
Hadoop-伪分布式搭建
一、准备工作
伪分布式就是一个节点跑一个集群,前提条件:主机名、防火墙都设置好。

检查:
1.主机名:
[root@bigdata111 ~]# vi /etc/hosts
像这个样子写上自己主机IP和主机名的映射关系:

[root@bigdata111 ~]# vi /etc/sysconfig/network-scripts/ifcfg-eno16777736
2.防火墙:
[root@bigdata111 ~]# systemctl status firewalld.service
● firewalld.service - firewalld - dynamic firewall daemon Loaded: loaded (/usr/lib/systemd/system/firewalld.service; disabled; vendor preset: enabled)
Active: inactive (dead)
二、环境配置
1.确认配置是否完成
包括:https://www.cnblogs.com/liuxinrong/articles/12627362.html
2.搭建Hadoop伪分布式集群
上面的准备都确认完毕,再搭建伪Hadoop分布式集群
目前做的是伪分布式,只有bigdata111这一台虚拟机,所以先配置这一台即可。完全分布才需要配置三台。
集群部署规划:
|
|
bigdata111 |
bigdata112 |
bigdata113 |
|
HDFS
|
NameNode 元数据 SecondaryNameNode 监控HDFS状态的辅助后台程序 DataNode 数据块-记录实际的数据 |
DataNode |
DataNode |
|
YARN |
ResourceManager NodeManager 单个节点上的资源管理 |
NodeManager |
NodeManager
|
3.进入hadoop目录配置etc
cd /opt/module/hadoop-2.8.4/
sbin和bin目录是一些命令,etc和它里面的hadoop存的都是一些配置文件,lib中存放的就是一些.jar包,share下面存的是一些案例.jar包。
输入命令:cd etc/hadoop/
1)先配置文件core-site.xml
vi core-site.xml
配置文件内容:
|
文件 |
配置 |
|
core-site.xml |
<!-- 指定HDFS中NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://主机名1:9000</value> </property>
<!-- 指定hadoop运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-2.X.X/data/tmp</value> </property> |
将针对此文件的配置内容复制到此文件的19-20行之间,结果如下图所示:

修改NameNode地址和Hadoop运行时产生文件的存储目录-根据情况自定义。
(1)NameNode地址
将主机名1改成自己的bigdata111即可。
(2)修改存储目录
输入命令行:
[root@bigdata111 ~]# cd /opt/module/hadoop-2.8.4/
[root@bigdata111 hadoop-2.8.4]# ll
然后在此目录下创建两个文件夹:logs、dada,用来存储日志和数据。
然后将data文件的绝对路径复制粘贴到需要修改的存储目录上,结果如下图所示:
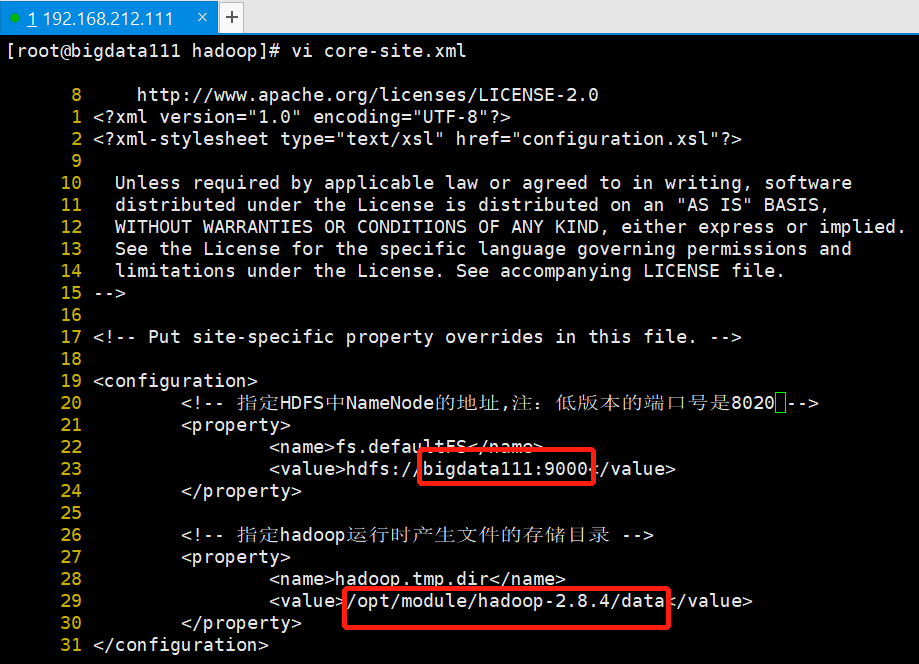
最后保存离开。
2)同理,配置文件hdfs-site.xml,配置文件内容如下:
|
文件 |
配置 |
|
hdfs-site.xml |
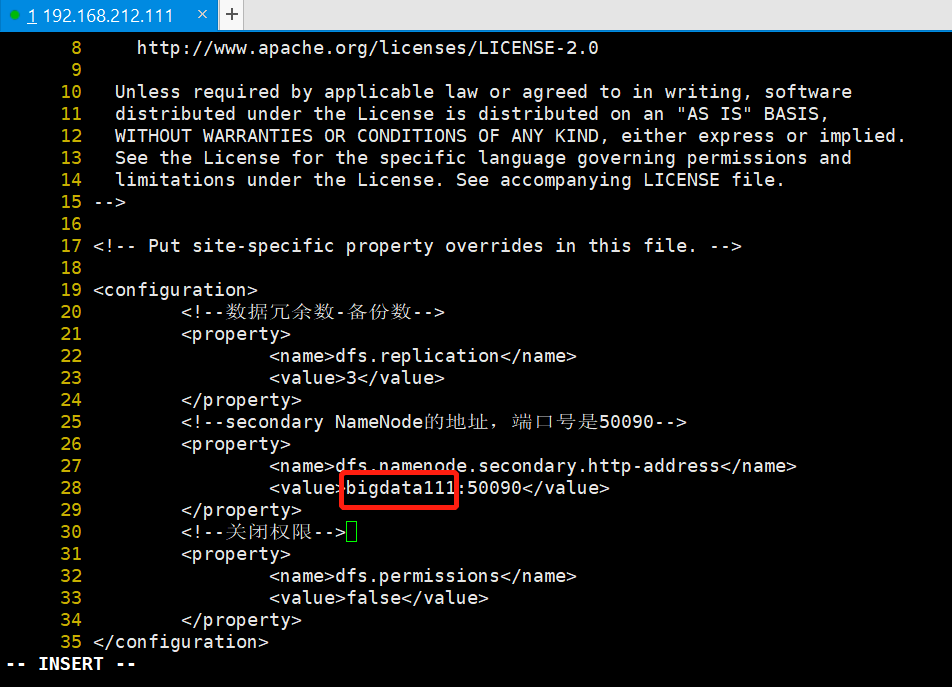
<!--数据冗余数--> <property> <name>dfs.replication</name> <value>3</value> </property> <!--secondary namenode的地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>主机名1:50090</value> </property> <!--关闭权限--> <property> <name>dfs.permissions</name> <value>false</value> </property> |
进行适当修改,结果如下图所示:
3)同理,配置yarn-site.xml,配置文件内容如下:
|
文件 |
配置 |
|
yarn-site.xml |
<!-- reducer获取数据的方式 --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
<!-- 指定YARN的ResourceManager的地址 --> <property> <name>yarn.resourcemanager.hostname</name> <value>主机名1</value> </property> <!-- 日志聚集功能使能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 日志保留时间设置7天(秒) --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> |
结果如下图所示:
删掉原文件的第17行后配置的结果图如下:

