
官方Hbase_MapReduce(一)【HbaseToHbase】
目标:实现Hbase数据库中,选取表city的数据到city_mr表。
分步实现:map+reduce
一、HbaseMapper类
package HbaseMr; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellUtil; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapper; import org.apache.hadoop.hbase.util.Bytes; import java.io.IOException; /** * Author : ASUS and xinrong * Version : 2020/4/23 & 1.0 * Mapper-查询city表,将name写到city_mr表中 * 继承Hbase的TableMapper父类 */ public class HbaseMpper extends TableMapper<ImmutableBytesWritable,Put> { @Override protected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException { //2.提取出city表的数据,封装成Put写到Reduce当中 Put put = new Put(key.get()); //1.遍历原来表里的column,获取到每一个列簇、列,捕捉到符合的列 for(Cell cell : value.rawCells()){ if("cf".equals(Bytes.toString(CellUtil.cloneFamily(cell)))){ //put对象中添加countries if("countries".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))){ put.add(cell); } } } context.write(key,put); } }
二、HbaseReducer类
package HbaseMr; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableReducer; import org.apache.hadoop.io.NullWritable; import java.io.IOException; /** * Author : ASUS and xinrong * Version : 2020/4/23 & 1.0 */ public class HbaseReducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> { @Override protected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException { //将Mapper获取的数据写入到对应的city_mr表中 for(Put put:values){ context.write(NullWritable.get(),put); } } }
三、CityToCity_mr类-测试类
package HbaseMr; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.io.ImmutableBytesWritable; import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * Author : ASUS and xinrong * Version : 2020/4/23 & 1.0 */ public class CityToCity_mr extends Configured implements Tool { @Override public int run(String[] strings) throws Exception { //1.获取配置文件 Configuration conf = this.getConf(); //2.创建一个job任务 Job job = Job.getInstance(conf, getClass().getSimpleName()); job.setJarByClass(CityToCity_mr.class); //3.创建一个扫描器 Scan scan = new Scan(); //4.配置map TableMapReduceUtil.initTableMapperJob( //1)读数据的表是哪张表 "city", //2)扫描器 scan, //3)设置map类 HbaseMpper.class, //4)设置输出数据类型 ImmutableBytesWritable.class, Put.class, //5)配置给job任务 job ); //5.配置reduce TableMapReduceUtil.initTableReducerJob( //1)将数据写到city_mr中 "city_mr", //2)设置reduce表 HbaseReducer.class, //3)输出put-这是默认的不用配置 //4)配置给job任务 job ); //6.设置reduce个数 job.setNumReduceTasks(1); //7.运行状态 boolean status = job.waitForCompletion(true); //8.判断状态 if(status){ System.out.println("运行成功!"); return 0; }else{ System.out.println("运行失败!"); return 1; } } public static void main(String[] args) throws Exception { Configuration conf = HBaseConfiguration.create(); int status = ToolRunner.run(conf, new CityToCity_mr(), args); System.exit(status); } }
四、执行
1.Maven打包:clean+package
2.新创建一个目录-myjob
/opt/module/hbase-1.3.1/myjob
3.上传刚打包好的jar包到此目录下
[root@bigdata111 myjob]# ll
total 16
-rw-r--r-- 1 root root 14849 Apr 25 14:51 hbase-1.0-SNAPSHOT.jar
4.执行命令:
/opt/module/hadoop-2.8.4/bin/yarn jar /opt/module/hbase-1.3.1/myjob/hbase-1.0-SNAPSHOT.jar HbaseMr.CityToCity_mr
HbaseMr.CityToCity_mr 这个是主类的全类名
尖叫提示:运行任务前,如果待数据导入的表不存在,则需要提前创建之。
五、结果
1.运行之前的city_mr表:
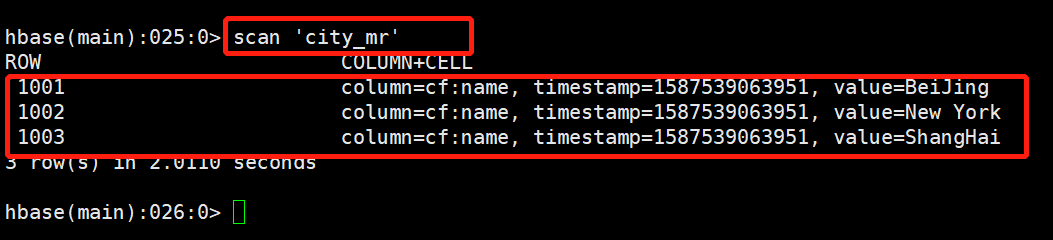
2.运行日志


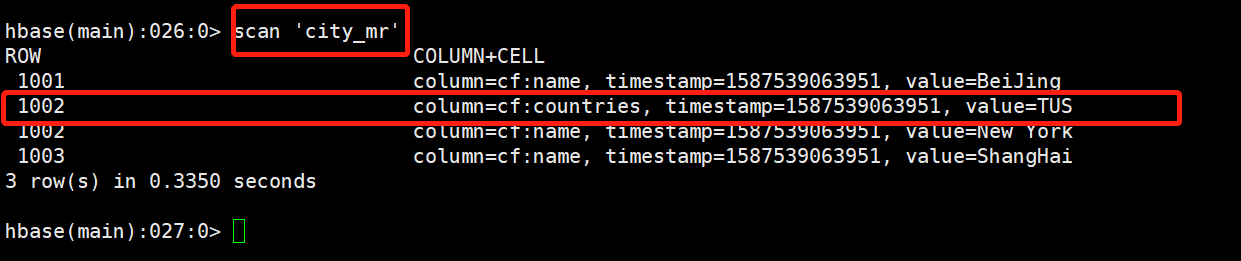
3.查看city_mr表的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号