
Spark 2.x管理与开发-Spark Core-Spark的安装与部署(二)伪分布式安装、启动
Posted on 2020-07-08 18:57 MissRong 阅读(106) 评论(0) 收藏 举报Spark 2.x管理与开发-Spark的安装与部署(二)伪分布式安装、启动
只有一台节点、模拟出分布式环境。Master和Worker放在一个节点上。
之前安装Hadoop的时候,我一般都将安装包啥的存入/opt/module 或/opt/software路径下
从现在起,将关于Spark的安装包啥的放在/uer/local目录下(随意,自己记住就好)
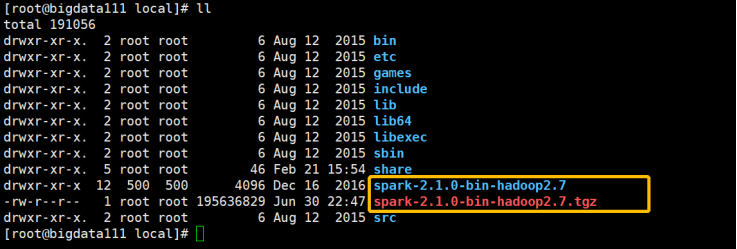
1)将压缩包拖到虚拟机上,加载完之后进行解压
[root@bigdata111 local]# tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz
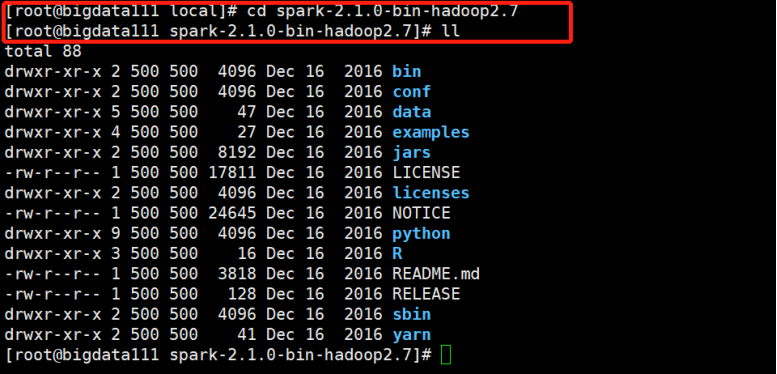
进入spark-2.1.0-bin-hadoop2.7目录下,查看:
(1)先进入上面的bin目录下,查看:
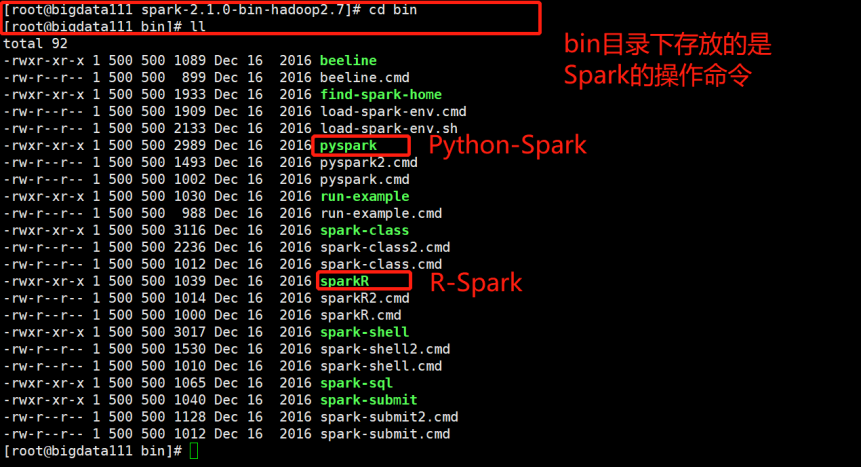
(2)再进入sbin目录下查看:
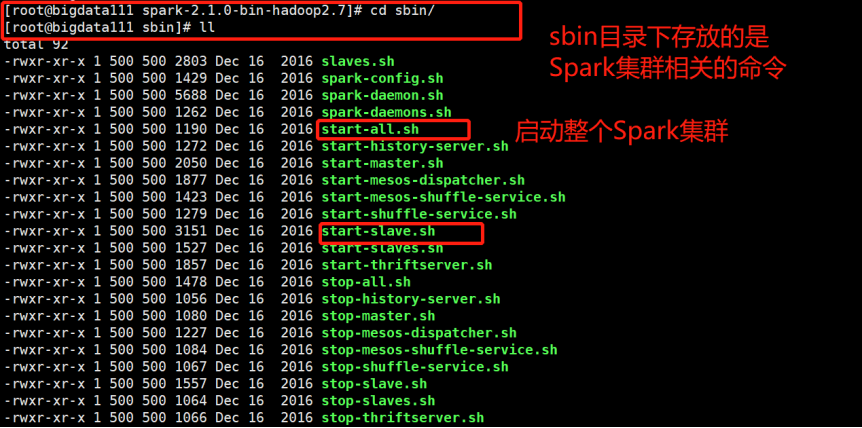
(3)接下来进入conf目录下查看:
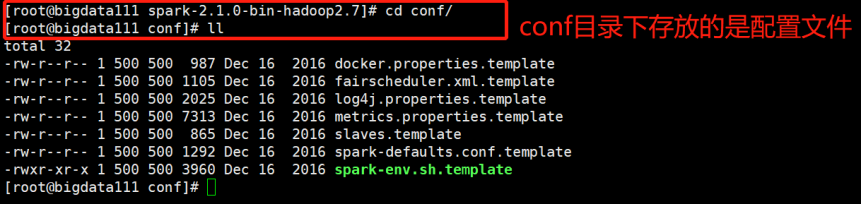
