
案例三:实时读取目录文件到HDFS
目标:使用flume监听整个目录的文件
分步实现:
1.创建配置文件flume-dir.conf
|
#1 Agent a3.sources = r3 a3.sinks = k3 a3.channels = c3
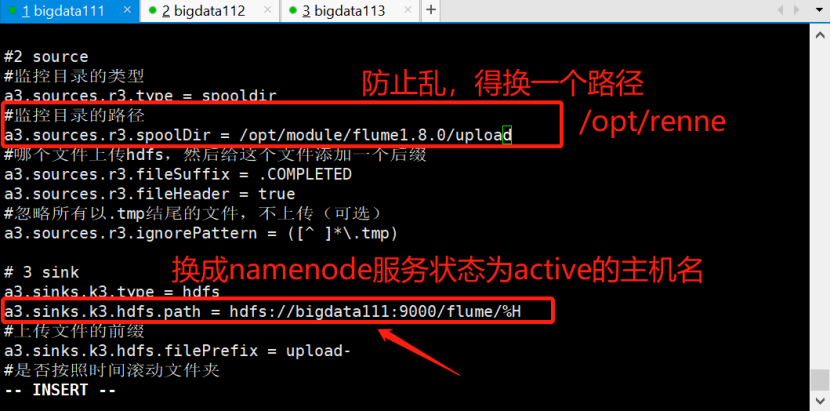
#2 source #监控目录的类型 a3.sources.r3.type = spooldir #监控目录的路径-自定义 a3.sources.r3.spoolDir = /opt/renne #哪个文件上传hdfs,然后给这个文件添加一个后缀 a3.sources.r3.fileSuffix = .COMPLETED a3.sources.r3.fileHeader = true #忽略所有以.tmp结尾的文件,不上传(可选) a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# 3 sink a3.sinks.k3.type = hdfs a3.sinks.k3.hdfs.path = hdfs://bigdata111:9000/flume/%H #上传文件的前缀 a3.sinks.k3.hdfs.filePrefix = upload- #是否按照时间滚动文件夹 a3.sinks.k3.hdfs.round = true #多少时间单位创建一个新的文件夹 a3.sinks.k3.hdfs.roundValue = 1 #重新定义时间单位 a3.sinks.k3.hdfs.roundUnit = hour #是否使用本地时间戳 a3.sinks.k3.hdfs.useLocalTimeStamp = true #积攒多少个Event才flush到HDFS一次 a3.sinks.k3.hdfs.batchSize = 100 #设置文件类型,可支持压缩 a3.sinks.k3.hdfs.fileType = DataStream #多久生成一个新的文件 a3.sinks.k3.hdfs.rollInterval = 600 #设置每个文件的滚动大小大概是128M a3.sinks.k3.hdfs.rollSize = 134217700 #文件的滚动与Event数量无关 a3.sinks.k3.hdfs.rollCount = 0 #最小副本数 a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory a3.channels.c3.type = memory a3.channels.c3.capacity = 1000 a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel a3.sources.r3.channels = c3 a3.sinks.k3.channel = c3 |
2.执行测试
执行如下脚本后,请向/opt/renne文件夹中添加文件试试
|
/opt/module/flume1.8.0/bin/flume-ng agent \ --conf /opt/module/flume1.8.0/conf/ \ --name a3 \ --conf-file /opt/module/flume1.8.0/jobconf/flume-dir.conf |
尖叫提示: 在使用Spooling Directory Source时
1) 不要在监控目录中创建并持续修改文件
2) 上传完成的文件会以.COMPLETED结尾
3) 被监控文件夹每500毫秒扫描一次文件变动
3.实践过程、结果分析
本次实验前先开启HDFS-HA服务(当然用完全分布式也可,HA是保证能够转移故障节点)
1) 启动HA之前,需要启动Zookeeper(三台都启动)
[root@bigdata112 ~]# zkServer.sh start
注意:active是谁和是否为leader无关
2) 启动HDFS-HA服务
