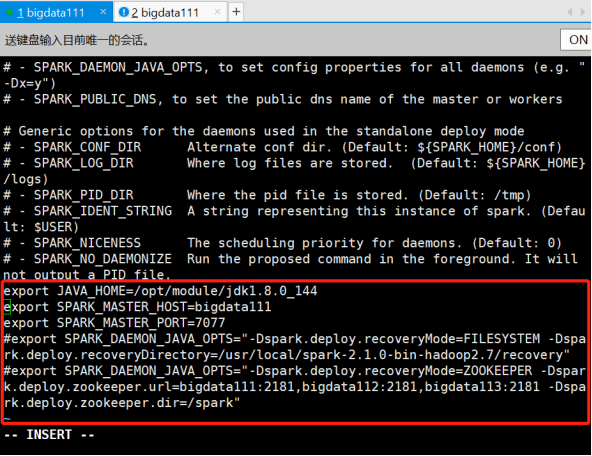
[root@bigdata111 conf]# vi spark-env.sh
接下来启动Spark的伪分布式:
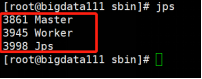
[root@bigdata111 sbin]# ./start-all.sh
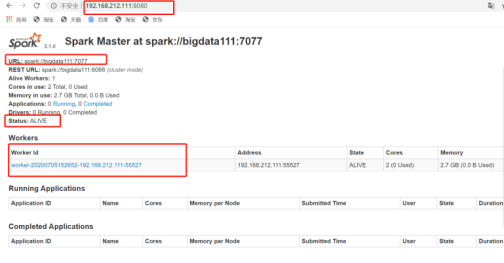
使用Spark submit工具:用于提交Spark任务
执行Spark Example程序
(1)示例程序:$SPARK_HOME/examples/jars/spark-examples_2.11-2.1.0.jar
(2)所有的示例程序:$EXAMPLE_HOME/examples/src/main
有Java、Scala等等等
(3)Demo:蒙特卡罗求PI(PI-圆周率)
命令:
spark-submit --master spark://spark81:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
********************自己操练********************
1)查看
进入路径:
/usr/local/spark-2.1.0-bin-hadoop2.7/examples/src/main/scala/org/apache/spark/examples
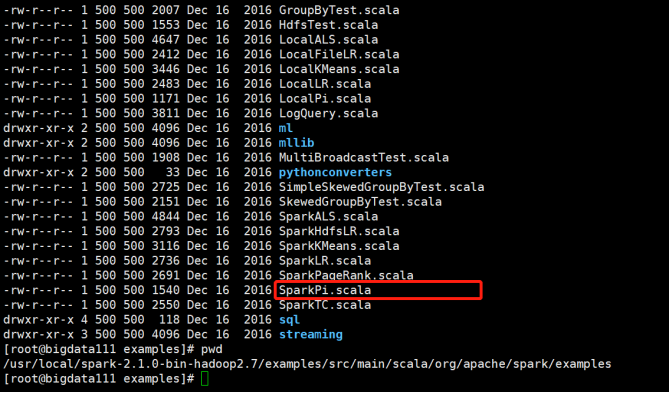
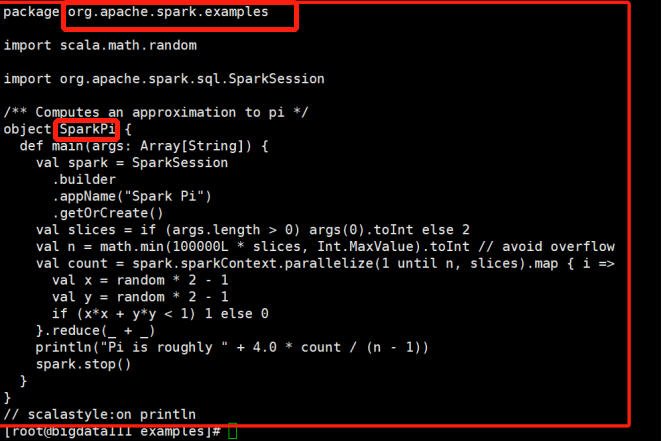
