
HDFS-HA集群部署
HA概述和HDFS-HA工作机制详见:https://www.cnblogs.com/liuxinrong/articles/12606059.html
一、环境准备
1)修改IP
2)修改主机名及主机名和IP地址的映射
3)关闭防火墙:systemctl status firewalld(查看)
4)ssh免密登录
检验:
[root@bigdata111 module]# ssh bigdata112
Last login: Sun Mar 22 15:36:46 2020 from 192.168.212.1
[root@bigdata112 ~]# exit
logout
Connection to bigdata112 closed.
5)安装JDK,配置环境变量等
二、规划集群
bigdata111 bigdata112 bigdata113
NameNode NameNode
JournalNode JournalNode JournalNode
DataNode DataNode DataNode
ZK ZK ZK
Zkfc Zkfc
ResourceManager
NodeManager NodeManager NodeManager
其中:JournalNode用来同步元数据的
三、配置Zookeeper集群
集群规划
在bigdata111、bigdata112和bigdata113三个节点上部署Zookeeper。
1)解压安装
(1)解压zookeeper安装包到/opt/module/目录下
[itstar@hadoop102 software]$ tar -zxvf zookeeper-3.4.10.tar.gz -C /opt/module/
(2)在/opt/module/zookeeper-3.4.10/这个目录下创建zkData
mkdir -p zkData
(3)重命名/opt/module/zookeeper-3.4.10/conf这个目录下的zoo_sample.cfg为zoo.cfg
mv zoo_sample.cfg zoo.cfg
2)配置zoo.cfg文件
(1)具体配置
dataDir=/opt/module/zookeeper-3.4.10/zkData
增加如下配置
#######################cluster##########################
server.1=bigdata111:2888:3888
server.2=bigdata112:2888:3888
server.3=bigdata113:2888:3888
(2)配置参数解读
Server.A=B:C:D。
A是一个数字,表示这个是第几号服务器;
B是这个服务器的ip地址;
C是这个服务器与集群中的Leader服务器交换信息的端口;
D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
集群模式下配置一个文件myid,这个文件在dataDir目录下,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
3)集群操作
(1)在/opt/module/zookeeper-3.4.10/zkData目录下创建一个myid的文件
touch myid
添加myid文件,注意一定要在linux里面创建,在notepad++里面很可能乱码
(2)编辑myid文件
vi myid
在文件中添加与server对应的编号:如2
(3)拷贝配置好的zookeeper到其他机器上
scp -r zookeeper-3.4.10/ root@bigdata112.itstar.com:/opt/app/
scp -r zookeeper-3.4.10/ root@bigdata113.itstar.com:/opt/app/
并分别修改myid文件中内容为2、3
(4)分别启动zookeeper、也可以同时启动
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh start
[root@hadoop104 zookeeper-3.4.10]# bin/zkServer.sh start
(5)查看状态
[root@hadoop102 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
