
Spark 2.x管理与开发-Spark Core-Spark HA的实现(二)基于Zookeeper的Standby Masters
Posted on 2020-07-08 22:55 MissRong 阅读(172) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark HA的实现(二)基于Zookeeper的Standby Masters
前言:
基于Zookeeper与Hadoop类似
(1)复习Zookeeper:
Zookeeper相当于一个数据库(相当稳定的),可将集群的信息都放入Zookeeper当中。
另外,Zookeeper还提供了一些功能:数据同步、选举、分布式锁
- 数据同步:在一个节点上写数据可以快速地同步到其他节点上。
- 选举:Leader、Follower 如果Leader挂掉了,Zookeeper就会在Follower里再选举出一个Leader。
- 分布式锁:就是锁的分布式的形态。
ZooKeeper提供了一个Leader Election机制,利用这个机制可以保证虽然集群存在多个Master,但是只有一个是Active的,其他的都是Standby。
当Active的Master出现故障时,另外的一个Standby Master会被选举出来。
由于集群的信息,包括Worker, Driver和Application的信息都已经持久化到ZooKeeper,因此在切换的过程中只会影响新Job的提交,对于正在进行的Job没有任何的影响。加入ZooKeeper的集群整体架构如下图所示。
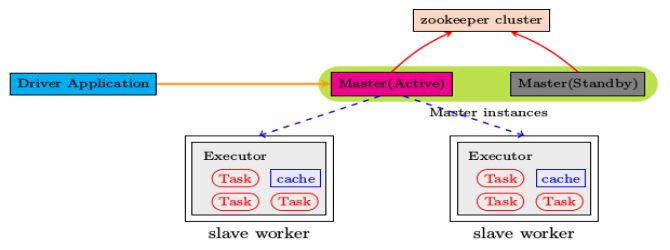
(2)大致操作概述
|
|
参考值 |
|
spark.deploy.recoveryMode |
