
案例四:扇入(fan in)-Flume与Flume之间数据传递,多Flume汇总数据到单Flume
目标:flume-1监控文件hive.log,flume-2监控某一个端口的数据流,flume-1与flume-2将数据发送给flume-3,flume-3将最终数据写入到HDFS。
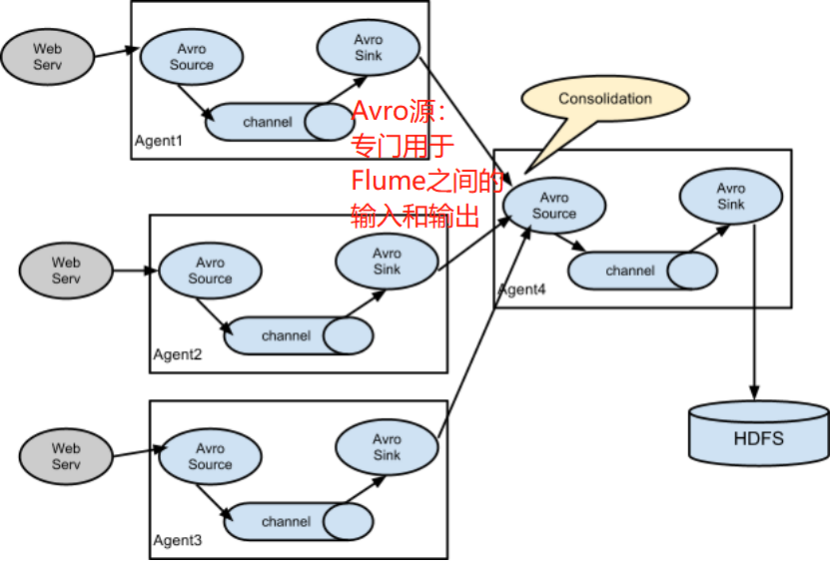
分步实现:
1.创建flume-1.conf,用于监控55555端口,同时sink数据到bigdata113
|
#定义agent的三个角色 # 1 agent a1.sources = netcat-a1 a1.sinks = avro113 a1.channels = c1
#配置source # 2 source #bigdata111监控端口 a1.sources.netcat-a1.type = netcat #端口所在的地址-监控本机 a1.sources.netcat-a1.bind = bigdata111 #监控的端口(随意-不要和之前的重复) a1.sources.netcat-a1.port = 55555
#配置sink # 3 sink-avro是用于flume之间的资源 a1.sinks.avro113.type = avro a1.sinks.avro113.hostname = bigdata113 #端口不能和之前的冲突 a1.sinks.avro113.port = 4141
#配置channel # 4 channel #存到内存-memory a1.channels.c1.type = memory #channel的大小 a1.channels.c1.capacity = 1000 #每次可以从channel拿出数据的多少 a1.channels.c1.transactionCapacity = 100
#连接source,channels # 5. Bind a1.sources.netcat-a1.channels = c1 a1.sinks.avro113.channel = c1 |
2. 创建flume-2.conf,用于监控端口55555数据流,同时sink数据到bigdata113
|
#定义agent的三个角色 # 1 agent a2.sources = tail-file a2.sinks = avro113 #代表各个flume中channel的cx是针对该flume自定义的,这个和ax的定义规则不同 a2.channels = c1
#配置source # 2 source #bigdata112监控文件 a2.sources.tail-file.type = exec #文件所在的路径 a2.sources.tail-file.command =tail -F /opt/plus #监控的文件 a2.sources.tail-file.shell = /bin/bash -c
#配置sink # 3 sink -avro是用于flume之间的资源 a2.sinks.avro113.type = avro a2.sinks.avro113.hostname = bigdata113 #端口不能和之前的冲突-但要和一起扇入的其他sink端口一样 a2.sinks.avro113.port = 4141
#配置channel # 4 channel #存到内存-memory a2.channels.c1.type = memory #channel的大小 a2.channels.c1.capacity = 1000 #每次可以从channel拿出数据的多少 a2.channels.c1.transactionCapacity = 100
#连接source,channels # 5. Bind a2.sources.tail-file.channels = c1 a2.sinks.avro113.channel = c1 |
3.创建flume-3.conf,用于接收flume-1与flume-2发送过来的数据流,最终合并后sink到HDFS
|
# 1 agent a3.sources = r1 a3.sinks = k1 a3.channels = c1
# 2 source #和bigdata111是对应的-监控bigdata113的4141端点 #sources-avro是用于flume之间的资源 a3.sources.r1.type = avro a3.sources.r1.bind = bigdata113 a3.sources.r1.port = 4141
# 3 sink a3.sinks.k1.type = hdfs a3.sinks.k1.hdfs.path = hdfs://bigdata111:9000/flume3/%H #上传文件的前缀 a3.sinks.k1.hdfs.filePrefix = flume3- #是否按照时间滚动文件夹 a3.sinks.k1.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k1.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k1.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k1.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 #batchSize<=transactionCapacity<capacity a3.sinks.k1.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k1.hdfs.fileType = DataStream #多久生成一个新的文件 #如果设置成一个0,就不按时间进行滚动-一直往一个文件里写 a3.sinks.k1.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是128M a3.sinks.k1.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a3.sinks.k1.hdfs.rollCount = 0 #最小冗余数 a3.sinks.k1.hdfs.minBlockReplicas = 1
# 4 channel a3.channels.c1.type = memory a3.channels.c1.capacity = 1000 a3.channels.c1.transactionCapacity = 100
# 5 Bind a3.sources.r1.channels = c1 a3.sinks.k1.channel = c1 |
4.执行测试:分别开启对应flume-job(依次启动flume-3,flume-2,flume-1) , 同时产生文件变动并观察结果
