
Spark 2.x管理与开发-Spark Core-Spark HA的实现(一)基于文件系统的单点恢复
Posted on 2020-07-08 22:29 MissRong 阅读(145) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark HA的实现(一)基于文件系统的单点恢复
因为主从架构,所以会有单点故障
先将之前的完全分布式集群停掉:
[root@bigdata111 sbin]# ./stop-all.sh
基于文件系统(文件目录)的单点恢复
本质:还是一个主节点,创建一个恢复目录,保存集群状态和任务信息。如果Master挂掉,重新启动Master,从恢复目录中读取状态信息,恢复出原来状态。
|
主要用于开发或测试环境。当spark提供目录保存spark Application和worker的注册信息,并将他们的恢复状态写入该目录中,这时,一旦Master发生故障,就可以通过重新启动Master进程(sbin/start-master.sh),恢复已运行的spark Application和worker的注册信息。 基于文件系统的单点恢复,主要是在spark-en.sh里对SPARK_DAEMON_JAVA_OPTS设置
参考: export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/root/training/spark-2.1.0-bin-hadoop2.7/recovery" 测试: 1、在spark82上启动Spark集群 2、在spark83上启动spark shell MASTER=spark://spark82:7077 spark-shell 3、在spark82上停止master stop-master.sh 4、观察spark83上的输出:
5、在spark82上重启master start-master.sh |

*******************自己操作*******************
这里的操作是基于伪分布式的
(1)首先,创建一个恢复目录
[root@bigdata111 spark-2.1.0-bin-hadoop2.7]# mkdir recovery
(2)接着,修改配置文件-slaves、spark-env.sh
为了简单起见,将从节点改成一个节点的-bigdata111:
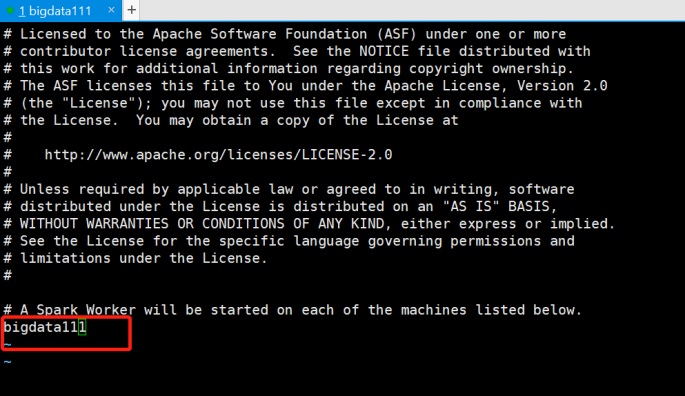
再将主节点的文件修改一下:
[root@bigdata111 conf]# vi spark-env.sh
在最后一行新加一行:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/usr/local/spark-2.1.0-bin-hadoop2.7/recovery"
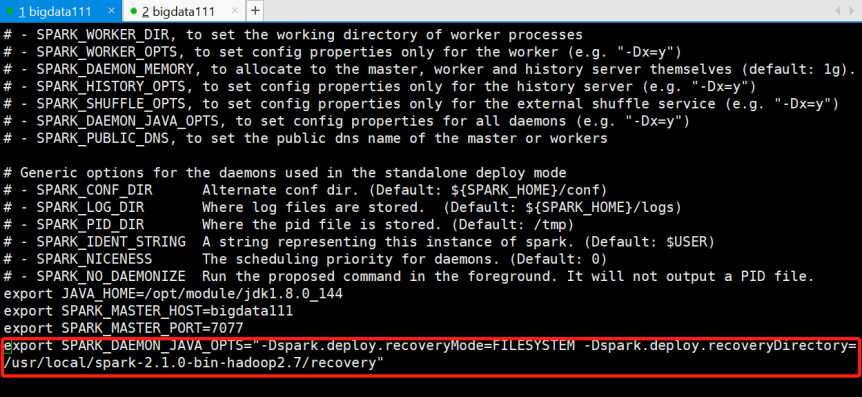
注意路径一定要真实存在!
(3)启动整个Spark集群、查看可视化界面
[root@bigdata111 sbin]# ./start-all.sh

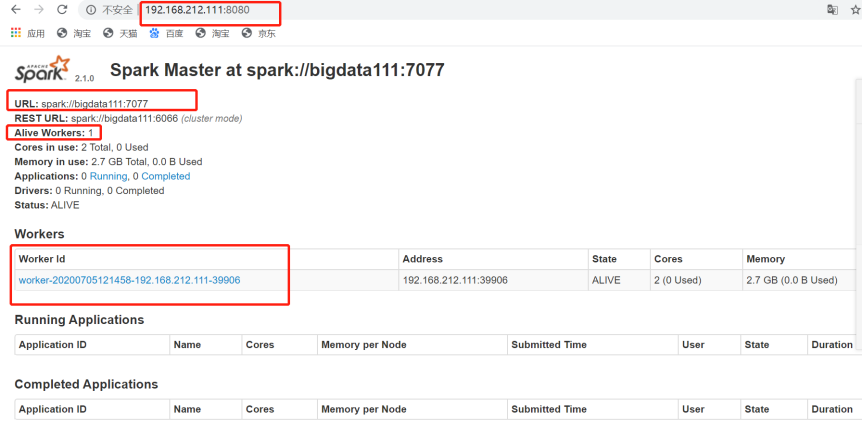
(4)查看recovery目录

可以看到已经有worker的信息(集群的状态信息)了
(5)启动Spark-shell,就能用REPL执行命令了。
[root@bigdata111 spark-2.1.0-bin-hadoop2.7]# ./bin/spark-shell --master spark://bigdata111:7077
解释:启动Spark-shell,用bigdata111启动这个集群,bigdata111就是master
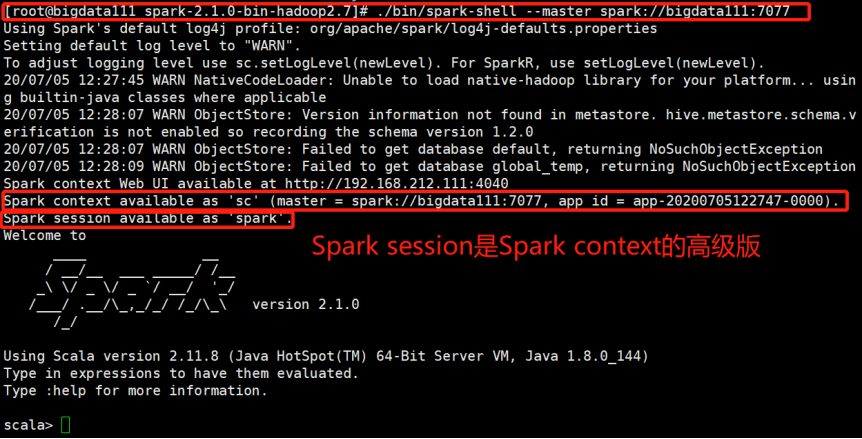
(6)再次查看recovery目录下

已经有应用程序的状态信息和集群的状态信息了
如果出现单点故障,会先去找recovery恢复目录,进行恢复,恢复到出现故障之前的状态。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号