[root@hadoop103 zookeeper-3.4.10]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: leader
[root@hadoop104 zookeeper-3.4.5]# bin/zkServer.sh status
JMX enabled by default
Using config: /opt/module/zookeeper-3.4.10/bin/../conf/zoo.cfg
Mode: follower
四、配置HDFS-HA集群-可手动故障转移
1)官方地址:http://hadoop.apache.org/
2)在opt目录下创建一个HA文件夹
mkdir HA
3)将/opt/module/下的 hadoop-2.8.4拷贝到/opt/HA目录下
cp -r hadoop-2.8.4/ /opt/HA/
因为Hadoop-HA只在bin和sbin目录下运行,所以不用配置环境变量。
4)配置hadoop-env.sh
|
export JAVA_HOME=/opt/module/jdk1.8.0_144 |
5)配置core-site.xml-在文尾复制粘贴上
|
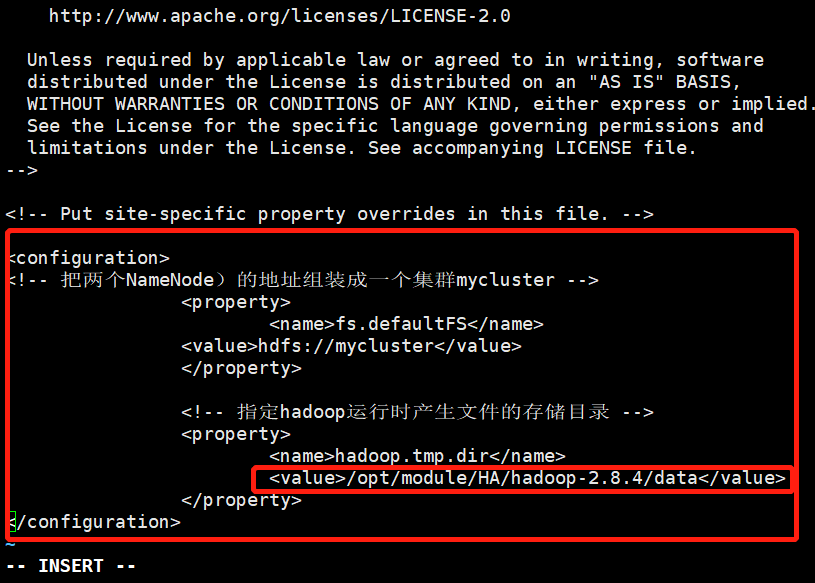
<configuration> <!-- 把两个NameNode)的地址组装成一个集群mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property>
<!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/ha/hadoop-2.8.4/data/tmp</value> </property> </configuration> |
将之前的完全分布式的配置进行修改-可先删除再粘贴:
6)配置hdfs-site.xml
|
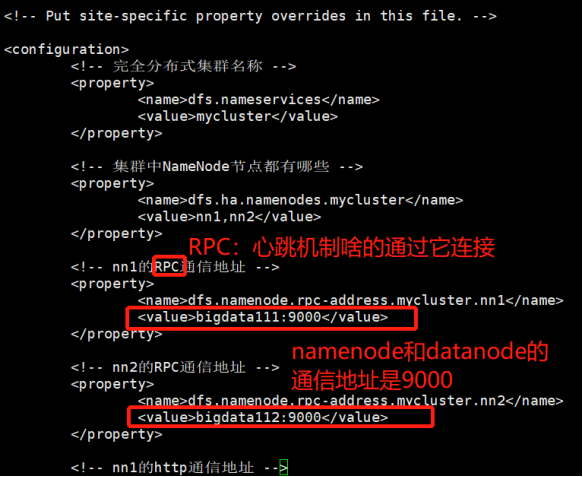
<configuration> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property>
<!-- 集群中NameNode节点都有哪些 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property>
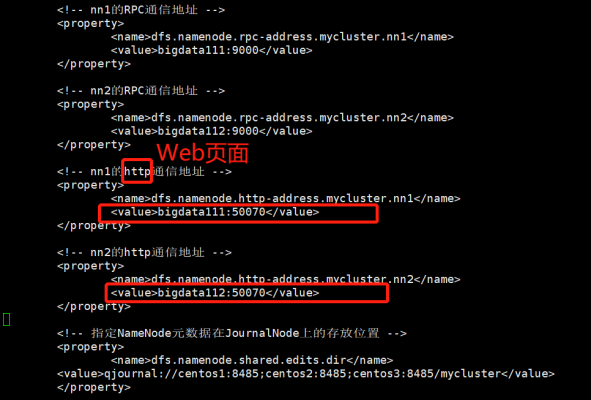
<!-- nn1的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>centos1:9000</value> </property>
<!-- nn2的RPC通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>centos2:9000</value> </property>
<!-- nn1的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>centos1:50070</value> </property>
<!-- nn2的http通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>centos2:50070</value> </property>
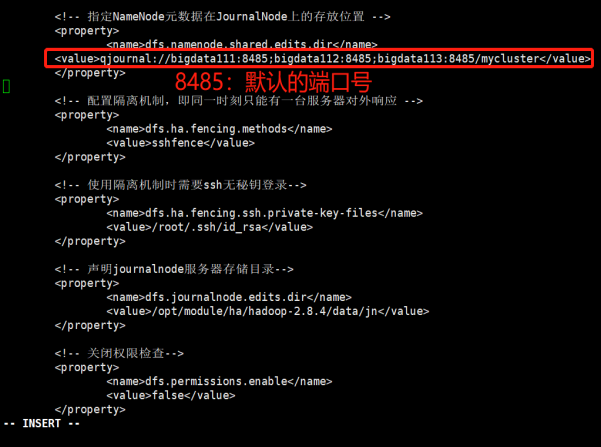
<!-- 指定NameNode元数据在JournalNode上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://centos1:8485;centos2:8485;centos3:8485/mycluster</value> </property>
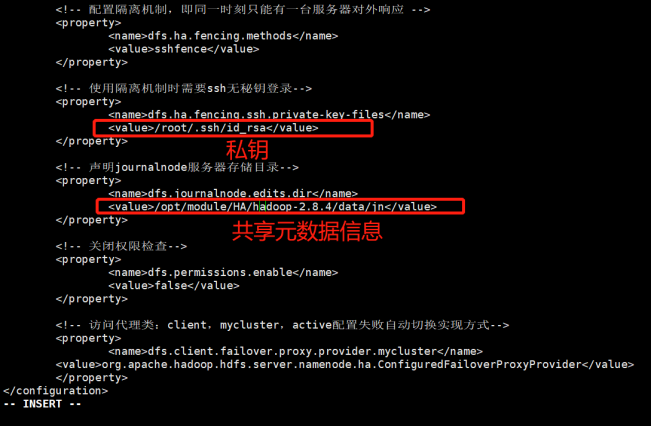
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property>
<!-- 使用隔离机制时需要ssh无秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property>
<!-- 声明journalnode服务器存储目录--> <property> <name>dfs.journalnode.edits.dir</name> <value>/opt/module/ha/hadoop-2.8.4/data/jn</value> </property>