设置为ZOOKEEPER开启单点恢复功能,默认值:NONE |
|
spark.deploy.zookeeper.url |
ZooKeeper集群的地址 |
|
spark.deploy.zookeeper.dir |
Spark信息在ZK中的保存目录,默认:/spark |
参考:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata111:2181,bigdata112:2181,bigdata113:2181 -Dspark.deploy.zookeeper.dir=/spark"
另外:每个节点上,需要将以下两行注释掉。

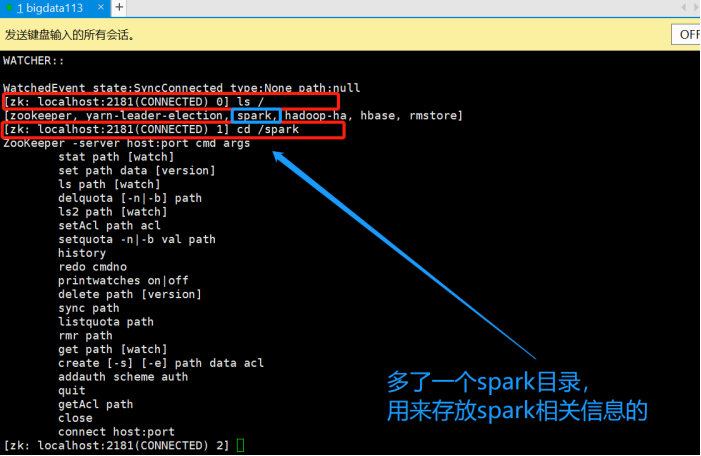
ZooKeeper中保存的信息:
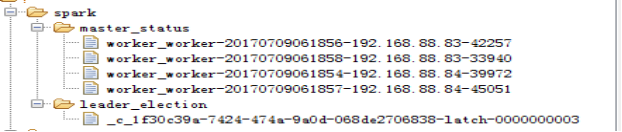
启动:
在主节点上启动 start-all
在另外从节点上 start-master.sh
************************自己操作*****************************
这里操作的是完全分布式
1.配置要保证时间的同步
(1)查看时间:date

像我这里的就是同步的
(2)如果不同步需要同步时间:
- 简单的:可以用date -s 2020-7-5来同步时间,但是这个命令的效果是三台主机时间都是2020-7的零时。
- 准确地按照自己主机的调整时间:参考 https://www.cnblogs.com/liuxinrong/articles/12818431.html
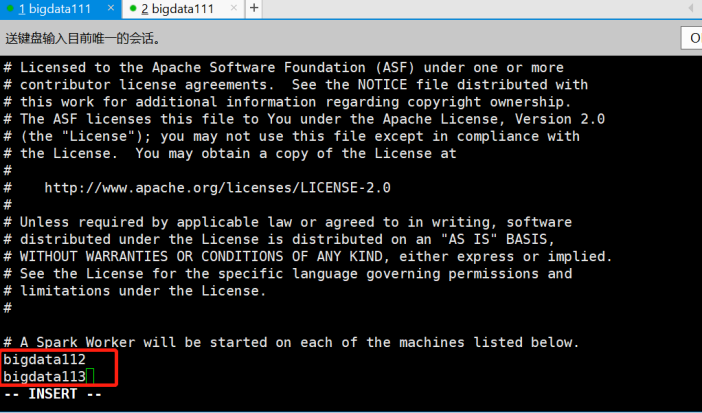
2.修改关于从节点的配置文件-slaves