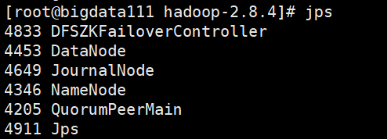
3)查看namenode1服务器状态
![]()
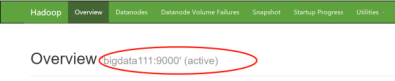
也可查看Web端:

4)配置flume文件
[root@bigdata111 myconf]# vi flume-dir.conf
5)保存离开之后记得创建要监控的目录/opt/renne
[root@bigdata111 opt]# mv plus renne/
[root@bigdata111 opt]# cd renne/
[root@bigdata111 renne]# ls
plus
现在在renne这个目录下创建一个文件并随意添些东西、并复制到多个文件中
[root@bigdata111 renne]# vi renne-a
[root@bigdata111 renne]# cp renne-a renne-b
[root@bigdata111 renne]# cp renne-a renne-c
[root@bigdata111 renne]# cp renne-a renne-d
[root@bigdata111 renne]# cp renne-a renne-e
[root@bigdata111 renne]# ls
plus renne-a renne-b renne-c renne-d renne-e
6)启动
[root@bigdata111 bin]#flume-ng agent --conf ../conf/ --name a3 --conf-file ../myconf/flume-dir.conf
7)查看结果
(1)对于上传到HDFS里的文件,会加上.COMPLETED的后缀表明已经上传
[root@bigdata111 opt]# cd renne/
[root@bigdata111 renne]# ll
total 24
-rw-r--r-- 1 root root 3493 Mar 24 23:51 plus.COMPLETED
-rw-r--r-- 1 root root 33 Mar 25 11:58 renne-a.COMPLETED
-rw-r--r-- 1 root root 33 Mar 25 11:59 renne-b.COMPLETED
-rw-r--r-- 1 root root 33 Mar 25 11:59 renne-c.COMPLETED
-rw-r--r-- 1 root root 33 Mar 25 11:59 renne-d.COMPLETED
-rw-r--r-- 1 root root 33 Mar 25 11:59 renne-e.COMPLETED
(2)Web端:
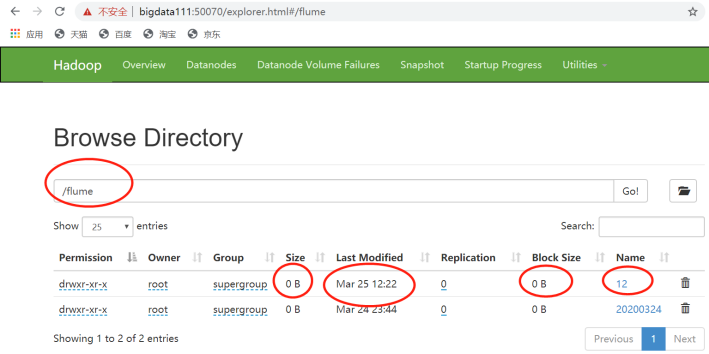
12:22分,文件开始上传,监控开始
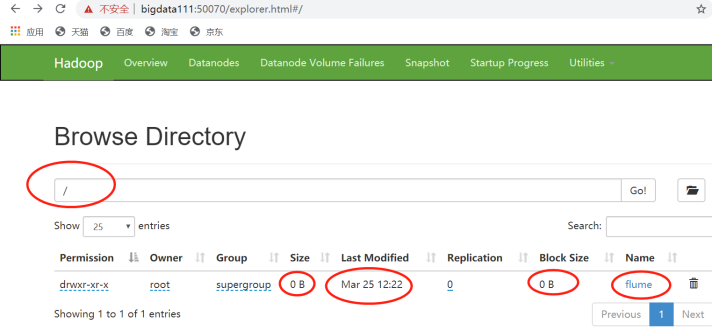
上传的是以“小时”为名的目录
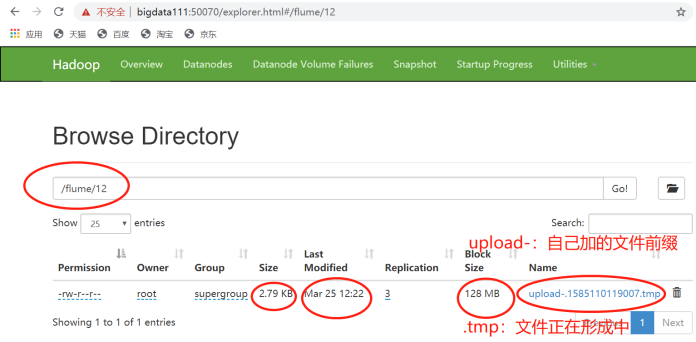
在12这个目录里,有正在上传的文件,未到600秒,它还没形成完毕。
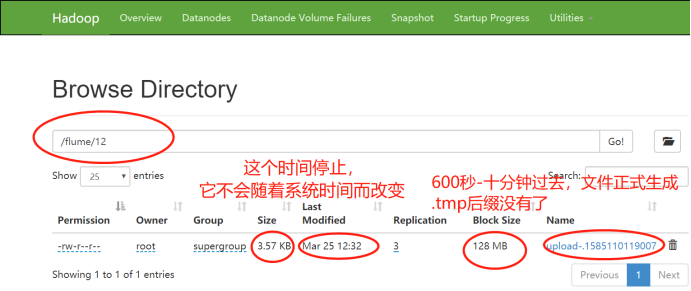
12:32分,十分钟过去,文件正式生成。
4.思考-今后使用时要注意
如果数据量很大,需要修改channel也要调大:a3.channels.c3.capacity = 1000
Flume里面监控文件:一个event会监控一行日志,一个event默认最大值是2048B,如果超过就会切分,可以进行修改,将event调大。
参考随笔:https://www.cnblogs.com/liuxinrong/p/12607397.html
数据量很大,也可以采用多台flume,还可以结合Kafka。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号