4)同理,配置文件mapred-site.xml
注意:输入命令中按tab之后会出现 vi mapred-site.xml.template ,只要将其更改名字即可。
输入:mv mapred-site.xml.template mapred-site.xml 更改文件名。
配置文件内容如下:
|
文件 |
配置 |
|
mapred-site.xml |
<!-- 指定mr运行在yarn上--> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!--历史服务器的地址--> <property> <name>mapreduce.jobhistory.address</name> <value>主机名1:10020</value> </property> <!--历史服务器页面的地址--> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>主机名1:19888</value> </property> |
配置结果如下图:

5)配置JDK的环境变量
输入:vi /etc/profile
复制此系统环境变量中的内容:export JAVA_HOME=/opt/module/jdk1.8.0_144
将/opt/module/hadoop-2.8.4/etc/hadoop下的三个.sh文件依次打开,然后将复制的这句话粘贴到文件的末尾。
这三个文件就是下图中框出来的三个:
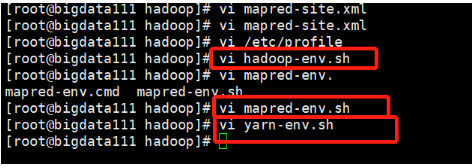
6)接着修改此目录下的文件slaves
进入此文件--》将原来的localhost修改成bigdata111。
至此,伪分布式的环境就搭建成功了。
7)hadoop-env.sh 指定JDK
[root@master hadoop]# vi hadoop-env.sh
修改参数:
export JAVA_HOME=/opt/module/jdk1.8.0_181
三、格式化namenode
环境搭建成功后,接下来输入命令hdfs namenode -format 进行namenode的格式化
如果输出的含有以下内容则视为格式化成功:Storage directory /opt/module/hadoop-2.8.4/data/dfs/name has been successfully formatted.
四、启动伪分布式集群
1)输入:start-all.sh(目前还未配置SSH-免密登陆)开启所有进程
会问问题:Are you sure you want to continue connecting (yes/no)? 回答yes即可。
之后会让输入4次密码-000000
如果要配置免密登陆,参考:https://www.cnblogs.com/liuxinrong/articles/12673499.html
2)最后输入命令行:jps 查看进程,输出如下:
[root@bigdata111 hadoop]# jps
3473 ResourceManager
3873 Jps
3171 DataNode
3747 NodeManager
3047 NameNode
3326 SecondaryNameNode
最前面的就是进程号
3)然后进入该伪分布式页面
点进浏览器--》输入IP地址
查IP的方式:输入ip addr
在输出的结果中找到:inet 192.168.212.111/24 brd 192.168.212.255 scope global eno16777736
说明我们的IP是192.168.212.111,将其复制粘贴到浏览器加上 :50070 注意:这里的冒号一定得是英文状态下的。之后回车搜索即可。
4)其他操作:
在最上面的栏目上点击Utilities -->点进Browse Directory-->之后在最大标题下的输入栏上输入“/”
在Xshell上输入:hadoop fs -put slaves /
此命令解释:Hadoop 文件 从本地推slaves到集群上去,推到 / 目录下
可在页面上右侧的Name里查看上传的文件。
五、常见错误总结
1.系统环境配置情况
2.输入命令行:java -version
3.输入命令行:javac
4.Hadoop检查:输入:start-dfs.sh 这个如果能tab出来就可以
5.输入:jps,如果NameNode没有显示出来,就输入:hdfs namenode -format 进行namenode的格式化
6.如果其它都正常,但是登陆页面之后什么都找不见。那就先查看防火墙是否是开着的,将他禁掉才可以。
7.如果进程不全(除了NameNode),可以到日志中查找,cd /opt/module/hadoop-2.8.4/logs/ 根据错误查看以.log为结尾的文件(可以cat点进去查看,一般会报错),再重新配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号