[root@bigdata111 conf]# vi slaves
3.修改关于主节点的配置文件:spark-env.sh
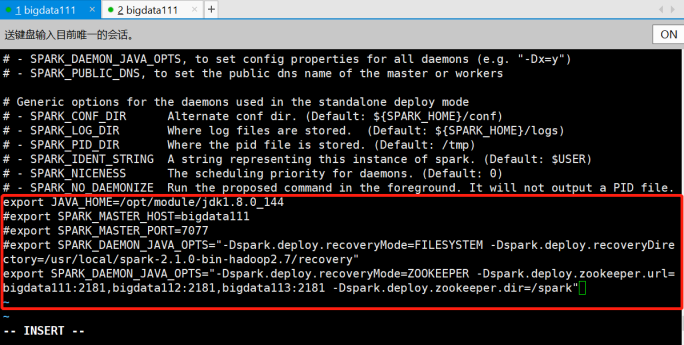
[root@bigdata111 conf]# vi spark-env.sh
由Zookeeper管理去管理Master,所以Master的相关信息要注释上。
再加上一行:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=bigdata111:2181,bigdata112:2181,bigdata113:2181 -Dspark.deploy.zookeeper.dir=/spark"
|
-Dspark.deploy.zookeeper.dir=/spark的意思是: 我们可以先进入Zookeeper的客户端进行查看: [root@bigdata113 zookeeper-3.4.10]# zkCli.sh |
4.然后将spark-env.sh发送到另外两个节点上
[root@bigdata111 conf]# scp spark-env.sh root@bigdata112:/usr/local/spark-2.1.0-bin-hadoop2.7/conf/
之前有的会被自动覆盖掉
[root@bigdata111 conf]# scp spark-env.sh root@bigdata113:/usr/local/spark-2.1.0-bin-hadoop2.7/conf/
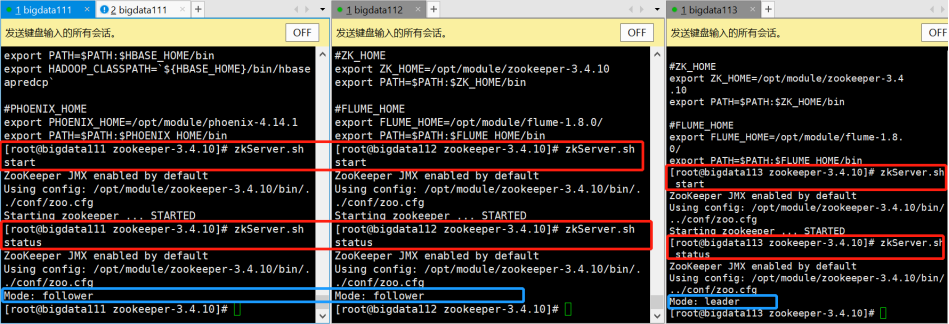
5.启动Zookeeper、查看Zookeeper状态
由于之前配置了Zookeeper环境变量,所以可以在任意路径下直接启动
