
Spark 2.x管理与开发-Spark Core-Spark的安装与部署(三)完全分布式安装、启动
Posted on 2020-07-08 22:06 MissRong 阅读(77) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark的安装与部署(三)完全分布式安装、启动
先将之前的伪分布式集群停掉:
[root@bigdata111 sbin]# ./stop-all.sh
1)在伪分布式搭建成功的基础上,修改主节点的slaves文件:
[root@bigdata111 ~]# cd /usr/local/spark-2.1.0-bin-hadoop2.7/conf/
[root@bigdata111 conf]# vi slaves
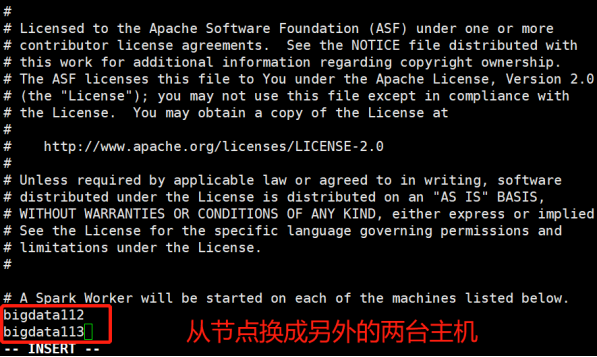
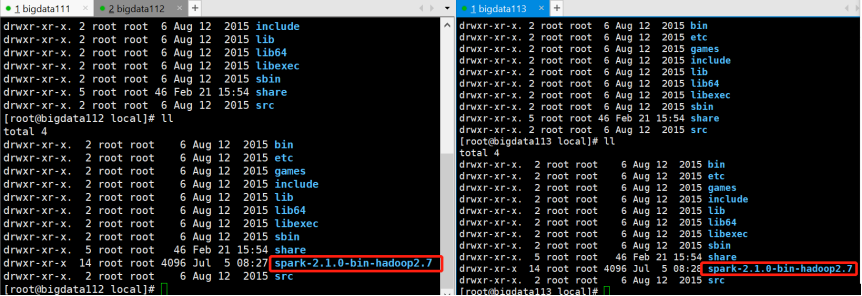
2)将bigdata111上的spark-2.1.0-bin-hadoop2.7上传到bigdata112和bigdata113上:
[root@bigdata111 local]# scp -r spark-2.1.0-bin-hadoop2.7 root@bigdata112:/usr/local/
[root@bigdata111 local]# scp -r spark-2.1.0-bin-hadoop2.7 root@bigdata113:/usr/local/
这样拷贝过去之后,Spark集群的配置信息也就随之拷贝过去了
3)启动整个Spark集群
主节点bigdata111上输入:
[root@bigdata111 sbin]# ./start-all.sh
4)jps查看启动的进程:
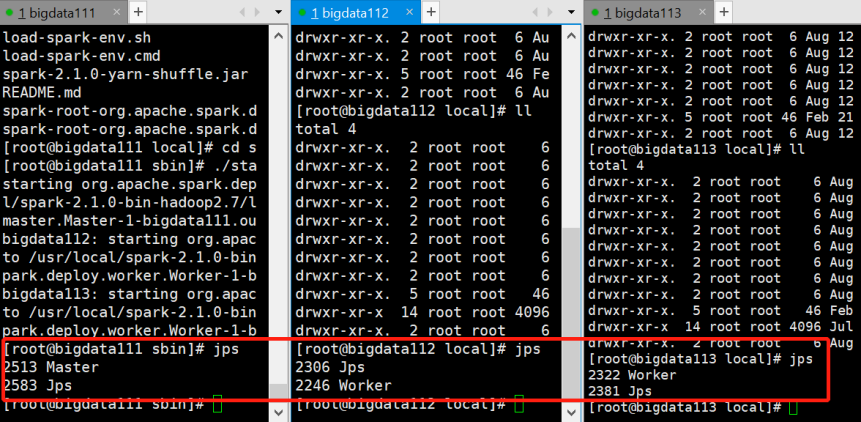
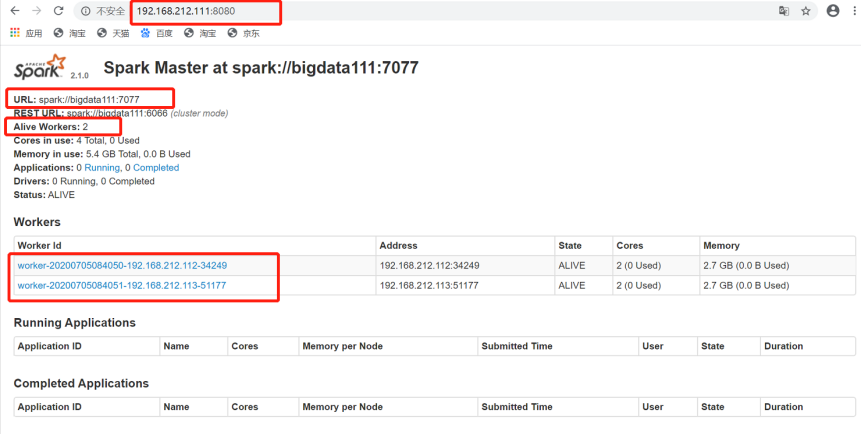
5)查看Spark可视化界面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号