|
$ bin/flume-ng agent --conf conf/ --name a3 --conf-file jobconf/flume33.conf $ bin/flume-ng agent --conf conf/ --name a2 --conf-file jobconf/flume22.conf $ bin/flume-ng agent --conf conf/ --name a1 --conf-file jobconf/flume11.conf |
数据发送:
|
1) 打开端口telnet bigdata111 55555 打开后发送5555555 2) 在/opt/Andy 中追加666666 |
5.实践过程、结果分析
1) 这里开启了zookeeper、HDFS-HA服务(其实开完全分布式,不开HA的也可以,只要上传到active的namenode节点所在的HDFS即可)
[root@bigdata111 ~]# zkServer.sh start(三台同步)
[root@bigdata111 ~]# cd /opt/module/HA/hadoop-2.8.4/
[root@bigdata111 hadoop-2.8.4]# sbin/start-dfs.sh(仅一台)
查看进程:
[root@bigdata111 hadoop-2.8.4]# jps
2741 JournalNode
2278 QuorumPeerMain
2438 NameNode
2918 DFSZKFailoverController
3001 Jps
2542 DataNode
[root@bigdata112 ~]# jps
2416 DataNode
2276 QuorumPeerMain
2357 NameNode
2709 Jps
2614 DFSZKFailoverController
2526 JournalNode
[root@bigdata113 ~]# jps
2277 QuorumPeerMain
2441 JournalNode
2364 DataNode
2525 Jps
2) bigdata111中,创建配置文件并填入配置:
[root@bigdata111 myconf]# vi flume-1.conf
3) bigdata112、bigdata113中,创建配置文件并填入配置、给flume配置环境变量(就不用在bin目录下启动啥的了):
(1)先往bigdata112、bigdata113上上传flume相关的文件夹(如果有就不用),并删除myconf里面的flume-1.conf文件。
[root@bigdata111 module]# scp -r flume-1.8.0/ root@bigdata112:/opt/module/
[root@bigdata112 myconf]# rm flume-1.conf
[root@bigdata113 myconf]# rm flume-1.conf
(2)往bigdata112上创建文件并填入配置-和flume-2.conf里的内容差不太多
[root@bigdata112 myconf]# vi flume-2.conf
(3)往bigdata113上创建文件并填入配置
[root@bigdata113 myconf]# vi flume-3.conf
(4)配置环境变量--bigdata112和bigdata113同步
[root@bigdata112 myconf]# vi /etc/profile
#FLUME_HOME
export FLUME_HOME=/opt/module/flume-1.8.0/
export PATH=$PATH:$FLUME_HOME/bin
(5)然后别忘了使环境变量生效--也是bigdata112和bigdata113同步
[root@bigdata112 myconf]# source /etc/profile
4) 启动配置文件
(1) 先启动bigdata111上的flume
[root@bigdata111 myconf]# flume-ng agent --conf ../conf/ --name a1 --conf-file flume-1.conf -Dflume.root.logger==INFO,console
查看日志,会发现“拒绝连接”:
Connection refused: bigdata113/192.168.212.113:4141
这是因为此时的bigdata113还未启动
(2) 接着启动bigdata112的flume
[root@bigdata112 myconf]# flume-ng agent -c ../conf/ -n a2 -f flume-2.conf -Dflume.root.logger==INFO,console
查看日志,也会发现“拒绝连接”:
Connection refused: bigdata113/192.168.212.113:4141
(3) 接着启动bigdata113的flume
[root@bigdata113 myconf]# flume-ng agent -c ../conf/ -n a3 -f flume-3.conf -Dflume.root.logger==INFO,console
5) 传数据,监控
(1) 监控bigdata111的55555端口、传入数据并查看监控结果
[root@bigdata111 ~]# telnet bigdata111 55555
Trying 192.168.212.111...
Connected to bigdata111.
Escape character is '^]'.