(4)再查看jars目录下的内容:
(5)examples目录下存放的就是一些Spark的例子
2)搭建为分布式-修改配置文件
(1)先修改配置文件名字,这里就先拷贝一份:
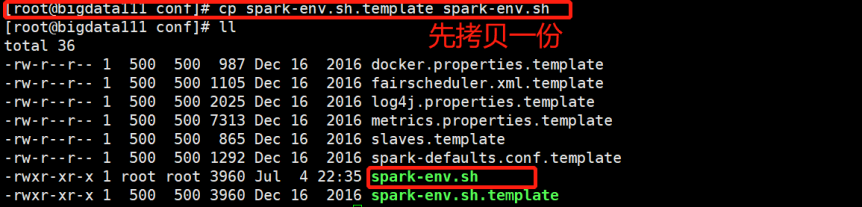
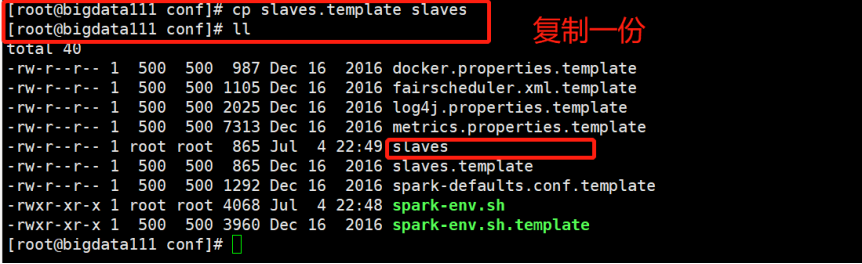
(2)进入拷贝出来的文件,改配置信息:
[root@bigdata111 conf]# vi spark-env.sh
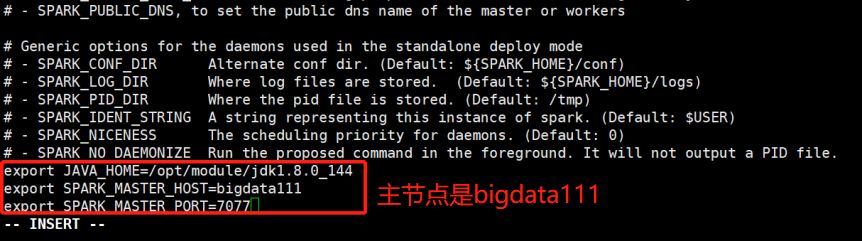
[root@bigdata111 conf]# vi slaves
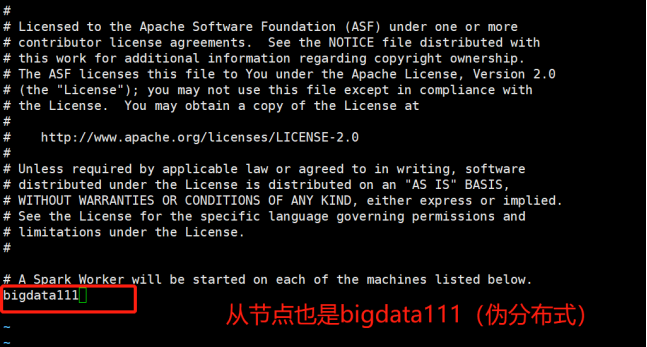
3)启动Spark伪分布式
[root@bigdata111 spark-2.1.0-bin-hadoop2.7]# cd /usr/local/spark-2.1.0-bin-hadoop2.7/sbin/
[root@bigdata111 sbin]# ./start-all.sh
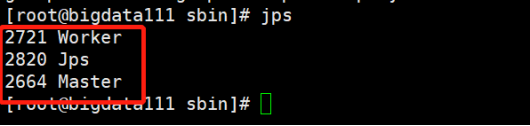
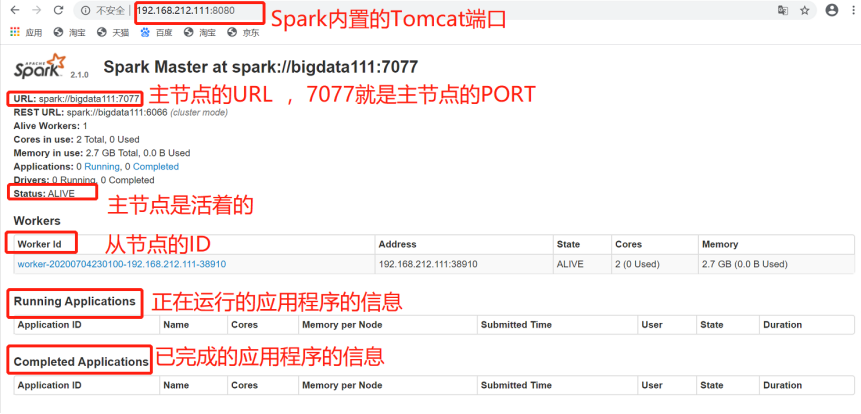
4)查看Spark可视化界面
192.168.212.111:8080/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号