<!-- 关闭权限检查--> <property> <name>dfs.permissions.enable</name> <value>false</value> </property>
<!-- 访问代理类:client,mycluster,active配置失败自动切换实现方式--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> </configuration> |
注意修改主机的名字
7)拷贝配置好的hadoop环境传送到其他节点
|
可以不用)为了不出现之前的一些错误啥的,先将/opt/module/zookeeper-3.4.10/zkData目录下的version-2目录删除,来清理一下日志文件---rm -rf version-2/,注意:如果有zookeeper.out样的文件,也将其删除,目录/opt/module/zookeeper-3.4.10/bin下的zookeeper.out也是。 (2)此时应先关闭Zookeeper进程:[root@bigdata111 bin]# ./zkServer.sh stop 注意:删除之前要注意在/opt/module/HA/hadoop-2.8.4/目录下创建目录data(如果没创建的话~) mkdir data 删除/opt/module/HA/hadoop-2.8.4目录下,data和logs里的所有文件:rm -rf data/* logs/* |
五、启动HDFS-HA集群
注意:
1.Hadoop集群要关闭
stop-dfs.sh、stop-yarn.sh
实在关闭不了的情况下可以使用:kill -9 进程号 进程号 ...
2.Zookeeper进程可先关闭着:[root@bigdata111 bin]# ./zkServer.sh stop
1)调到该目录下:/opt/module/HA/hadoop-2.8.4/sbin
在各个JournalNode节点上,输入以下命令启动journalnode服务:
sbin/hadoop-daemon.sh start journalnode
2)在[nn1]上,对其进行格式化namenode,并启动namenode:
bin/hdfs namenode -format 如果中间问了问题,就意味着哪哪有问题。
sbin/hadoop-daemon.sh start namenode
3)在[nn2]上,同步nn1的元数据信息:
[root@bigdata112 hadoop-2.8.4]# bin/hdfs namenode -bootstrapStandby
4)启动[nn2]:
sbin/hadoop-daemon.sh start namenode
5)查看web页面显示
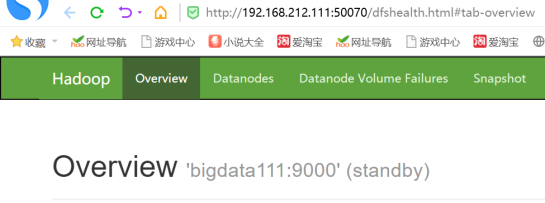
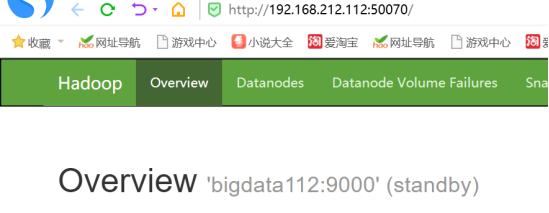
6)启动所有datanode
sbin/hadoop-daemons.sh start datanode
7)查看是否Active
bin/hdfs haadmin -getServiceState nn1
********************************手动切换******************************
8)将[nn1]切换为Active
bin/hdfs haadmin -transitionToActive nn1
同理:将[nn1]切换为Standby
bin/hdfs haadmin -transitionToStandby nn1
完全分布式:使用环境变量启动-可以在Linux的任何目录下运行Hadoop的命令
Zookeeper:也和完全分布式同理,能在任何目录下运行zk的命令
HA: 不配置环境变量-必须去hadoop的sbin目录下启动--不配环境变量的原因:易混
六、配置HDFS-HA自动故障转移
1)具体配置-三台同时配置--/opt/module/HA/hadoop-2.8.4/etc/hadoop/下
(1)在hdfs-site.xml中增加
|
<property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> |
(2)在core-site.xml文件中增加
|