1111111111111111111111
OK
1111111111111111111111
OK
监控结果如下:

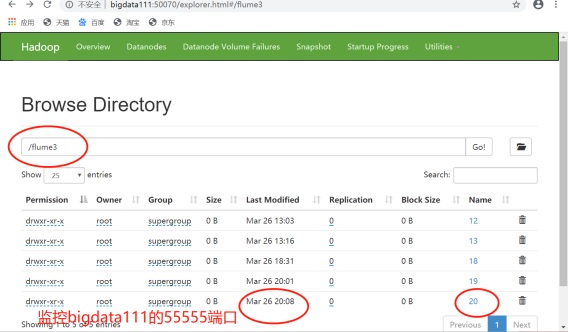
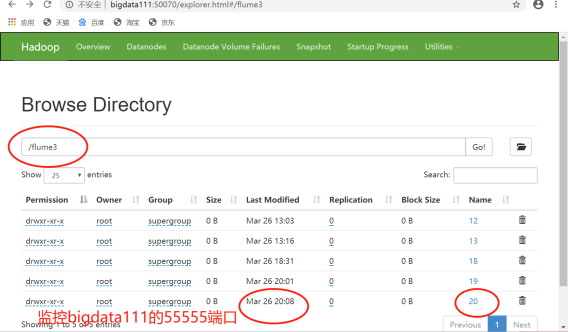
这表明:bigdata113的flume可以收到bigdata111通过检测55555端口传来的数据。
(2) 在bigdata112上监控指定的文件
- 输入命令行的形式查看plus文件的内容-查看监控结果:
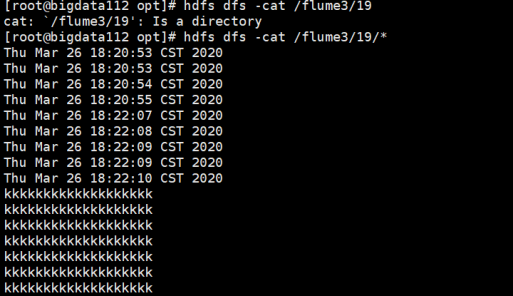
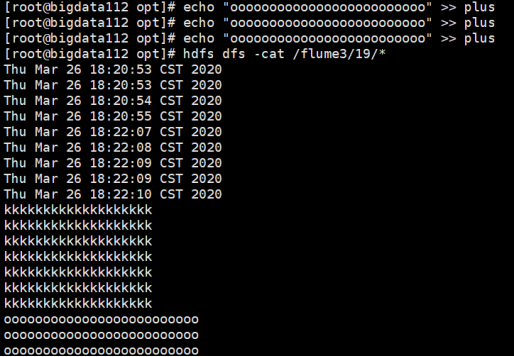
- 查看Web页面方式:
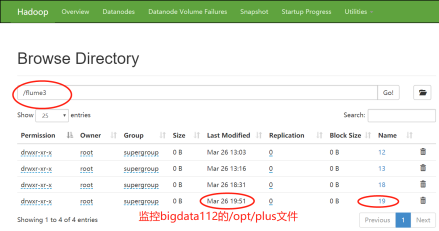
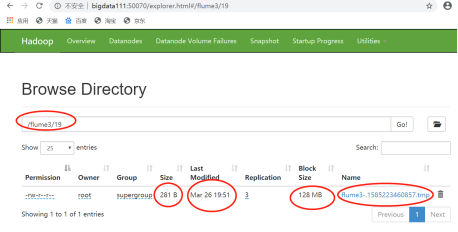
这表明:bigdata113的flume也可以接收到bigdata112的flume传过来的数据。
(3) 接下来,同一时间段--将bigdata111从55555端口监控得来的数据和bigdata112监控/opt/plus文件得来的数据汇总到bigdata113。
- 先往bigdata111的55555端口发送数据:
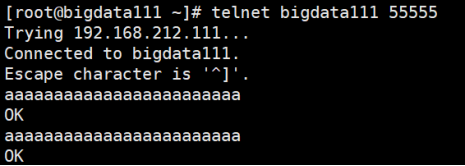
- 再向bigdata112的/opt/plus文件里追加数据:
![]()
- 命令行方式查看HDFS上的目录20中所有文件的内容:
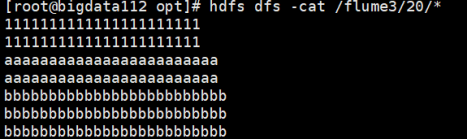
- Web端查看生成的文件:

- 分析:
20这个目录下面的所有文件的内容中:
两行都是“1”的内容是之前也在20这个时间段上发送的数据;
下面两行都是“a”的内容就是刚才从55555端口新上传的数据;
最后三行都是“b”的内容就是刚才新追加到/opt/plus文件的数据。
Flume中的Source源可以帮助打开端口-这里的4141。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号