接着查看文件:SparkPi.scala 里面包含的就是蒙特卡罗求PI(PI-圆周率)的例子
cat的目的:便于之后写提交jar包命令时找到要调用类的全类名。
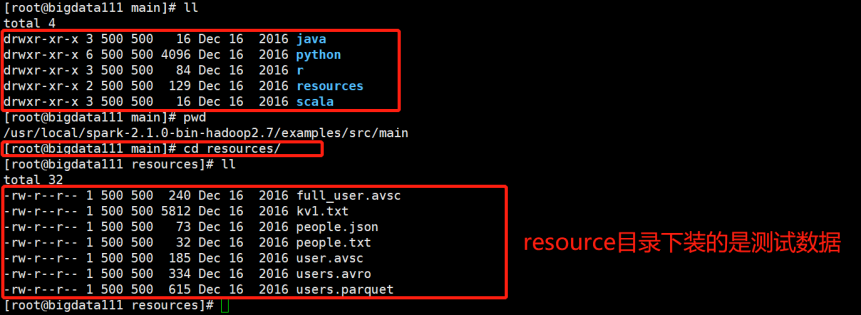
查看resource目录下内容:
进入路径:
/usr/local/spark-2.1.0-bin-hadoop2.7/examples/src/main/resources
2)提交案例
[root@bigdata111 bin]# ./spark-submit --master spark://bigdata111:7077 --class org.apache.spark.examples.SparkPi /usr/local/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jar 1000
解释:
- --class org.apache.spark.examples.SparkPi :指定提交包中要调用的class的全类名
- /usr/local/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jar:指定要提交的jar包所在的路径
- 1000:调用求Pi的类,需要传入参数-掷飞镖的次数(这里可传入1000次)
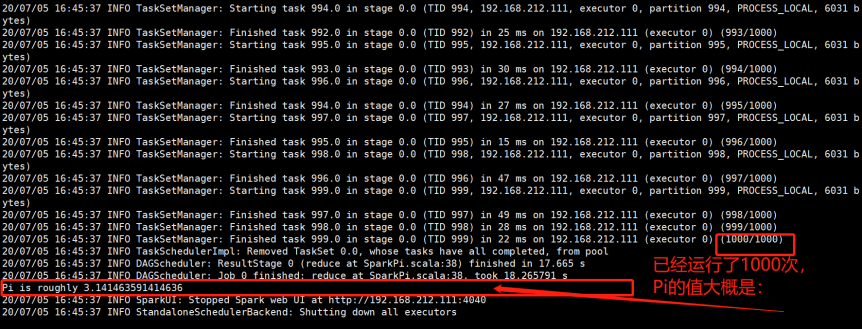
3)查看Spark可视化界面:
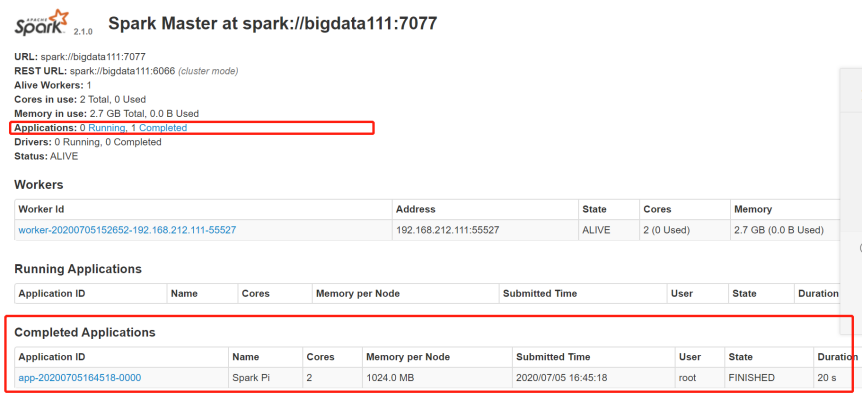
这里的Pi的值相对的来说,执行的次数越多就越精确。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号