<property> <name>ha.zookeeper.quorum</name> <value>bigdata111:2181,bigdata112:2181,bigdata113:2181</value> </property> |
2)启动
(1)关闭所有HDFS服务:
关闭namenode和datanode
bigdata111上:sbin/stop-dfs.sh
如果bigdata112上的namenode还未关(因为此时的Hadoop不是之前配置的,这个是HA里的,需要写全目录),则进行关闭:
[root@bigdata112 hadoop-2.8.4]# pwd/opt/module/HA/hadoop-2.8.4[root@bigdata112 hadoop-2.8.4]# sbin/hadoop-daemon.sh stop namenode
实在不行就kill -9 掉
(2)三台启动Zookeeper集群:
bin/zkServer.sh start
(3)注意:配置手动故障转移完事后,上面的journalnode服务还是启动的,并未关,可以不用管它,直接进行下面的操作。
(4)在一台上初始化HA在Zookeeper中状态:
bin/hdfs zkfc -formatZK
(setAcl /rmstore/ZKRMStateRoot world:anyone:cdrwa)
(5)启动HDFS服务:shiqidongde
sbin/start-dfs.sh
如果先执行了手动故障转移-DFSZKFC如果已经启动的话,就可以不用执行第(5)步,如果是直接执行自动的就需要。
(6)在各个NameNode节点上启动DFSZK Failover Controller,先在哪台机器启动,哪个机器的NameNode就是Active NameNode
sbin/hadoop-daemon.sh start zkfc
jps后是这样的:
[root@bigdata111 hadoop-2.8.4]# jps4272 DataNode3942 QuorumPeerMain2312 JournalNode4138 NameNode4634 Jps4557 DFSZKFailoverController
[root@bigdata112 bin]# jps3444 QuorumPeerMain3750 DFSZKFailoverController2312 JournalNode3528 NameNode3595 DataNode3835 Jps
[root@bigdata113 bin]# jps2708 DataNode2630 QuorumPeerMain2311 JournalNode2813 Jps
3)验证
(1)到Web端查看节点状态active/standby,将Active NameNode进程kill掉
kill -9 namenode的进程id
不建议下面的方式,网卡会乱:
(2)将Active NameNode机器断开网络
service network stop不建议用
重新刷新Web端,查看active点转移没有,如果没有,就可能是fuser执行失败了,
shift+g跳到最后一行找异常
|
Hadoop的ha配置自动故障转移后,杀死active所在的namenode,Standby所在的namenode不会自动切换为active状态。 分析错误:查看zkcf的log日志 发现错误日志: 2019-05-05 03:59:38,306 WARN org.apache.hadoop.ha.SshFenceByTcpPort: PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 9000 via ssh: bash: fuser: command not found 解决错误:这个原因是Linux系统没有fuser命令 导致在HA进行主备切换是执行fuser失败了 查看fuser命令是哪个包下的:yum search fuser
====================Matched: fuser ===================psmisc.x86_64 : Utilities for managing processes on your system 通过yum命令安装-三台都安装:yum -y install psmisc -y就是会默认直接交互 安装完成再次测试,即可切换成功。 |
启动namenode节点
重新杀死,查看是否故障转移


 浙公网安备 33010602011771号
浙公网安备 33010602011771号