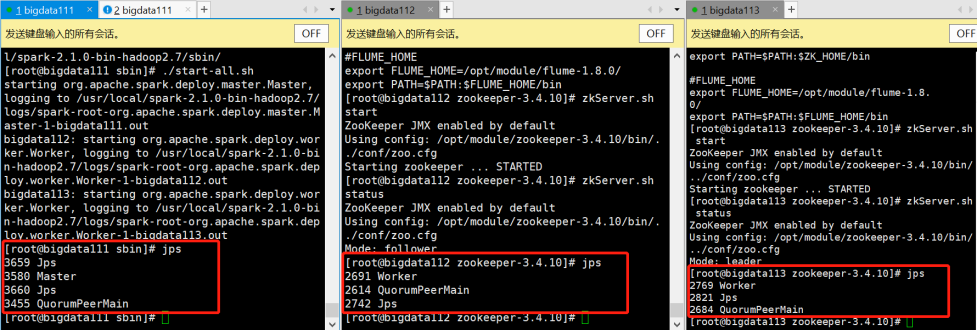
6.启动Spark
[root@bigdata111 zookeeper-3.4.10]# cd /usr/local/spark-2.1.0-bin-hadoop2.7/sbin/
[root@bigdata111 sbin]# ./start-all.sh
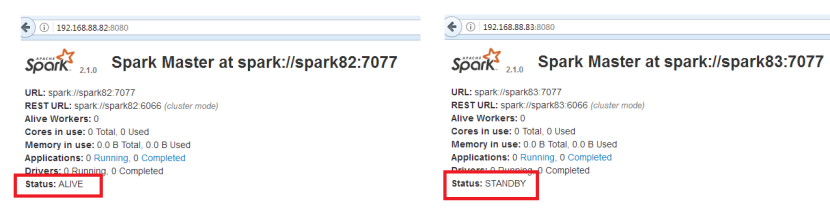
7.查看Spark可视化界面
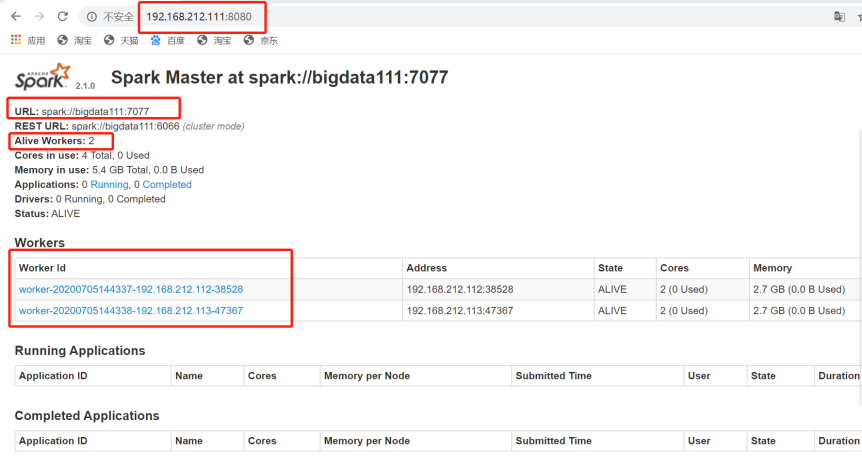
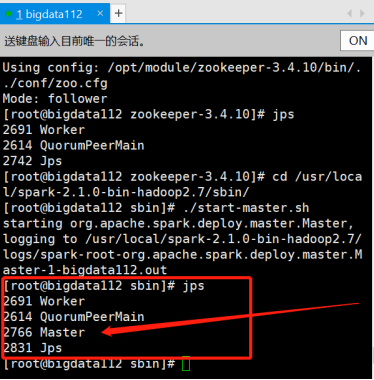
8.手动启动一个Spark的Master-在bigdata112上
[root@bigdata112 zookeeper-3.4.10]# cd /usr/local/spark-2.1.0-bin-hadoop2.7/sbin/
[root@bigdata112 sbin]# ./start-master.sh
jps查看,发现bigdata112上多了一个Master进程
9.接着打开bigdata112上的Spark的可视化页面
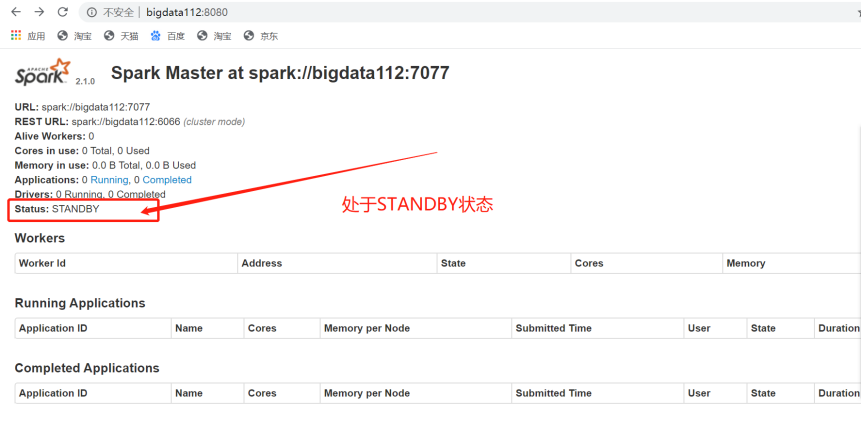
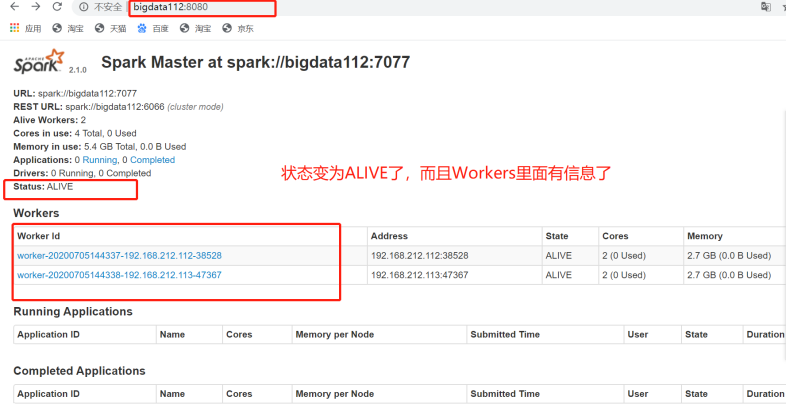
10.现在停掉bigdata111上的Master进程
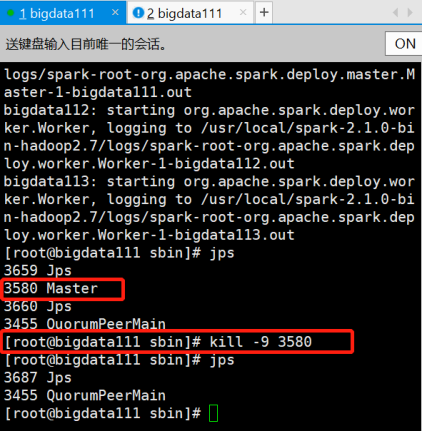
11.再刷新查看bigdata112上的Spark可视化页面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号